 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFraud Type Decomposition and the Observation-Mechanism Taxonomy:Class-Specific Detection Limits in Payment Networks
May 29, 2026Fraud detection in payment networks relies on labels generated through heterogeneous and imperfect observation processes, yet existing approaches treat fraud as a homogeneous binary variable. We show that this assumption is structurally incorrect and leads to provable inefficiency. We introduce an observation-mechanism taxonomy that partitions fraud into five classes, each defined by a distinct censorship and labeling pipeline. We prove that estimating fraud rates separately by class and aggregating strictly dominates pooled estimation, with the efficiency gap characterized as a Jensen penalty arising from heterogeneous observation rates. For each class, we derive the binding theoretical constraint on detection, including endogenous label corruption, structural non-observability, and feature non-informativeness. These results establish that fraud detection is fundamentally a collection of distinct estimation problems, each governed by its own observation structure and detection limit.
Causal Label Recovery in Payment Networks
May 28, 2026Fraud detection models in payment networks train on chargeback labels that are systematically biased. Every label must survive three sequential gates: authorization (declined transactions generate no labels), issuer reporting (unreported fraud is invisible), and delay (pending chargebacks are missing at training time). Labels that do arrive may be corrupted by first-party misuse or issuer misclassification. A companion paper [arXiv:2605.27557] proved that these four impairments impose a minimax lower bound on detection performance. This paper asks: can that bound be achieved? We formalize the observation pipeline as a sequential missing-data problem with three propensity stages and a corruption layer, and construct the Sequential Triply Robust (STR) estimator. The STR corrects for all four impairments simultaneously and achieves the semiparametric efficiency bound -- no estimator can have lower asymptotic variance. It is sequentially triply robust: at each gate, consistency requires only that either the propensity model or the outcome regression is correctly specified, not both. We provide corruption correction via noise-rate-adjusted pseudo-labels, empirical Bayes shrinkage to stabilize inverse-propensity weights for small issuers, a plug-in variance estimator yielding valid confidence intervals, and a Bernstein concentration inequality for finite-sample guarantees. On the operational side, we derive the optimal training delay -- the maturity window that minimizes the sum of label-quality loss and model staleness -- and prove that the STR permits training on data that is days old rather than months old, decoupling model freshness from the chargeback maturity cycle. The STR provably dominates naive chargeback-based training in mean squared error for any sample size.
The Fundamental Limits of Fraud Detection in Card Payment Networks
May 26, 2026Card payment fraud detection is usually framed as a supervised classification problem. Although this approach has generated practical progress, improvement has remained incremental despite major advances in model architecture. We argue that this is not mainly a failure of function approximation or optimization, but a consequence of structural information impairments inherent to the payment ecosystem. We formalize card authorization as a sequential decision problem with delayed, censored, corrupted, and counterfactually missing feedback. We derive a minimax regret lower bound showing that these impairments enter multiplicatively in the denominator of the achievable learning rate. The bound implies that improving issuer reporting quality or reducing censorship can yield larger reductions in the regret floor than increasing model complexity. We also show that heterogeneity across issuers worsens learnability beyond what average impairment rates suggest. The paper contributes a theory of why fraud detection in payment networks is fundamentally harder than in standard online learning settings, identifies ecosystem information quality as the key bottleneck, and provides a theoretical basis for prioritizing investments in reporting infrastructure, dispute process quality, and selective exploration. The paper is theory-first and does not rely on proprietary transaction data.
