 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDNN-GDITD: Out-of-distribution detection via Deep Neural Network based Gaussian Descriptor for Imbalanced Tabular Data
Sep 04, 2024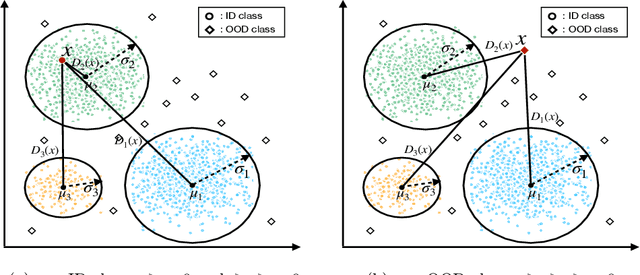
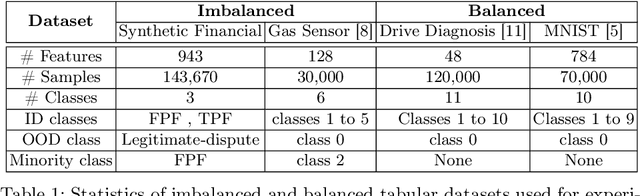

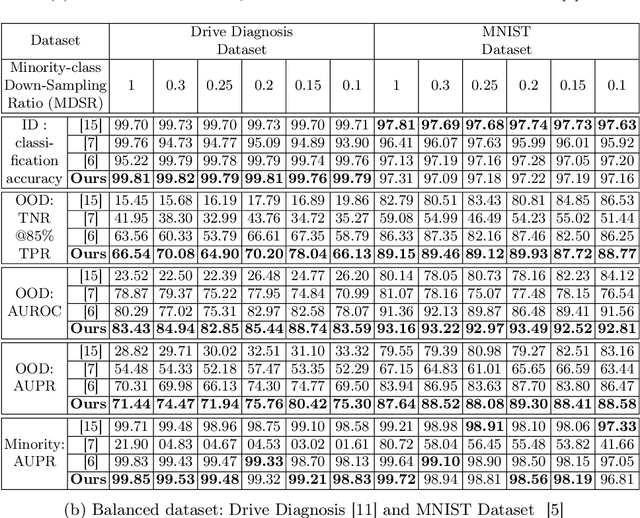
Classification tasks present challenges due to class imbalances and evolving data distributions. Addressing these issues requires a robust method to handle imbalances while effectively detecting out-of-distribution (OOD) samples not encountered during training. This study introduces a novel OOD detection algorithm designed for tabular datasets, titled Deep Neural Network-based Gaussian Descriptor for Imbalanced Tabular Data (DNN-GDITD). The DNN-GDITD algorithm can be placed on top of any DNN to facilitate better classification of imbalanced data and OOD detection using spherical decision boundaries. Using a combination of Push, Score-based, and focal losses, DNN-GDITD assigns confidence scores to test data points, categorizing them as known classes or as an OOD sample. Extensive experimentation on tabular datasets demonstrates the effectiveness of DNN-GDITD compared to three OOD algorithms. Evaluation encompasses imbalanced and balanced scenarios on diverse tabular datasets, including a synthetic financial dispute dataset and publicly available tabular datasets like Gas Sensor, Drive Diagnosis, and MNIST, showcasing DNN-GDITD's versatility.
