 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti Document Reading Comprehension
Jan 05, 2022
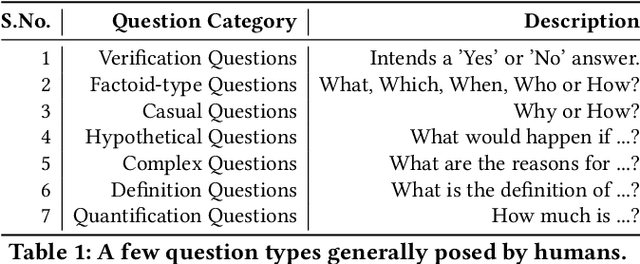

Reading Comprehension (RC) is a task of answering a question from a given passage or a set of passages. In the case of multiple passages, the task is to find the best possible answer to the question. Recent trials and experiments in the field of Natural Language Processing (NLP) have proved that machines can be provided with the ability to not only process the text in the passage and understand its meaning to answer the question from the passage, but also can surpass the Human Performance on many datasets such as Standford's Question Answering Dataset (SQuAD). This paper presents a study on Reading Comprehension and its evolution in Natural Language Processing over the past few decades. We shall also study how the task of Single Document Reading Comprehension acts as a building block for our Multi-Document Reading Comprehension System. In the latter half of the paper, we'll be studying about a recently proposed model for Multi-Document Reading Comprehension - RE3QA that is comprised of a Reader, Retriever, and a Re-ranker based network to fetch the best possible answer from a given set of passages.
KARL-Trans-NER: Knowledge Aware Representation Learning for Named Entity Recognition using Transformers
Nov 30, 2021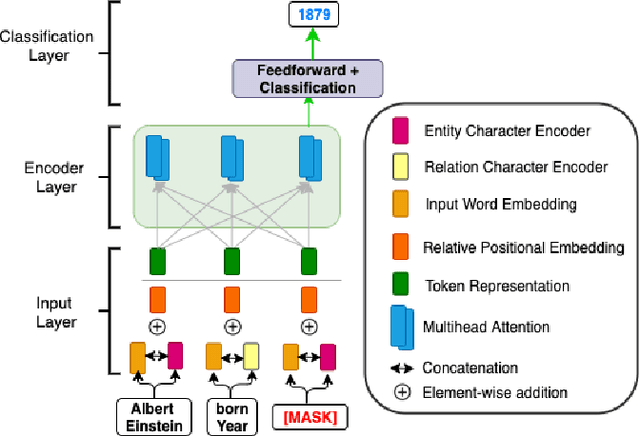
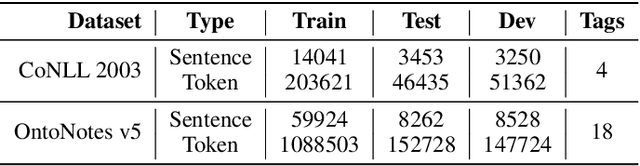
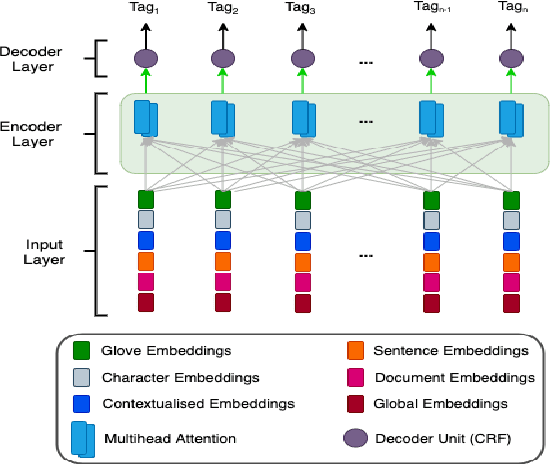
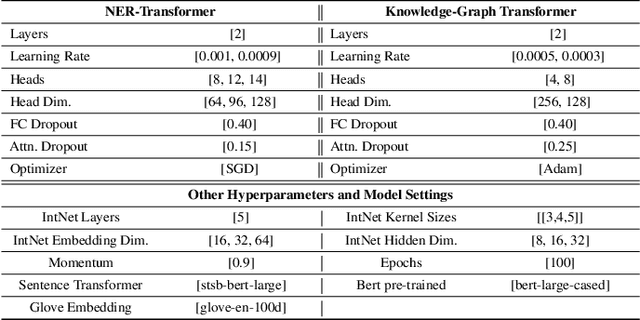
The inception of modeling contextual information using models such as BERT, ELMo, and Flair has significantly improved representation learning for words. It has also given SOTA results in almost every NLP task - Machine Translation, Text Summarization and Named Entity Recognition, to name a few. In this work, in addition to using these dominant context-aware representations, we propose a Knowledge Aware Representation Learning (KARL) Network for Named Entity Recognition (NER). We discuss the challenges of using existing methods in incorporating world knowledge for NER and show how our proposed methods could be leveraged to overcome those challenges. KARL is based on a Transformer Encoder that utilizes large knowledge bases represented as fact triplets, converts them to a graph context, and extracts essential entity information residing inside to generate contextualized triplet representation for feature augmentation. Experimental results show that the augmentation done using KARL can considerably boost the performance of our NER system and achieve significantly better results than existing approaches in the literature on three publicly available NER datasets, namely CoNLL 2003, CoNLL++, and OntoNotes v5. We also observe better generalization and application to a real-world setting from KARL on unseen entities.