Entity Alignment For Knowledge Graphs: Progress, Challenges, and Empirical Studies
May 18, 2022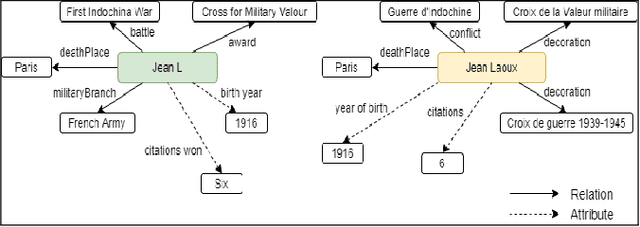
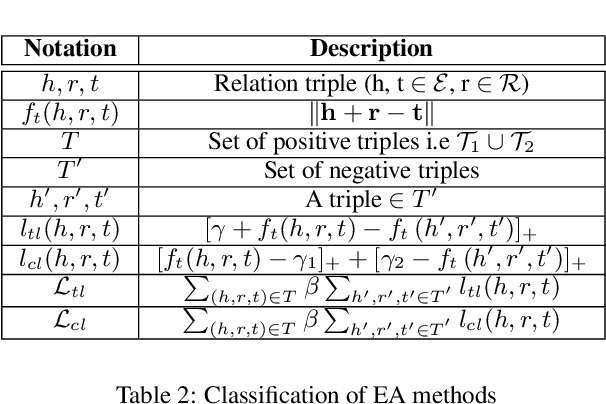
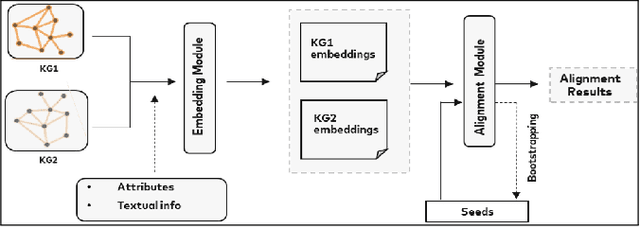
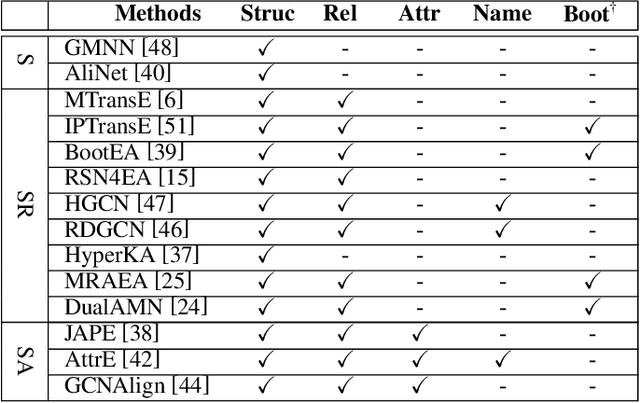
Entity Alignment (EA) identifies entities across databases that refer to the same entity. Knowledge graph-based embedding methods have recently dominated EA techniques. Such methods map entities to a low-dimension space and align them based on their similarities. With the corpus of EA methodologies growing rapidly, this paper presents a comprehensive analysis of various existing EA methods, elaborating their applications and limitations. Further, we distinguish the methods based on their underlying algorithms and the information they incorporate to learn entity representations. Based on challenges in industrial datasets, we bring forward $4$ research questions (RQs). These RQs empirically analyse the algorithms from the perspective of \textit{Hubness, Degree distribution, Non-isomorphic neighbourhood,} and \textit{Name bias}. For Hubness, where one entity turns up as the nearest neighbour of many other entities, we define an $h$-score to quantify its effect on the performance of various algorithms. Additionally, we try to level the playing field for algorithms that rely primarily on name-bias existing in the benchmarking open-source datasets by creating a low name bias dataset. We further create an open-source repository for $14$ embedding-based EA methods and present the analysis for invoking further research motivations in the field of EA.
Dynamic Temporal Reconciliation by Reinforcement learning
Jan 28, 2022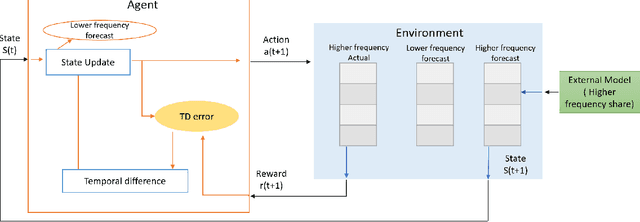
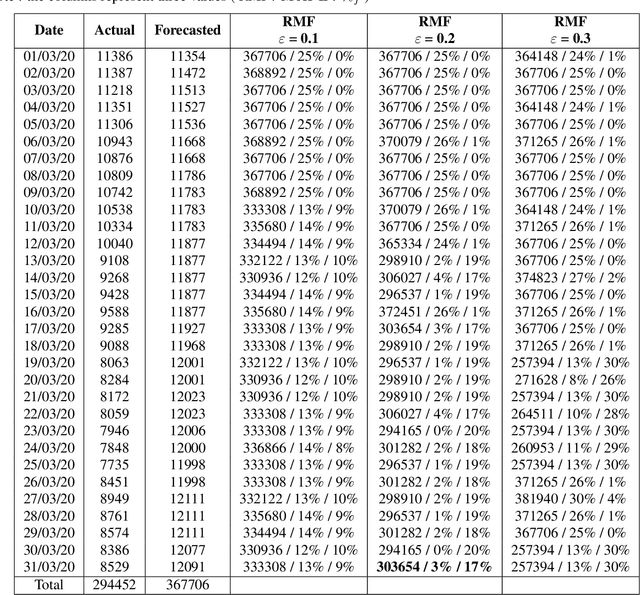
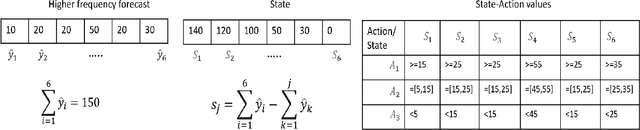