Entity Alignment For Knowledge Graphs: Progress, Challenges, and Empirical Studies
May 18, 2022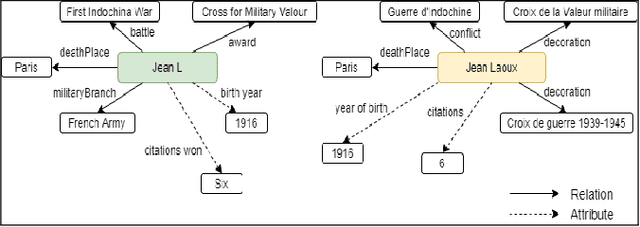
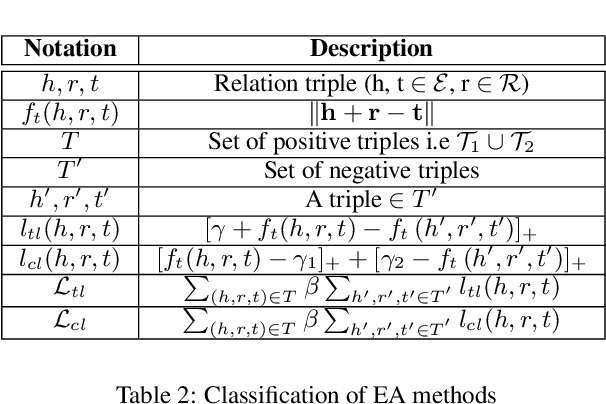
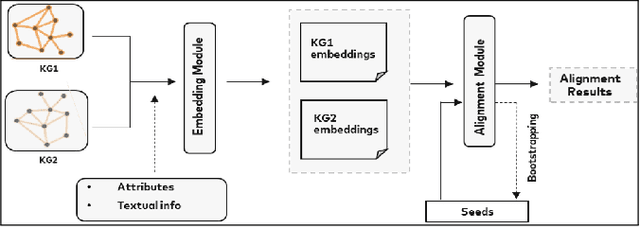
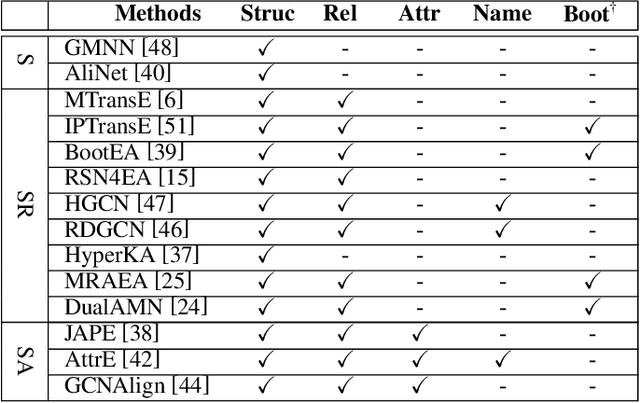
Entity Alignment (EA) identifies entities across databases that refer to the same entity. Knowledge graph-based embedding methods have recently dominated EA techniques. Such methods map entities to a low-dimension space and align them based on their similarities. With the corpus of EA methodologies growing rapidly, this paper presents a comprehensive analysis of various existing EA methods, elaborating their applications and limitations. Further, we distinguish the methods based on their underlying algorithms and the information they incorporate to learn entity representations. Based on challenges in industrial datasets, we bring forward $4$ research questions (RQs). These RQs empirically analyse the algorithms from the perspective of \textit{Hubness, Degree distribution, Non-isomorphic neighbourhood,} and \textit{Name bias}. For Hubness, where one entity turns up as the nearest neighbour of many other entities, we define an $h$-score to quantify its effect on the performance of various algorithms. Additionally, we try to level the playing field for algorithms that rely primarily on name-bias existing in the benchmarking open-source datasets by creating a low name bias dataset. We further create an open-source repository for $14$ embedding-based EA methods and present the analysis for invoking further research motivations in the field of EA.
A Reinforcement Learning Environment for Mathematical Reasoning via Program Synthesis
Jul 16, 2021

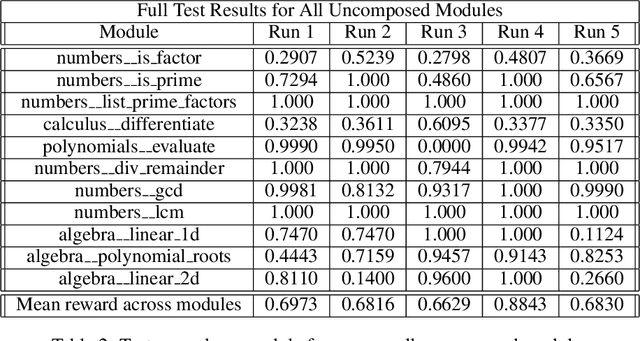
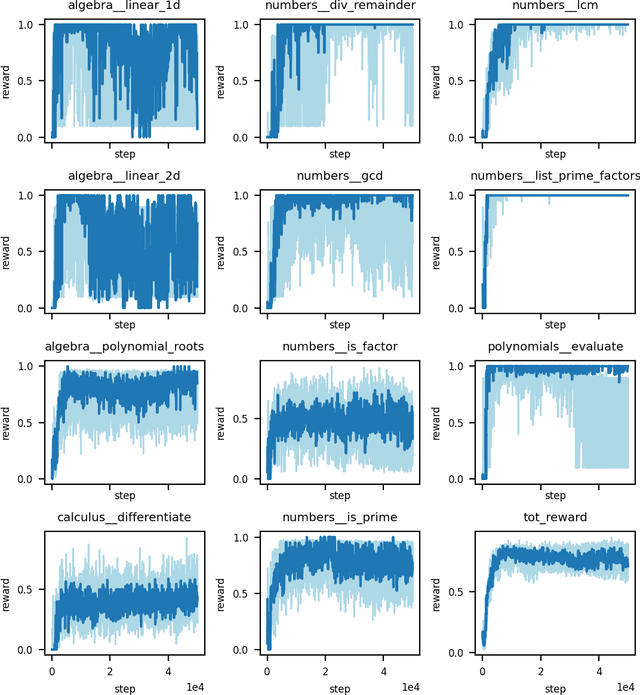
We convert the DeepMind Mathematics Dataset into a reinforcement learning environment by interpreting it as a program synthesis problem. Each action taken in the environment adds an operator or an input into a discrete compute graph. Graphs which compute correct answers yield positive reward, enabling the optimization of a policy to construct compute graphs conditioned on problem statements. Baseline models are trained using Double DQN on various subsets of problem types, demonstrating the capability to learn to correctly construct graphs despite the challenges of combinatorial explosion and noisy rewards.
