 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePETapter: Leveraging PET-style classification heads for modular few-shot parameter-efficient fine-tuning
Dec 06, 2024Few-shot learning and parameter-efficient fine-tuning (PEFT) are crucial to overcome the challenges of data scarcity and ever growing language model sizes. This applies in particular to specialized scientific domains, where researchers might lack expertise and resources to fine-tune high-performing language models to nuanced tasks. We propose PETapter, a novel method that effectively combines PEFT methods with PET-style classification heads to boost few-shot learning capabilities without the significant computational overhead typically associated with full model training. We validate our approach on three established NLP benchmark datasets and one real-world dataset from communication research. We show that PETapter not only achieves comparable performance to full few-shot fine-tuning using pattern-exploiting training (PET), but also provides greater reliability and higher parameter efficiency while enabling higher modularity and easy sharing of the trained modules, which enables more researchers to utilize high-performing NLP-methods in their research.
Few-shot learning for automated content analysis: Efficient coding of arguments and claims in the debate on arms deliveries to Ukraine
Dec 28, 2023Pre-trained language models (PLM) based on transformer neural networks developed in the field of natural language processing (NLP) offer great opportunities to improve automatic content analysis in communication science, especially for the coding of complex semantic categories in large datasets via supervised machine learning. However, three characteristics so far impeded the widespread adoption of the methods in the applying disciplines: the dominance of English language models in NLP research, the necessary computing resources, and the effort required to produce training data to fine-tune PLMs. In this study, we address these challenges by using a multilingual transformer model in combination with the adapter extension to transformers, and few-shot learning methods. We test our approach on a realistic use case from communication science to automatically detect claims and arguments together with their stance in the German news debate on arms deliveries to Ukraine. In three experiments, we evaluate (1) data preprocessing strategies and model variants for this task, (2) the performance of different few-shot learning methods, and (3) how well the best setup performs on varying training set sizes in terms of validity, reliability, replicability and reproducibility of the results. We find that our proposed combination of transformer adapters with pattern exploiting training provides a parameter-efficient and easily shareable alternative to fully fine-tuning PLMs. It performs on par in terms of validity, while overall, provides better properties for application in communication studies. The results also show that pre-fine-tuning for a task on a near-domain dataset leads to substantial improvement, in particular in the few-shot setting. Further, the results indicate that it is useful to bias the dataset away from the viewpoints of specific prominent individuals.
Application of the interactive Leipzig Corpus Miner as a generic research platform for the use in the social sciences
Oct 06, 2021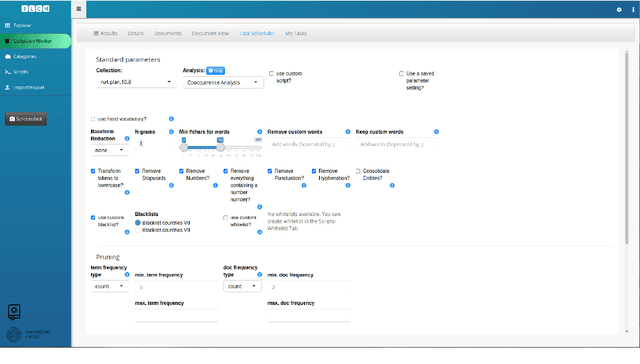
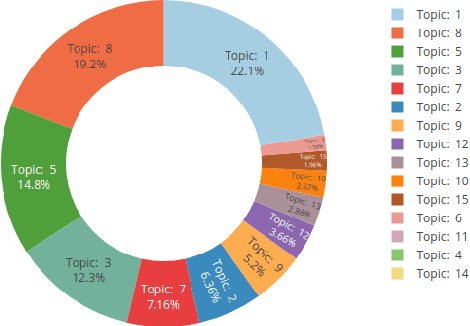

This article introduces to the interactive Leipzig Corpus Miner (iLCM) - a newly released, open-source software to perform automatic content analysis. Since the iLCM is based on the R-programming language, its generic text mining procedures provided via a user-friendly graphical user interface (GUI) can easily be extended using the integrated IDE RStudio-Server or numerous other interfaces in the tool. Furthermore, the iLCM offers various possibilities to use quantitative and qualitative research approaches in combination. Some of these possibilities will be presented in more detail in the following.
