 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiLCM - A Virtual Research Infrastructure for Large-Scale Qualitative Data
May 11, 2018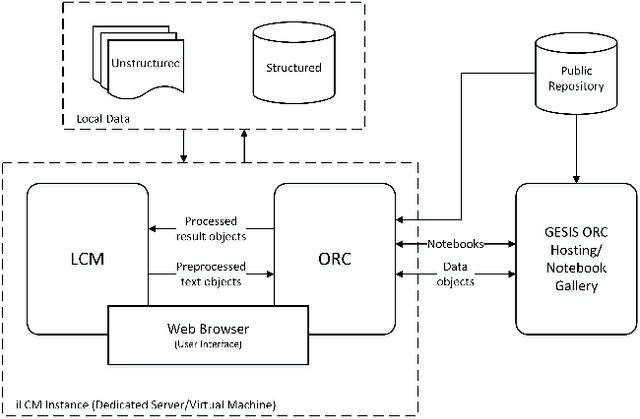
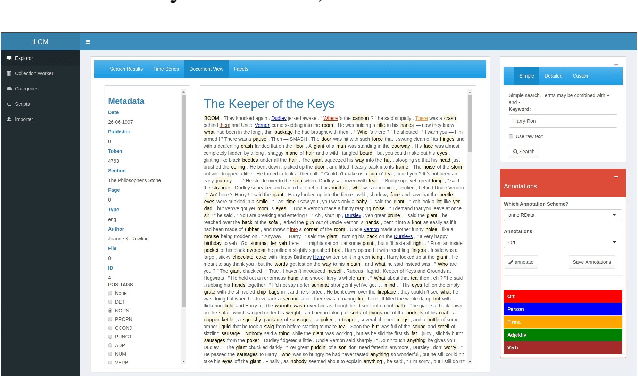
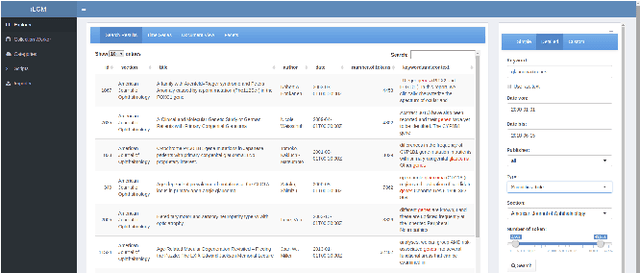
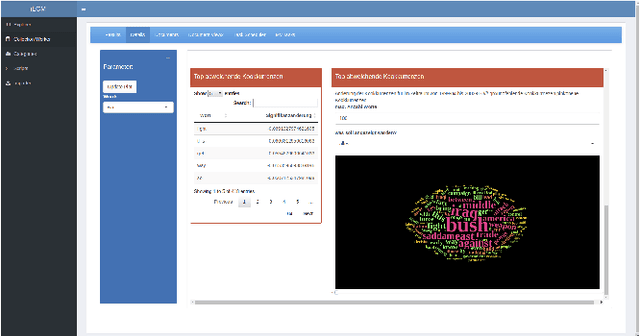
The iLCM project pursues the development of an integrated research environment for the analysis of structured and unstructured data in a "Software as a Service" architecture (SaaS). The research environment addresses requirements for the quantitative evaluation of large amounts of qualitative data with text mining methods as well as requirements for the reproducibility of data-driven research designs in the social sciences. For this, the iLCM research environment comprises two central components. First, the Leipzig Corpus Miner (LCM), a decentralized SaaS application for the analysis of large amounts of news texts developed in a previous Digital Humanities project. Second, the text mining tools implemented in the LCM are extended by an "Open Research Computing" (ORC) environment for executable script documents, so-called "notebooks". This novel integration allows to combine generic, high-performance methods to process large amounts of unstructured text data and with individual program scripts to address specific research requirements in computational social science and digital humanities.
A System for Probabilistic Linking of Thesauri and Classification Systems
Mar 21, 2016
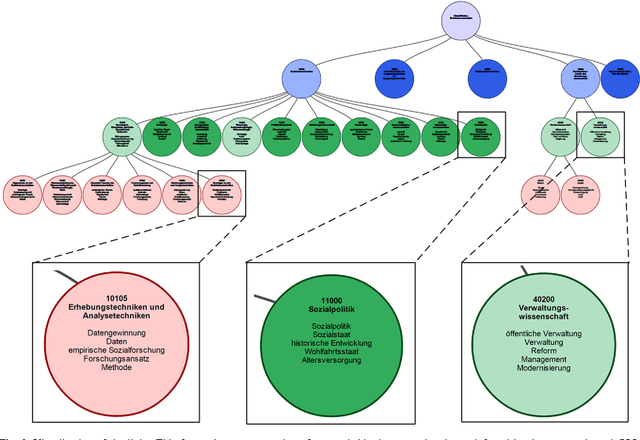
This paper presents a system which creates and visualizes probabilistic semantic links between concepts in a thesaurus and classes in a classification system. For creating the links, we build on the Polylingual Labeled Topic Model (PLL-TM). PLL-TM identifies probable thesaurus descriptors for each class in the classification system by using information from the natural language text of documents, their assigned thesaurus descriptors and their designated classes. The links are then presented to users of the system in an interactive visualization, providing them with an automatically generated overview of the relations between the thesaurus and the classification system.
The Polylingual Labeled Topic Model
Jul 24, 2015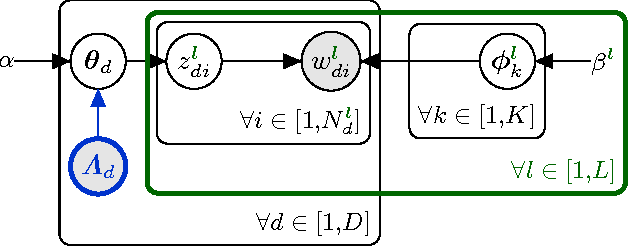
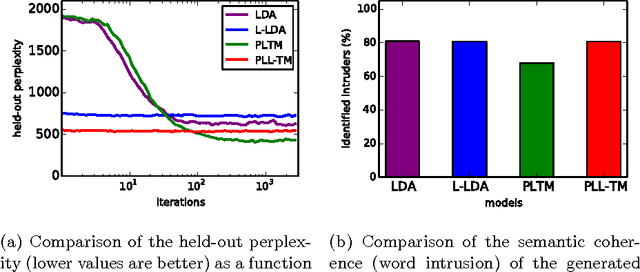
In this paper, we present the Polylingual Labeled Topic Model, a model which combines the characteristics of the existing Polylingual Topic Model and Labeled LDA. The model accounts for multiple languages with separate topic distributions for each language while restricting the permitted topics of a document to a set of predefined labels. We explore the properties of the model in a two-language setting on a dataset from the social science domain. Our experiments show that our model outperforms LDA and Labeled LDA in terms of their held-out perplexity and that it produces semantically coherent topics which are well interpretable by human subjects.