A Comprehensive Review on Recent Methods and Challenges of Video Description
Nov 30, 2020
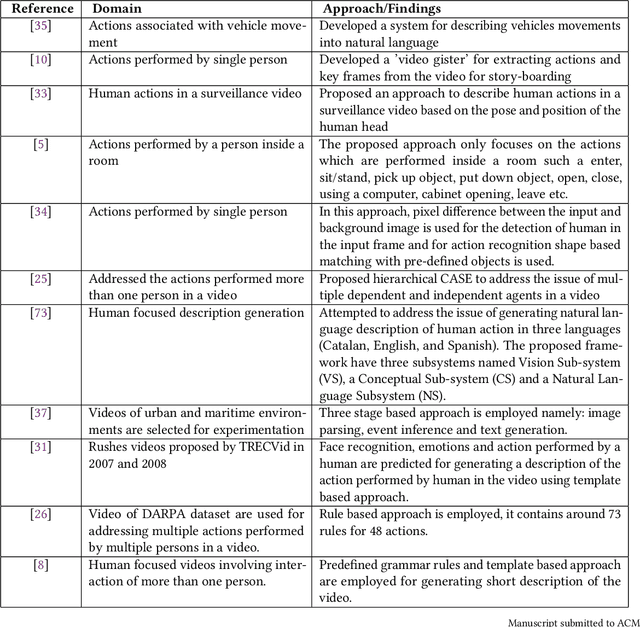
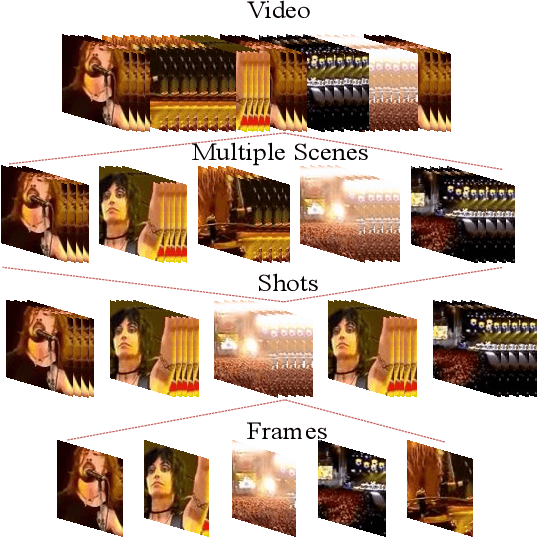
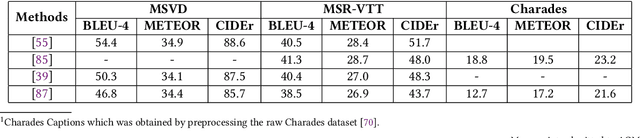
Video description involves the generation of the natural language description of actions, events, and objects in the video. There are various applications of video description by filling the gap between languages and vision for visually impaired people, generating automatic title suggestion based on content, browsing of the video based on the content and video-guided machine translation [86] etc.In the past decade, several works had been done in this field in terms of approaches/methods for video description, evaluation metrics,and datasets. For analyzing the progress in the video description task, a comprehensive survey is needed that covers all the phases of video description approaches with a special focus on recent deep learning approaches. In this work, we report a comprehensive survey on the phases of video description approaches, the dataset for video description, evaluation metrics, open competitions for motivating the research on the video description, open challenges in this field, and future research directions. In this survey, we cover the state-of-the-art approaches proposed for each and every dataset with their pros and cons. For the growth of this research domain,the availability of numerous benchmark dataset is a basic need. Further, we categorize all the dataset into two classes: open domain dataset and domain-specific dataset. From our survey, we observe that the work in this field is in fast-paced development since the task of video description falls in the intersection of computer vision and natural language processing. But still, the work in the video description is far from saturation stage due to various challenges like the redundancy due to similar frames which affect the quality of visual features, the availability of dataset containing more diverse content and availability of an effective evaluation metric.