UHH-LT & LT2 at SemEval-2020 Task 12: Fine-Tuning of Pre-Trained Transformer Networks for Offensive Language Detection
Apr 23, 2020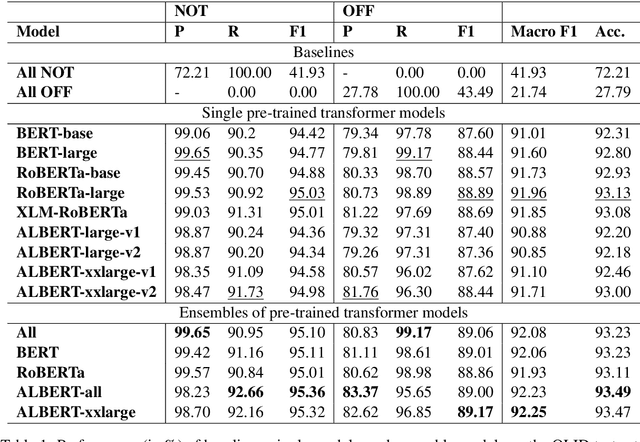


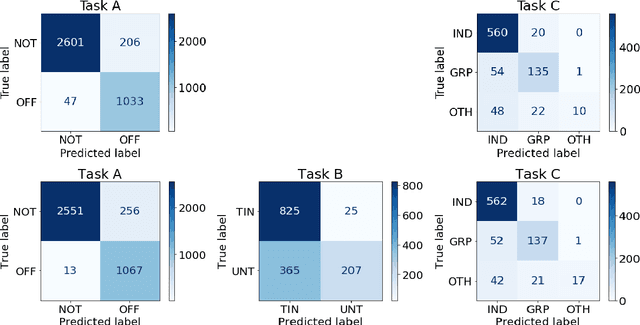
Fine-tuning of pre-trained transformer networks such as BERT yield state-of-the-art results for text classification tasks. Typically, fine-tuning is performed on task-specific training datasets in a supervised manner. One can also fine-tune in unsupervised manner beforehand by further pre-training the masked language modeling (MLM) task. Hereby, in-domain data for unsupervised MLM resembling the actual classification target dataset allows for domain adaptation of the model. In this paper, we compare current pre-trained transformer networks with and without MLM fine-tuning on their performance for offensive language detection. Two different ensembles of our best performing classifiers rank 1st and 2nd out of 85 teams participating in the SemEval 2020 Shared Task~12 for the English language.
Does BERT Make Any Sense? Interpretable Word Sense Disambiguation with Contextualized Embeddings
Oct 01, 2019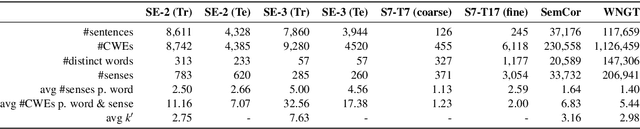
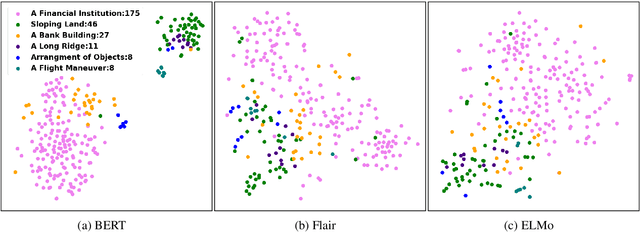