Planning based on long and short term time series forecasts is a common practice across many industries. In this context, temporal aggregation and reconciliation techniques have been useful in improving forecasts, reducing model uncertainty, and providing a coherent forecast across different time horizons. However, an underlying assumption spanning all these techniques is the complete availability of data across all levels of the temporal hierarchy, while this offers mathematical convenience but most of the time low frequency data is partially completed and it is not available while forecasting. On the other hand, high frequency data can significantly change in a scenario like the COVID pandemic and this change can be used to improve forecasts that will otherwise significantly diverge from long term actuals. We propose a dynamic reconciliation method whereby we formulate the problem of informing low frequency forecasts based on high frequency actuals as a Markov Decision Process (MDP) allowing for the fact that we do not have complete information about the dynamics of the process. This allows us to have the best long term estimates based on the most recent data available even if the low frequency cycles have only been partially completed. The MDP has been solved using a Time Differenced Reinforcement learning (TDRL) approach with customizable actions and improves the long terms forecasts dramatically as compared to relying solely on historical low frequency data. The result also underscores the fact that while low frequency forecasts can improve the high frequency forecasts as mentioned in the temporal reconciliation literature (based on the assumption that low frequency forecasts have lower noise to signal ratio) the high frequency forecasts can also be used to inform the low frequency forecasts.
Optimal Latent Space Forecasting for Large Collections of Short Time Series Using Temporal Matrix Factorization
Dec 15, 2021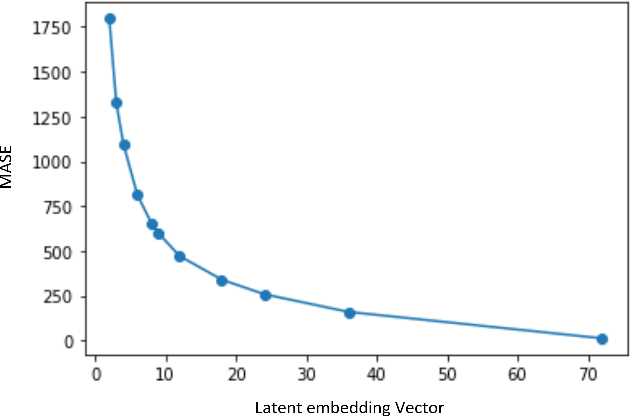
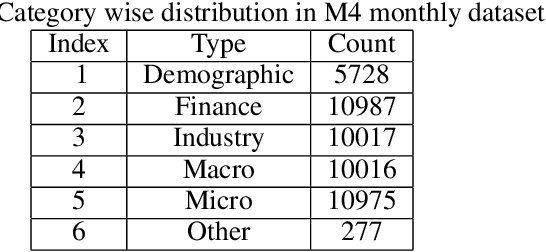
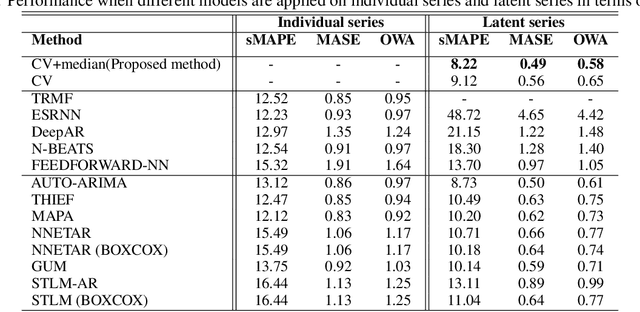
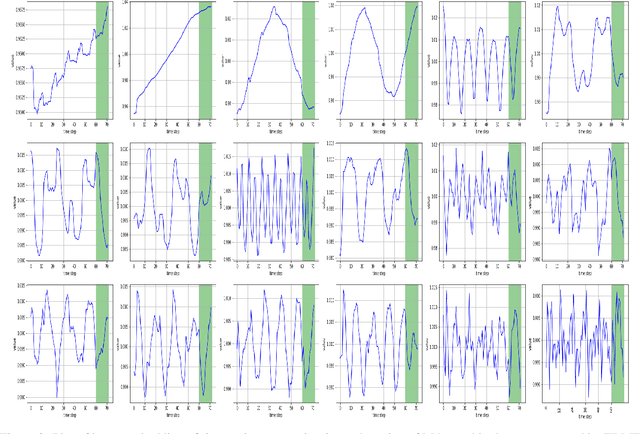