A Comparative Study of Transformers on Word Sense Disambiguation
Nov 30, 2021
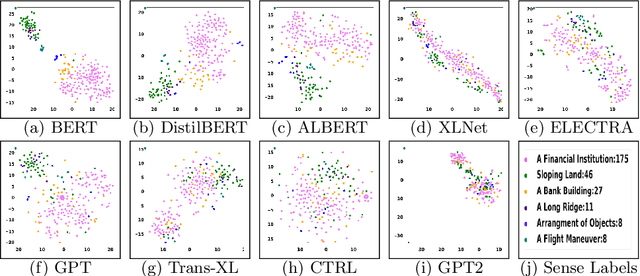
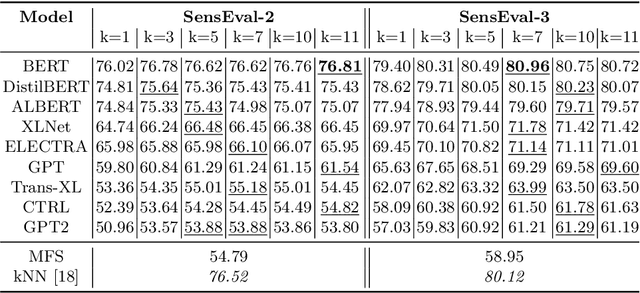
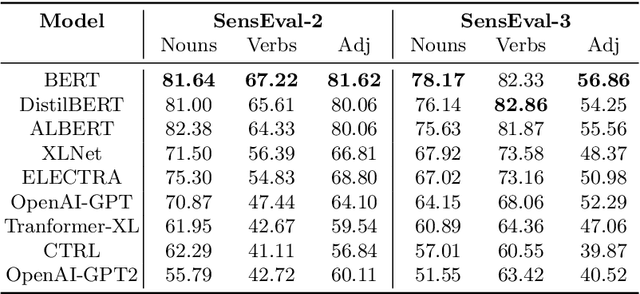
Recent years of research in Natural Language Processing (NLP) have witnessed dramatic growth in training large models for generating context-aware language representations. In this regard, numerous NLP systems have leveraged the power of neural network-based architectures to incorporate sense information in embeddings, resulting in Contextualized Word Embeddings (CWEs). Despite this progress, the NLP community has not witnessed any significant work performing a comparative study on the contextualization power of such architectures. This paper presents a comparative study and an extensive analysis of nine widely adopted Transformer models. These models are BERT, CTRL, DistilBERT, OpenAI-GPT, OpenAI-GPT2, Transformer-XL, XLNet, ELECTRA, and ALBERT. We evaluate their contextualization power using two lexical sample Word Sense Disambiguation (WSD) tasks, SensEval-2 and SensEval-3. We adopt a simple yet effective approach to WSD that uses a k-Nearest Neighbor (kNN) classification on CWEs. Experimental results show that the proposed techniques also achieve superior results over the current state-of-the-art on both the WSD tasks
Does BERT Make Any Sense? Interpretable Word Sense Disambiguation with Contextualized Embeddings
Oct 01, 2019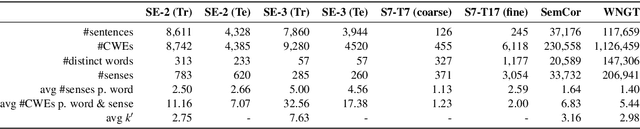
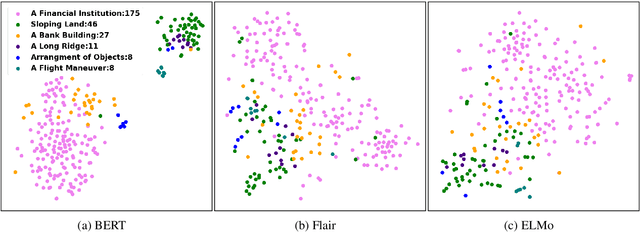
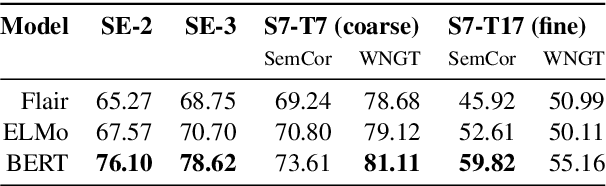
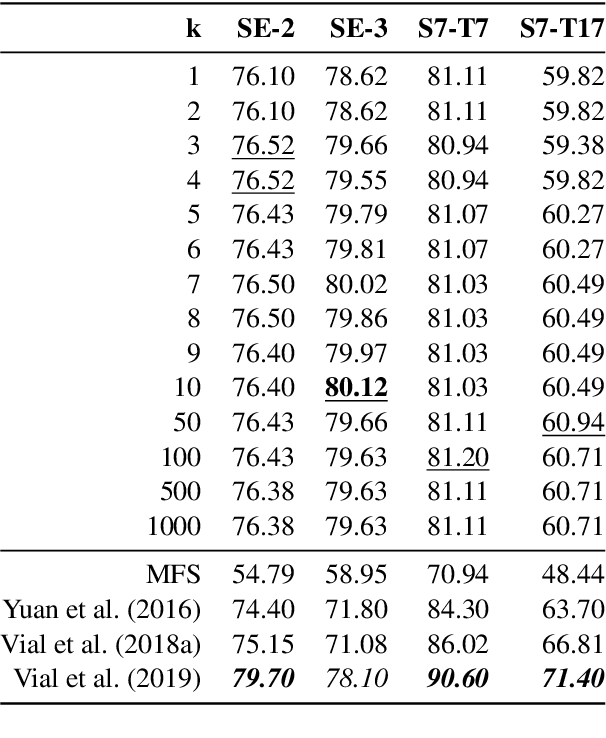