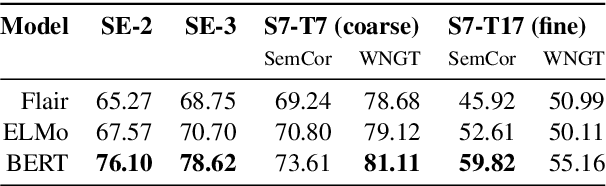
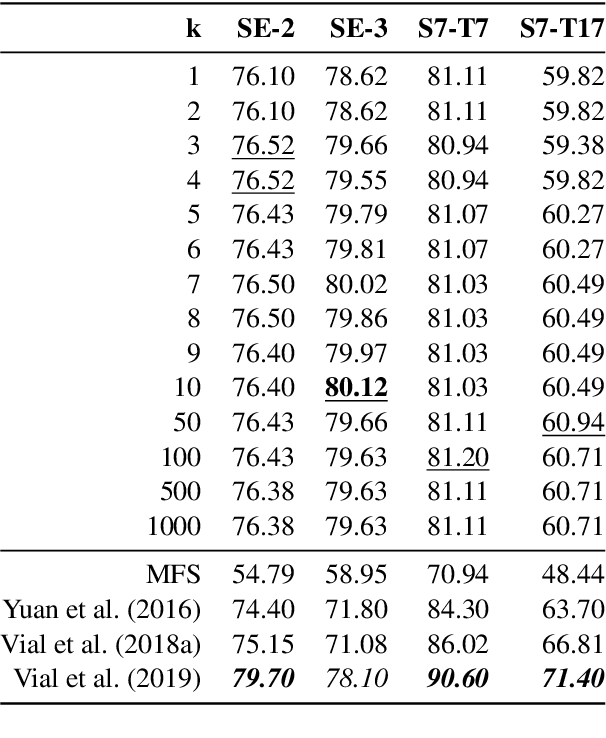
Contextualized word embeddings (CWE) such as provided by ELMo (Peters et al., 2018), Flair NLP (Akbik et al., 2018), or BERT (Devlin et al., 2019) are a major recent innovation in NLP. CWEs provide semantic vector representations of words depending on their respective context. Their advantage over static word embeddings has been shown for a number of tasks, such as text classification, sequence tagging, or machine translation. Since vectors of the same word type can vary depending on the respective context, they implicitly provide a model for word sense disambiguation (WSD). We introduce a simple but effective approach to WSD using a nearest neighbor classification on CWEs. We compare the performance of different CWE models for the task and can report improvements above the current state of the art for two standard WSD benchmark datasets. We further show that the pre-trained BERT model is able to place polysemic words into distinct 'sense' regions of the embedding space, while ELMo and Flair NLP do not seem to possess this ability.
Adversarial Learning of Privacy-Preserving Text Representations for De-Identification of Medical Records
Jun 12, 2019