In the context of time series forecasting, it is a common practice to evaluate multiple methods and choose one of these methods or an ensemble for producing the best forecasts. However, choosing among different ensembles over multiple methods remains a challenging task that undergoes a combinatorial explosion as the number of methods increases. In the context of demand forecasting or revenue forecasting, this challenge is further exacerbated by a large number of time series as well as limited historical data points available due to changing business context. Although deep learning forecasting methods aim to simultaneously forecast large collections of time series, they become challenging to apply in such scenarios due to the limited history available and might not yield desirable results. We propose a framework for forecasting short high-dimensional time series data by combining low-rank temporal matrix factorization and optimal model selection on latent time series using cross-validation. We demonstrate that forecasting the latent factors leads to significant performance gains as compared to directly applying different uni-variate models on time series. Performance has been validated on a truncated version of the M4 monthly dataset which contains time series data from multiple domains showing the general applicability of the method. Moreover, it is amenable to incorporating the analyst view of the future owing to the low number of latent factors which is usually impractical when applying forecasting methods directly to high dimensional datasets.
Application of Deep Reinforcement Learning to Payment Fraud
Dec 08, 2021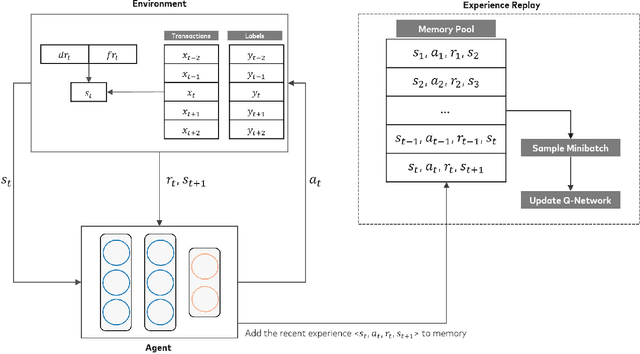
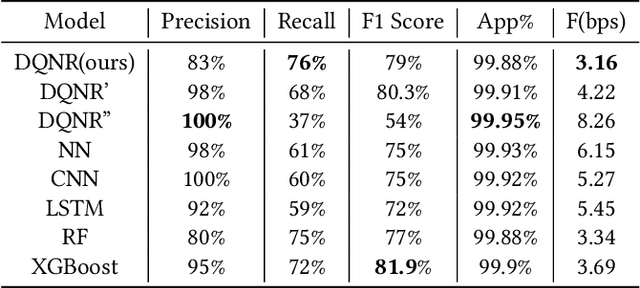
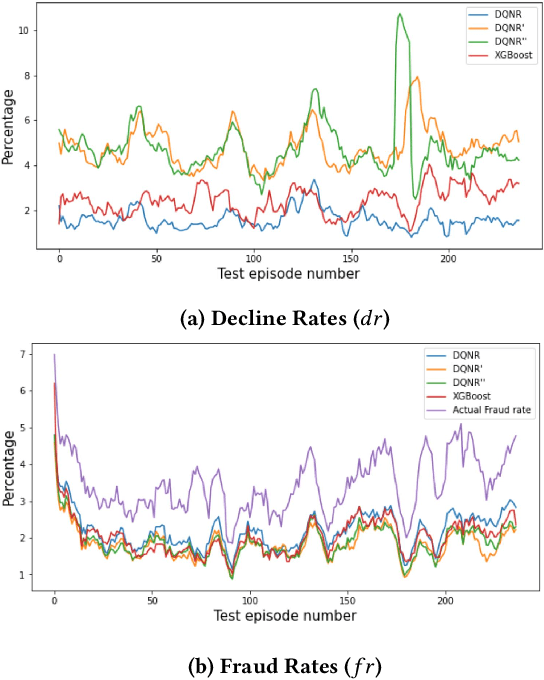
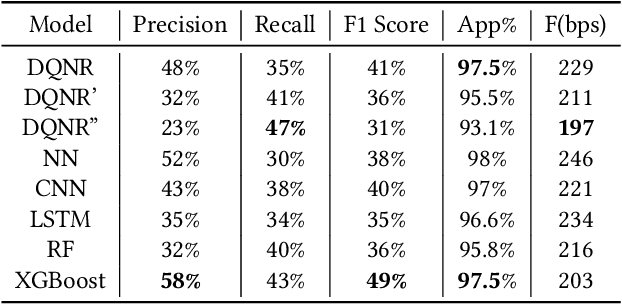
The large variety of digital payment choices available to consumers today has been a key driver of e-commerce transactions in the past decade. Unfortunately, this has also given rise to cybercriminals and fraudsters who are constantly looking for vulnerabilities in these systems by deploying increasingly sophisticated fraud attacks. A typical fraud detection system employs standard supervised learning methods where the focus is on