NITS-VC System for VATEX Video Captioning Challenge 2020
Jun 07, 2020


Video captioning is process of summarising the content, event and action of the video into a short textual form which can be helpful in many research areas such as video guided machine translation, video sentiment analysis and providing aid to needy individual. In this paper, a system description of the framework used for VATEX-2020 video captioning challenge is presented. We employ an encoder-decoder based approach in which the visual features of the video are encoded using 3D convolutional neural network (C3D) and in the decoding phase two Long Short Term Memory (LSTM) recurrent networks are used in which visual features and input captions are fused separately and final output is generated by performing element-wise product between the output of both LSTMs. Our model is able to achieve BLEU scores of 0.20 and 0.22 on public and private test data sets respectively.
Detecting Spiky Corruption in Markov Decision Processes
Jun 30, 2019

Current reinforcement learning methods fail if the reward function is imperfect, i.e. if the agent observes reward different from what it actually receives. We study this problem within the formalism of Corrupt Reward Markov Decision Processes (CRMDPs). We show that if the reward corruption in a CRMDP is sufficiently "spiky", the environment is solvable. We fully characterize the regret bound of a Spiky CRMDP, and introduce an algorithm that is able to detect its corrupt states. We show that this algorithm can be used to learn the optimal policy with any common reinforcement learning algorithm. Finally, we investigate our algorithm in a pair of simple gridworld environments, finding that our algorithm can detect the corrupt states and learn the optimal policy despite the corruption.
Deep Learning on Operational Facility Data Related to Large-Scale Distributed Area Scientific Workflows
Apr 20, 2018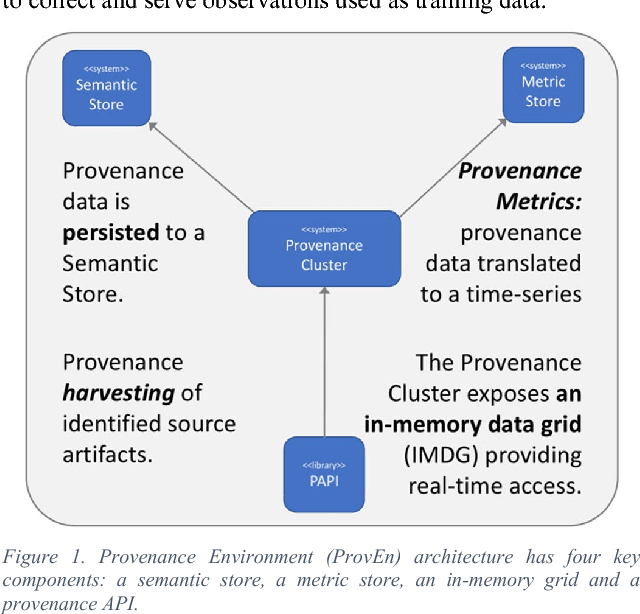

Distributed computing platforms provide a robust mechanism to perform large-scale computations by splitting the task and data among multiple locations, possibly located thousands of miles apart geographically. Although such distribution of resources can lead to benefits, it also comes with its associated problems such as rampant duplication of file transfers increasing congestion, long job completion times, unexpected site crashing, suboptimal data transfer rates, unpredictable reliability in a time range, and suboptimal usage of storage elements. In addition, each sub-system becomes a potential failure node that can trigger system wide disruptions. In this vision paper, we outline our approach to leveraging Deep Learning algorithms to discover solutions to unique problems that arise in a system with computational infrastructure that is spread over a wide area. The presented vision, motivated by a real scientific use case from Belle II experiments, is to develop multilayer neural networks to tackle forecasting, anomaly detection and optimization challenges in a complex and distributed data movement environment. Through this vision based on Deep Learning principles, we aim to achieve reduced congestion events, faster file transfer rates, and enhanced site reliability.