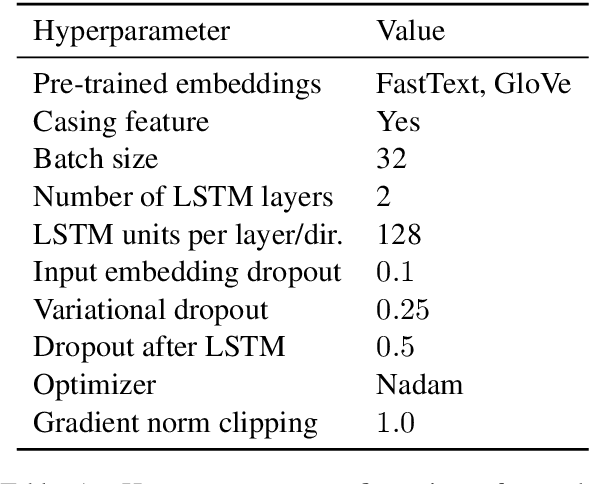
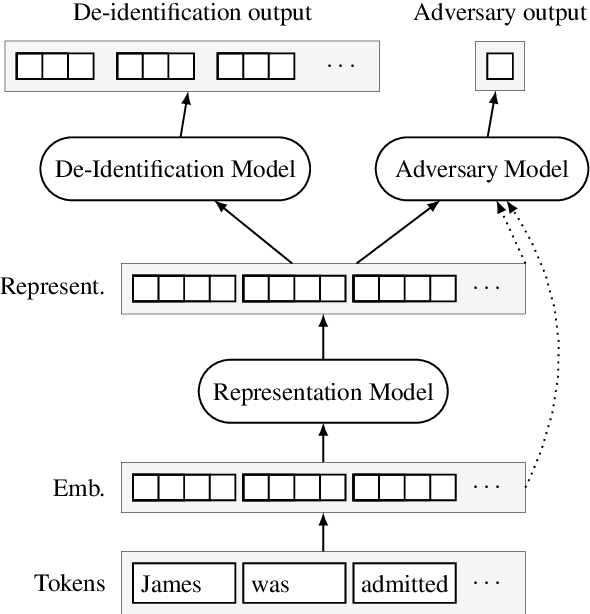
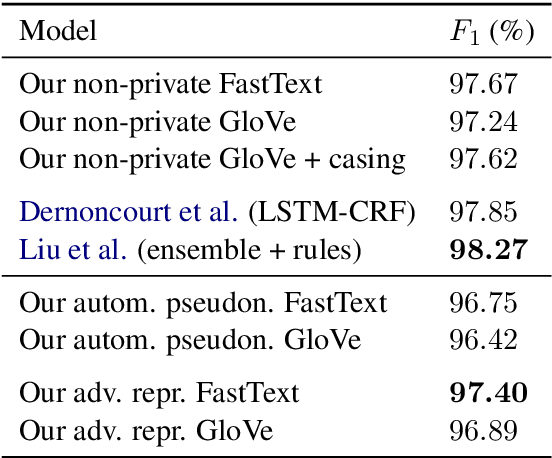
De-identification is the task of detecting protected health information (PHI) in medical text. It is a critical step in sanitizing electronic health records (EHRs) to be shared for research. Automatic de-identification classifierscan significantly speed up the sanitization process. However, obtaining a large and diverse dataset to train such a classifier that works wellacross many types of medical text poses a challenge as privacy laws prohibit the sharing of raw medical records. We introduce a method to create privacy-preserving shareable representations of medical text (i.e. they contain no PHI) that does not require expensive manual pseudonymization. These representations can be shared between organizations to create unified datasets for training de-identification models. Our representation allows training a simple LSTM-CRF de-identification model to an F1 score of 97.4%, which is comparable to a strong baseline that exposes private information in its representation. A robust, widely available de-identification classifier based on our representation could potentially enable studies for which de-identification would otherwise be too costly.
