 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplication of the interactive Leipzig Corpus Miner as a generic research platform for the use in the social sciences
Oct 06, 2021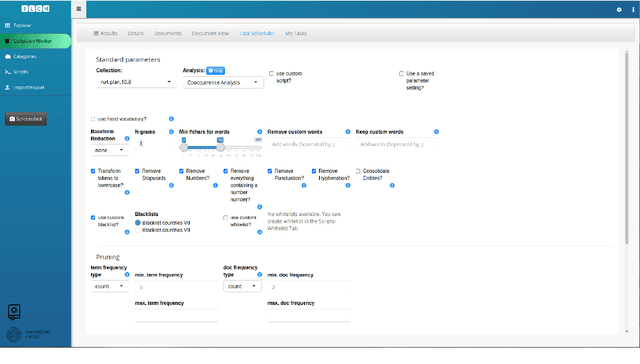

This article introduces to the interactive Leipzig Corpus Miner (iLCM) - a newly released, open-source software to perform automatic content analysis. Since the iLCM is based on the R-programming language, its generic text mining procedures provided via a user-friendly graphical user interface (GUI) can easily be extended using the integrated IDE RStudio-Server or numerous other interfaces in the tool. Furthermore, the iLCM offers various possibilities to use quantitative and qualitative research approaches in combination. Some of these possibilities will be presented in more detail in the following.
iLCM - A Virtual Research Infrastructure for Large-Scale Qualitative Data
May 11, 2018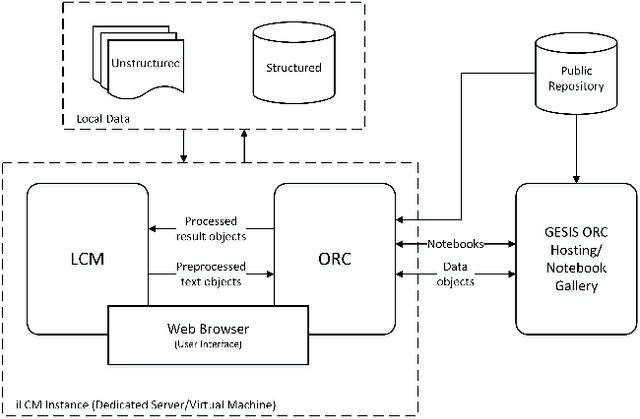
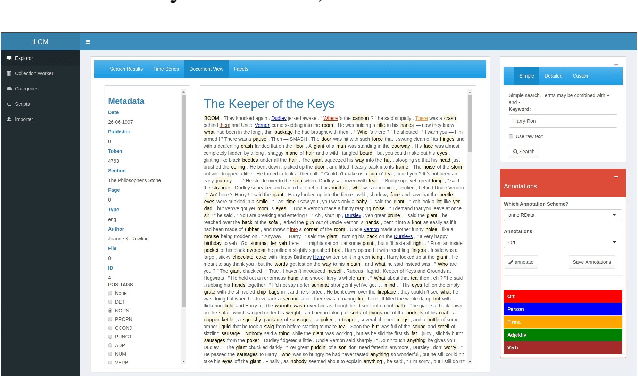
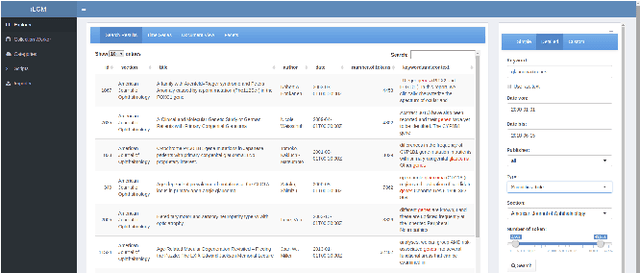
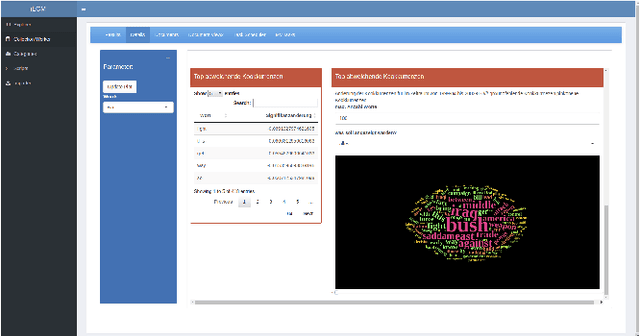
The iLCM project pursues the development of an integrated research environment for the analysis of structured and unstructured data in a "Software as a Service" architecture (SaaS). The research environment addresses requirements for the quantitative evaluation of large amounts of qualitative data with text mining methods as well as requirements for the reproducibility of data-driven research designs in the social sciences. For this, the iLCM research environment comprises two central components. First, the Leipzig Corpus Miner (LCM), a decentralized SaaS application for the analysis of large amounts of news texts developed in a previous Digital Humanities project. Second, the text mining tools implemented in the LCM are extended by an "Open Research Computing" (ORC) environment for executable script documents, so-called "notebooks". This novel integration allows to combine generic, high-performance methods to process large amounts of unstructured text data and with individual program scripts to address specific research requirements in computational social science and digital humanities.
Detecting and assessing contextual change in diachronic text documents using context volatility
Nov 15, 2017
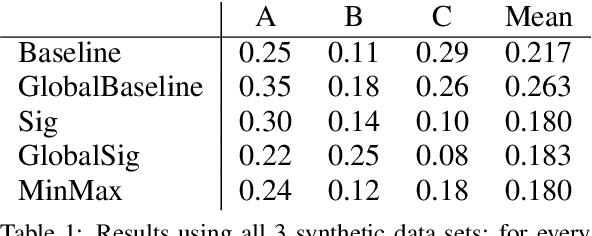
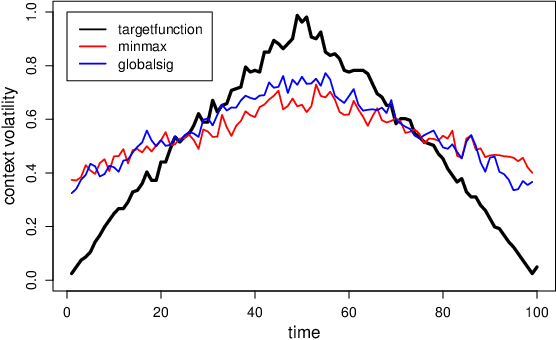
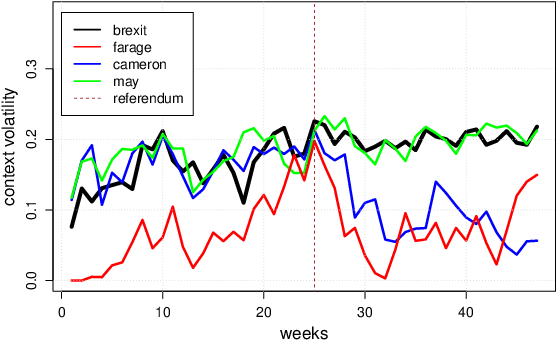
Terms in diachronic text corpora may exhibit a high degree of semantic dynamics that is only partially captured by the common notion of semantic change. The new measure of context volatility that we propose models the degree by which terms change context in a text collection over time. The computation of context volatility for a word relies on the significance-values of its co-occurrent terms and the corresponding co-occurrence ranks in sequential time spans. We define a baseline and present an efficient computational approach in order to overcome problems related to computational issues in the data structure. Results are evaluated both, on synthetic documents that are used to simulate contextual changes, and a real example based on British newspaper texts.