maximizing the fraud recall rate. However, we argue that such a formulation can lead to sub-optimal solutions. The design requirements for these fraud models requires that they are robust to the high-class imbalance in the data, adaptive to changes in fraud patterns, maintain a balance between the fraud rate and the decline rate to maximize revenue, and be amenable to asynchronous feedback since usually there is a significant lag between the transaction and the fraud realization. To achieve this, we formulate fraud detection as a sequential decision-making problem by including the utility maximization within the model in the form of the reward function. The historical decline rate and fraud rate define the state of the system with a binary action space composed of approving or declining the transaction. In this study, we primarily focus on utility maximization and explore different reward functions to this end. The performance of the proposed Reinforcement Learning system has been evaluated for two publicly available fraud datasets using Deep Q-learning and compared with different classifiers. We aim to address the rest of the issues in future work.
KARL-Trans-NER: Knowledge Aware Representation Learning for Named Entity Recognition using Transformers
Nov 30, 2021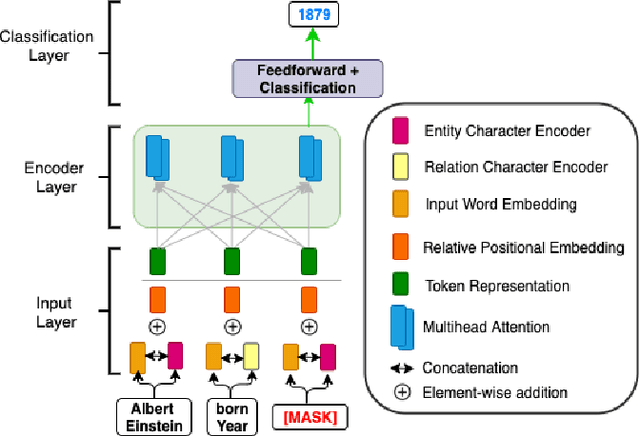
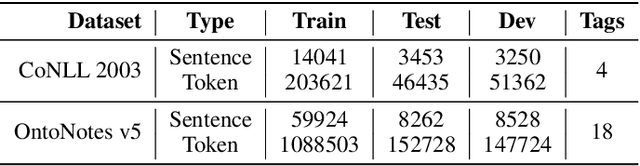
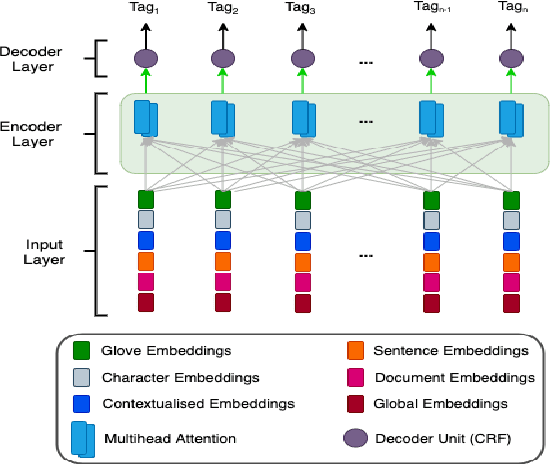
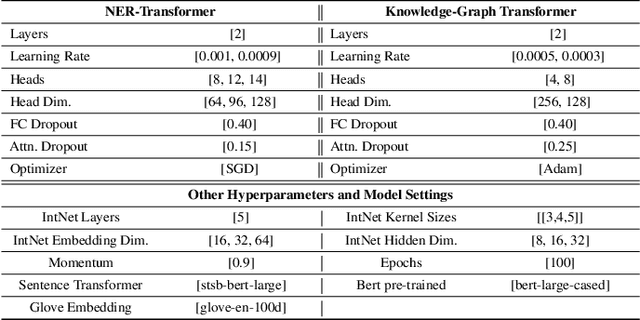
The inception of modeling contextual information using models such as BERT, ELMo, and Flair has significantly improved representation learning for words. It has also given SOTA results in almost every NLP task - Machine Translation, Text Summarization and Named Entity Recognition, to name a few. In this work, in addition to using these dominant context-aware representations, we propose a Knowledge Aware Representation Learning (KARL) Network for Named Entity Recognition (NER). We discuss the challenges of using existing methods in incorporating world knowledge for NER and show how our proposed methods could