Modular Resource Centric Learning for Workflow Performance Prediction
Apr 17, 2018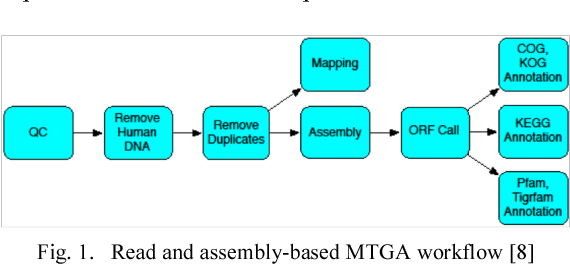
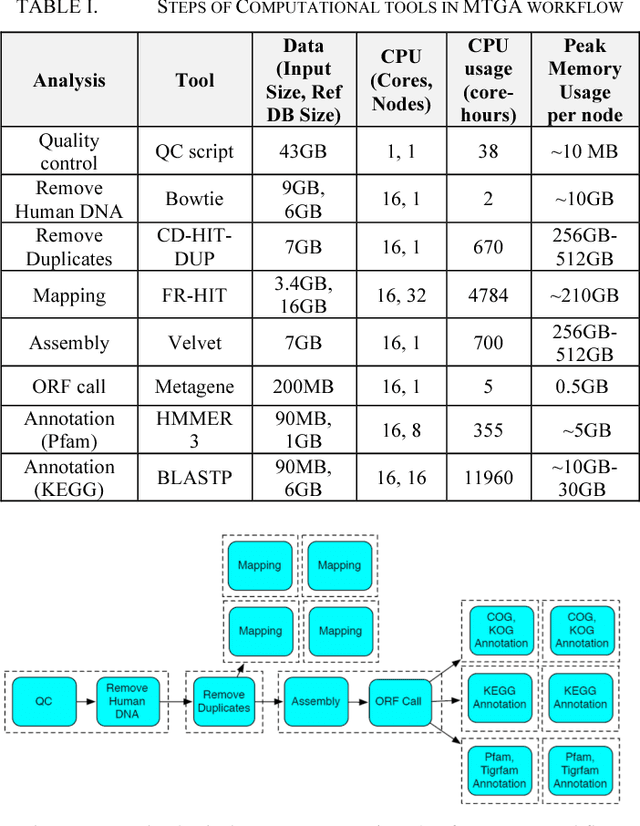
Workflows provide an expressive programming model for fine-grained control of large-scale applications in distributed computing environments. Accurate estimates of complex workflow execution metrics on large-scale machines have several key advantages. The performance of scheduling algorithms that rely on estimates of execution metrics degrades when the accuracy of predicted execution metrics decreases. This in-progress paper presents a technique being developed to improve the accuracy of predicted performance metrics of large-scale workflows on distributed platforms. The central idea of this work is to train resource-centric machine learning agents to capture complex relationships between a set of program instructions and their performance metrics when executed on a specific resource. This resource-centric view of a workflow exploits the fact that predicting execution times of sub-modules of a workflow requires monitoring and modeling of a few dynamic and static features. We transform the input workflow that is essentially a directed acyclic graph of actions into a Physical Resource Execution Plan (PREP). This transformation enables us to model an arbitrarily complex workflow as a set of simpler programs running on physical nodes. We delegate a machine learning model to capture performance metrics for each resource type when it executes different program instructions under varying degrees of resource contention. Our algorithm takes the prediction metrics from each resource agent and composes the overall workflow performance metrics by utilizing the structure of the corresponding Physical Resource Execution Plan.