Transfer Learning from LDA to BiLSTM-CNN for Offensive Language Detection in Twitter
Nov 07, 2018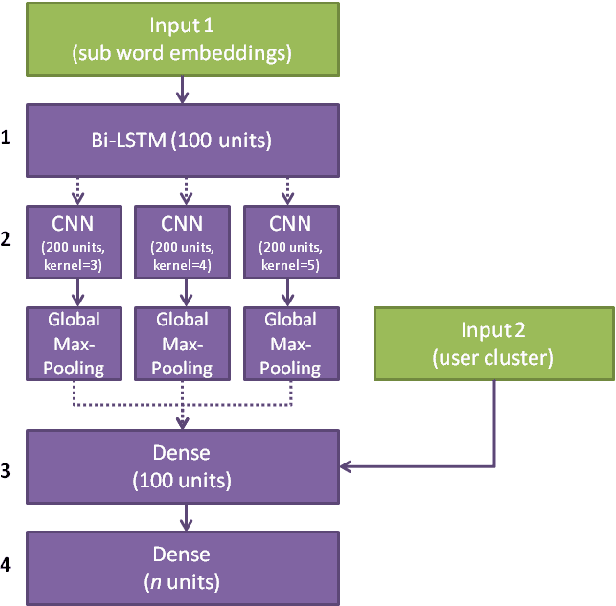

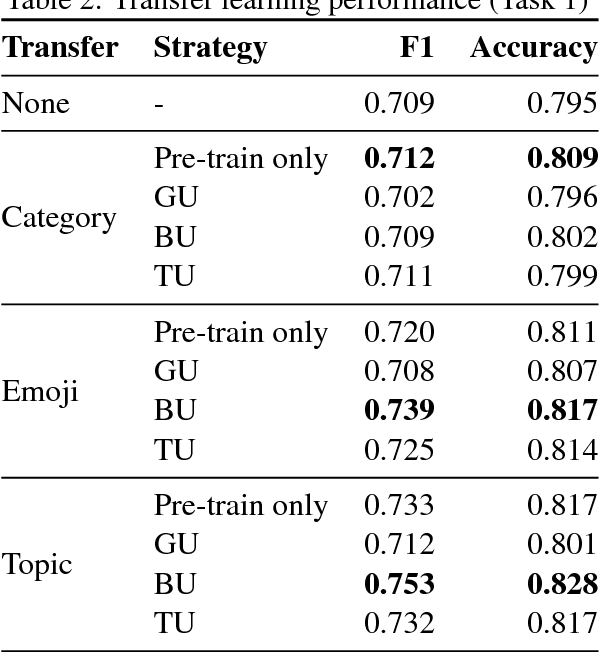
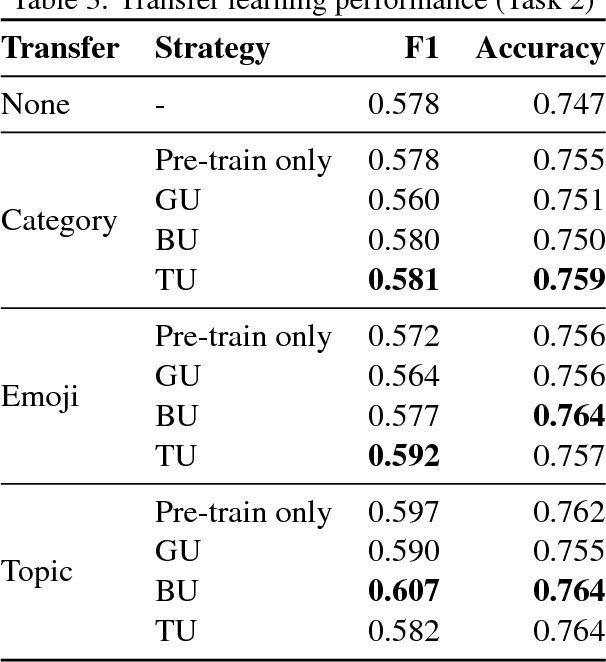
We investigate different strategies for automatic offensive language classification on German Twitter data. For this, we employ a sequentially combined BiLSTM-CNN neural network. Based on this model, three transfer learning tasks to improve the classification performance with background knowledge are tested. We compare 1. Supervised category transfer: social media data annotated with near-offensive language categories, 2. Weakly-supervised category transfer: tweets annotated with emojis they contain, 3. Unsupervised category transfer: tweets annotated with topic clusters obtained by Latent Dirichlet Allocation (LDA). Further, we investigate the effect of three different strategies to mitigate negative effects of 'catastrophic forgetting' during transfer learning. Our results indicate that transfer learning in general improves offensive language detection. Best results are achieved from pre-training our model on the unsupervised topic clustering of tweets in combination with thematic user cluster information.