be leveraged to overcome those challenges. KARL is based on a Transformer Encoder that utilizes large knowledge bases represented as fact triplets, converts them to a graph context, and extracts essential entity information residing inside to generate contextualized triplet representation for feature augmentation. Experimental results show that the augmentation done using KARL can considerably boost the performance of our NER system and achieve significantly better results than existing approaches in the literature on three publicly available NER datasets, namely CoNLL 2003, CoNLL++, and OntoNotes v5. We also observe better generalization and application to a real-world setting from KARL on unseen entities.
A Comparative Study of Transformers on Word Sense Disambiguation
Nov 30, 2021
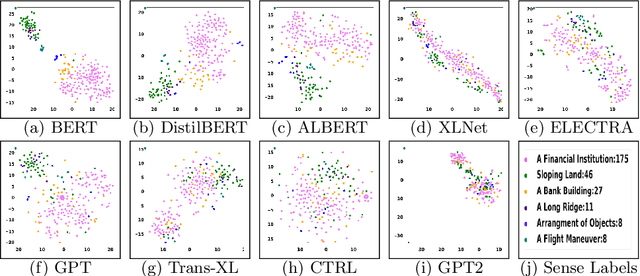
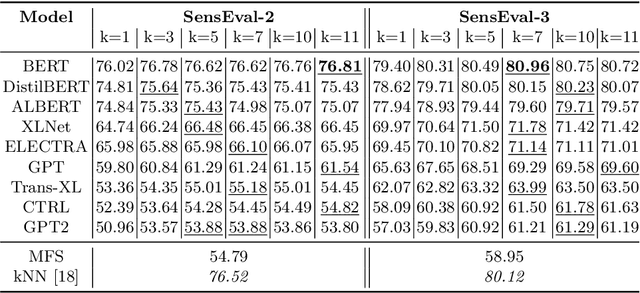
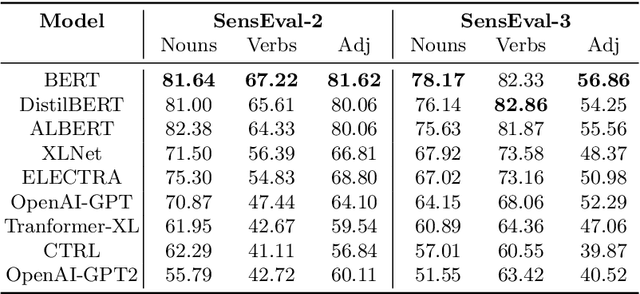
Recent years of research in Natural Language Processing (NLP) have witnessed dramatic growth in training large models for generating context-aware language representations. In this regard, numerous NLP systems have leveraged the power of neural network-based architectures to incorporate sense information in embeddings, resulting in Contextualized Word Embeddings (CWEs). Despite this progress, the NLP community has not witnessed any significant work performing a comparative study on the contextualization power of such architectures. This paper presents a comparative study and an extensive analysis of nine widely adopted Transformer models. These models are BERT, CTRL, DistilBERT, OpenAI-GPT, OpenAI-GPT2, Transformer-XL, XLNet, ELECTRA, and ALBERT. We evaluate their contextualization power using two lexical sample Word Sense Disambiguation (WSD) tasks, SensEval-2 and SensEval-3. We adopt a simple yet effective approach to WSD that uses a k-Nearest Neighbor (kNN) classification on CWEs. Experimental results show that the proposed techniques also achieve superior results over the current state-of-the-art on both the WSD tasks