Contextualized word embeddings (CWE) such as provided by ELMo (Peters et al., 2018), Flair NLP (Akbik et al., 2018), or BERT (Devlin et al., 2019) are a major recent innovation in NLP. CWEs provide semantic vector representations of words depending on their respective context. Their advantage over static word embeddings has been shown for a number of tasks, such as text classification, sequence tagging, or machine translation. Since vectors of the same word type can vary depending on the respective context, they implicitly provide a model for word sense disambiguation (WSD). We introduce a simple but effective approach to WSD using a nearest neighbor classification on CWEs. We compare the performance of different CWE models for the task and can report improvements above the current state of the art for two standard WSD benchmark datasets. We further show that the pre-trained BERT model is able to place polysemic words into distinct 'sense' regions of the embedding space, while ELMo and Flair NLP do not seem to possess this ability.
IIT Varanasi at MSR-SRST 2018: A Language Model Based Approach for Natural Language Generation
Apr 12, 2019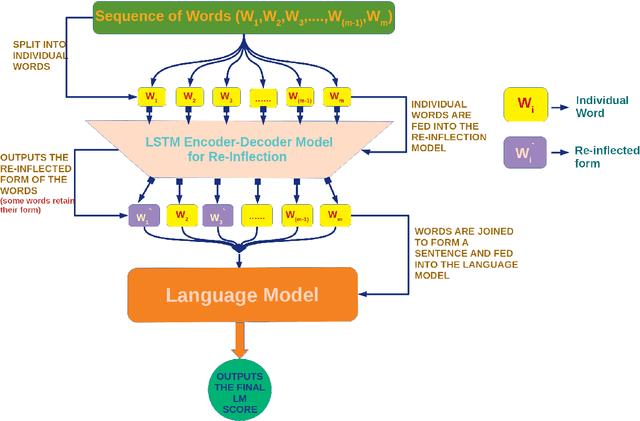
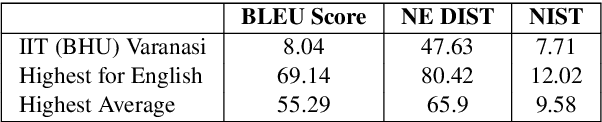
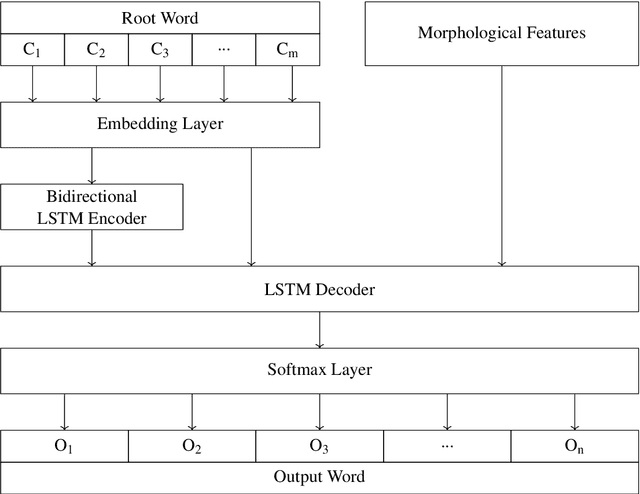
This paper describes our submission system for the Shallow Track of Surface Realization Shared Task 2018 (SRST'18). The task was to convert genuine UD structures, from which word order information had been removed and the tokens had been lemmatized, into their correct sentential form. We divide the problem statement into two parts, word reinflection and correct word order prediction. For the first sub-problem, we use a Long Short Term Memory based Encoder-Decoder approach. For the second sub-problem, we present a Language Model (LM) based approach. We apply two different sub-approaches in the LM Based approach and the combined result of these two approaches is considered as the final output of the system.