* 10 pages, 1 figure
microNER: A Micro-Service for German Named Entity Recognition based on BiLSTM-CRF
Nov 07, 2018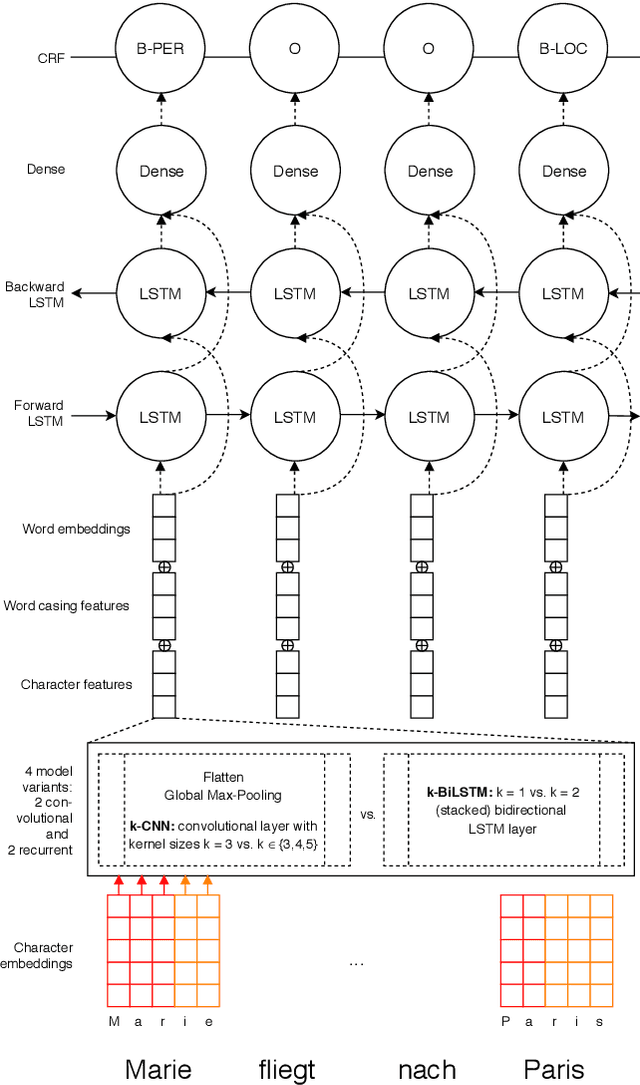
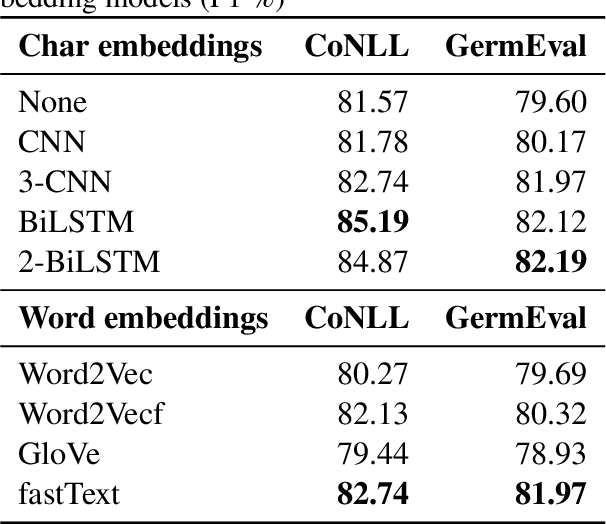
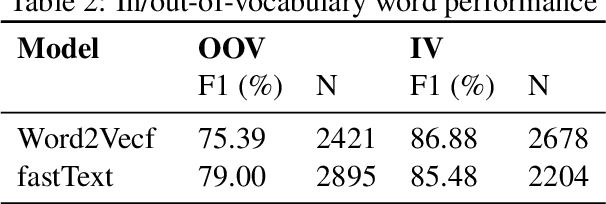
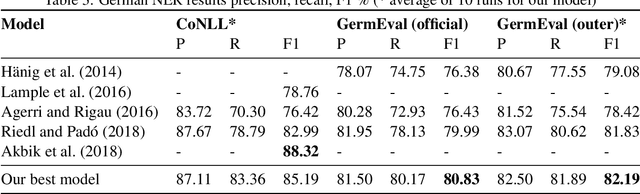
For named entity recognition (NER), bidirectional recurrent neural networks became the state-of-the-art technology in recent years. Competing approaches vary with respect to pre-trained word embeddings as well as models for character embeddings to represent sequence information most effectively. For NER in German language texts, these model variations have not been studied extensively. We evaluate the performance of different word and character embeddings on two standard German datasets and with a special focus on out-of-vocabulary words. With F-Scores above 82% for the GermEval'14 dataset and above 85% for the CoNLL'03 dataset, we achieve (near) state-of-the-art performance for this task. We publish several pre-trained models wrapped into a micro-service based on Docker to allow for easy integration of German NER into other applications via a JSON API.
