 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormalized Information Needs Improve Large-Language-Model Relevance Judgments
Apr 05, 2026Cranfield-style retrieval evaluations with too few or too many relevant documents or with low inter-assessor agreement on relevance can reduce the reliability of observations. In evaluations with human assessors, information needs are often formalized as retrieval topics to avoid an excessive number of relevant documents while maintaining good agreement. However, emerging evaluation setups that use Large Language Models (LLMs) as relevance assessors often use only queries, potentially decreasing the reliability. To study whether LLM relevance assessors benefit from formalized information needs, we synthetically formalize information needs with LLMs into topics that follow the established structure from previous human relevance assessments (i.e., descriptions and narratives). We compare assessors using synthetically formalized topics against the LLM-default query-only assessor on Robust04 and the 2019/2020 editions of TREC Deep Learning. We find that assessors without formalization judge many more documents relevant and have a lower agreement, leading to reduced reliability in retrieval evaluations. Furthermore, we show that the formalized topics improve agreement between human and LLM relevance judgments, even when the topics are not highly similar to their human counterparts. Our findings indicate that LLM relevance assessors should use formalized information needs, as is standard for human assessment, and synthetically formalize topics when no human formalization exists to improve evaluation reliability.
Validating Search Query Simulations: A Taxonomy of Measures
Jan 16, 2026Assessing the validity of user simulators when used for the evaluation of information retrieval systems remains an open question, constraining their effective use and the reliability of simulation-based results. To address this issue, we conduct a comprehensive literature review with a particular focus on methods for the validation of simulated user queries with regard to real queries. Based on the review, we develop a taxonomy that structures the current landscape of available measures. We empirically corroborate the taxonomy by analyzing the relationships between the different measures applied to four different datasets representing diverse search scenarios. Finally, we provide concrete recommendations on which measures or combinations of measures should be considered when validating user simulation in different contexts. Furthermore, we release a dedicated library with the most commonly used measures to facilitate future research.
LISP -- A Rich Interaction Dataset and Loggable Interactive Search Platform
Jan 14, 2026We present a reusable dataset and accompanying infrastructure for studying human search behavior in Interactive Information Retrieval (IIR). The dataset combines detailed interaction logs from 61 participants (122 sessions) with user characteristics, including perceptual speed, topic-specific interest, search expertise, and demographic information. To facilitate reproducibility and reuse, we provide a fully documented study setup, a web-based perceptual speed test, and a framework for conducting similar user studies. Our work allows researchers to investigate individual and contextual factors affecting search behavior, and to develop or validate user simulators that account for such variability. We illustrate the datasets potential through an illustrative analysis and release all resources as open-access, supporting reproducible research and resource sharing in the IIR community.
Perception-Aware Bias Detection for Query Suggestions
Jan 07, 2026Bias in web search has been in the spotlight of bias detection research for quite a while. At the same time, little attention has been paid to query suggestions in this regard. Awareness of the problem of biased query suggestions has been raised. Likewise, there is a rising need for automatic bias detection approaches. This paper adds on the bias detection pipeline for bias detection in query suggestions of person-related search developed by Bonart et al. \cite{Bonart_2019a}. The sparseness and lack of contextual metadata of query suggestions make them a difficult subject for bias detection. Furthermore, query suggestions are perceived very briefly and subliminally. To overcome these issues, perception-aware metrics are introduced. Consequently, the enhanced pipeline is able to better detect systematic topical bias in search engine query suggestions for person-related searches. The results of an analysis performed with the developed pipeline confirm this assumption. Due to the perception-aware bias detection metrics, findings produced by the pipeline can be assumed to reflect bias that users would discern.
* 13 pages (pp. 130-142); 2 figures; 2 tables; Workshop paper (BIAS 2021) published in CCIS vol. 1418 (Springer)
Auditing Search Query Suggestion Bias Through Recursive Algorithm Interrogation
Jan 06, 2026Despite their important role in online information search, search query suggestions have not been researched as much as most other aspects of search engines. Although reasons for this are multi-faceted, the sparseness of context and the limited data basis of up to ten suggestions per search query pose the most significant problem in identifying bias in search query suggestions. The most proven method to reduce sparseness and improve the validity of bias identification of search query suggestions so far is to consider suggestions from subsequent searches over time for the same query. This work presents a new, alternative approach to search query bias identification that includes less high-level suggestions to deepen the data basis of bias analyses. We employ recursive algorithm interrogation techniques and create suggestion trees that enable access to more subliminal search query suggestions. Based on these suggestions, we investigate topical group bias in person-related searches in the political domain.
Pairwise Comparison for Bias Identification and Quantification
Dec 16, 2025