* 7 pages, 1 figure
A Multilingual Information Extraction Pipeline for Investigative Journalism
Sep 01, 2018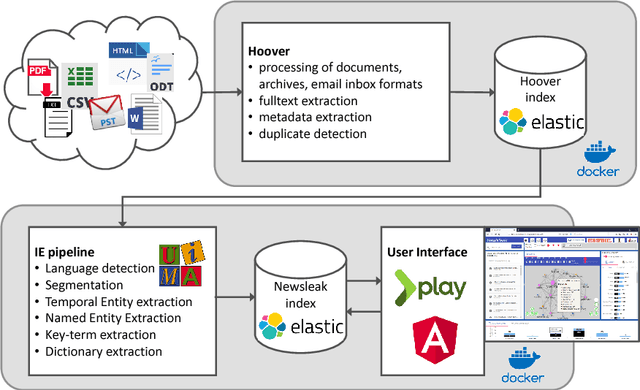
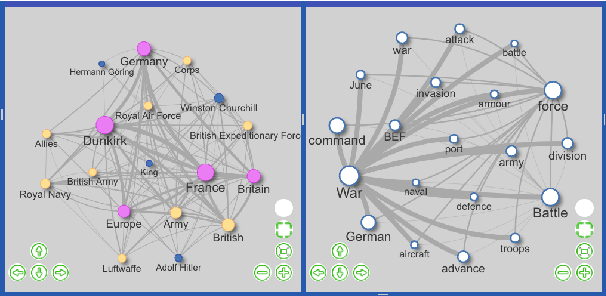
We introduce an advanced information extraction pipeline to automatically process very large collections of unstructured textual data for the purpose of investigative journalism. The pipeline serves as a new input processor for the upcoming major release of our New/s/leak 2.0 software, which we develop in cooperation with a large German news organization. The use case is that journalists receive a large collection of files up to several Gigabytes containing unknown contents. Collections may originate either from official disclosures of documents, e.g. Freedom of Information Act requests, or unofficial data leaks. Our software prepares a visually-aided exploration of the collection to quickly learn about potential stories contained in the data. It is based on the automatic extraction of entities and their co-occurrence in documents. In contrast to comparable projects, we focus on the following three major requirements particularly serving the use case of investigative journalism in cross-border collaborations: 1) composition of multiple state-of-the-art NLP tools for entity extraction, 2) support of multi-lingual document sets up to 40 languages, 3) fast and easy-to-use extraction of full-text, metadata and entities from various file formats.
New/s/leak 2.0 - Multilingual Information Extraction and Visualization for Investigative Journalism
Jul 13, 2018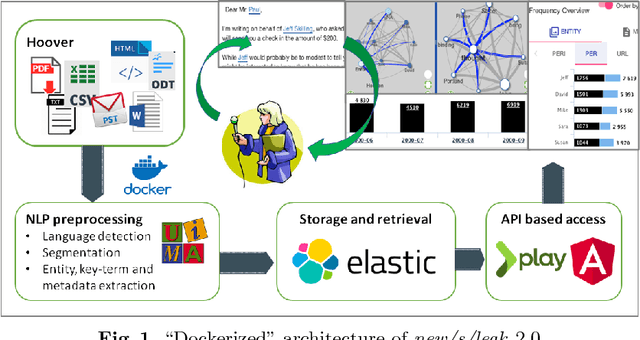
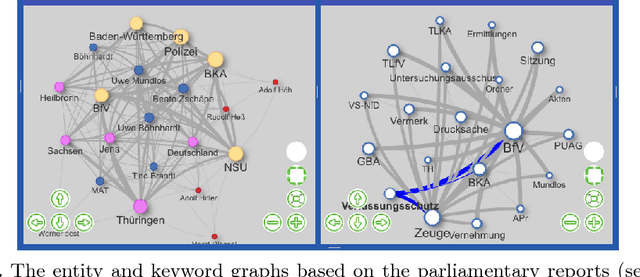
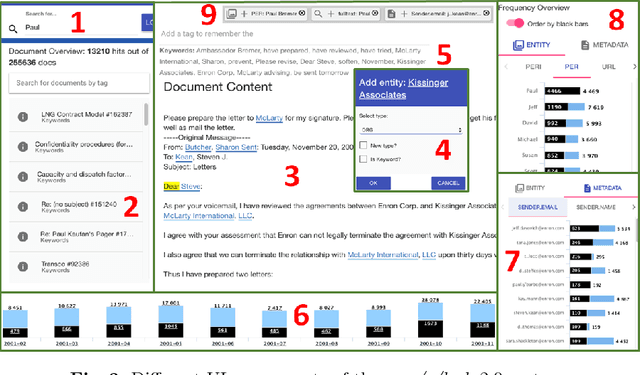
Investigative journalism in recent years is confronted with two major challenges: 1) vast amounts of unstructured data originating from large text collections such as leaks or answers to Freedom of Information requests, and 2) multi-lingual data due to intensified global cooperation and communication in politics, business and civil society. Faced with these challenges, journalists are increasingly cooperating in international networks. To support such collaborations, we present the new version of new/s/leak 2.0, our open-source software for content-based searching of leaks. It includes three novel main features: 1) automatic language detection and language-dependent information extraction for 40 languages, 2) entity and keyword visualization for efficient exploration, and 3) decentral deployment for analysis of confidential data from various formats. We illustrate the new analysis capabilities with an exemplary case study.