Linguistic bias in online news and social media is widespread but difficult to measure. Yet, its identification and quantification remain difficult due to subjectivity, context dependence, and the scarcity of high-quality gold-label datasets. We aim to reduce annotation effort by leveraging pairwise comparison for bias annotation. To overcome the costliness of the approach, we evaluate more efficient implementations of pairwise comparison-based rating. We achieve this by investigating the effects of various rating techniques and the parameters of three cost-aware alternatives in a simulation environment. Since the approach can in principle be applied to both human and large language model annotation, our work provides a basis for creating high-quality benchmark datasets and for quantifying biases and other subjective linguistic aspects. The controlled simulations include latent severity distributions, distance-calibrated noise, and synthetic annotator bias to probe robustness and cost-quality trade-offs. In applying the approach to human-labeled bias benchmark datasets, we then evaluate the most promising setups and compare them to direct assessment by large language models and unmodified pairwise comparison labels as baselines. Our findings support the use of pairwise comparison as a practical foundation for quantifying subjective linguistic aspects, enabling reproducible bias analysis. We contribute an optimization of comparison and matchmaking components, an end-to-end evaluation including simulation and real-data application, and an implementation blueprint for cost-aware large-scale annotation
Sim4IA-Bench: A User Simulation Benchmark Suite for Next Query and Utterance Prediction
Nov 12, 2025Validating user simulation is a difficult task due to the lack of established measures and benchmarks, which makes it challenging to assess whether a simulator accurately reflects real user behavior. As part of the Sim4IA Micro-Shared Task at the Sim4IA Workshop, SIGIR 2025, we present Sim4IA-Bench, a simulation benchmark suit for the prediction of the next queries and utterances, the first of its kind in the IR community. Our dataset as part of the suite comprises 160 real-world search sessions from the CORE search engine. For 70 of these sessions, up to 62 simulator runs are available, divided into Task A and Task B, in which different approaches predicted users next search queries or utterances. Sim4IA-Bench provides a basis for evaluating and comparing user simulation approaches and for developing new measures of simulator validity. Although modest in size, the suite represents the first publicly available benchmark that links real search sessions with simulated next-query predictions. In addition to serving as a testbed for next query prediction, it also enables exploratory studies on query reformulation behavior, intent drift, and interaction-aware retrieval evaluation. We also introduce a new measure for evaluating next-query predictions in this task. By making the suite publicly available, we aim to promote reproducible research and stimulate further work on realistic and explainable user simulation for information access: https://github.com/irgroup/Sim4IA-Bench.
Second SIGIR Workshop on Simulations for Information Access (Sim4IA 2025)
May 16, 2025

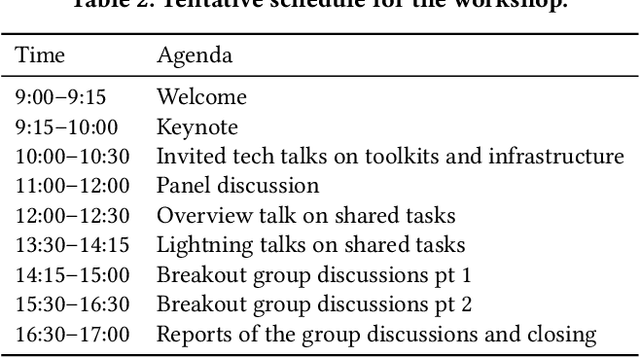
Simulations in information access (IA) have recently gained interest, as shown by various tutorials and workshops around that topic. Simulations can be key contributors to central IA research and evaluation questions, especially around interactive settings when real users are unavailable, or their participation is impossible due to ethical reasons. In addition, simulations in IA can help contribute to a better understanding of users, reduce complexity of evaluation experiments, and improve reproducibility. Building on recent developments in methods and toolkits, the second iteration of our Sim4IA workshop aims to again bring together researchers and practitioners to form an interactive and engaging forum for discussions on the future perspectives of the field. An additional aim is to plan an upcoming TREC/CLEF campaign.
Evaluating Contrastive Feedback for Effective User Simulations
May 05, 2025

The use of Large Language Models (LLMs) for simulating user behavior in the domain of Interactive Information Retrieval has recently gained significant popularity. However, their application and capabilities remain highly debated and understudied. This study explores whether the underlying principles of contrastive training techniques, which have been effective for fine-tuning LLMs, can also be applied beneficially in the area of prompt engineering for user simulations. Previous research has shown that LLMs possess comprehensive world knowledge, which can be leveraged to provide accurate estimates of relevant documents. This study attempts to simulate a knowledge state by enhancing the model with additional implicit contextual information gained during the simulation. This approach enables the model to refine the scope of desired documents further. The primary objective of this study is to analyze how different modalities of contextual information influence the effectiveness of user simulations. Various user configurations were tested, where models are provided with summaries of already judged relevant, irrelevant, or both types of documents in a contrastive manner. The focus of this study is the assessment of the impact of the prompting techniques on the simulated user agent performance. We hereby lay the foundations for leveraging LLMs as part of more realistic simulated users.
REANIMATOR: Reanimate Retrieval Test Collections with Extracted and Synthetic Resources
Apr 10, 2025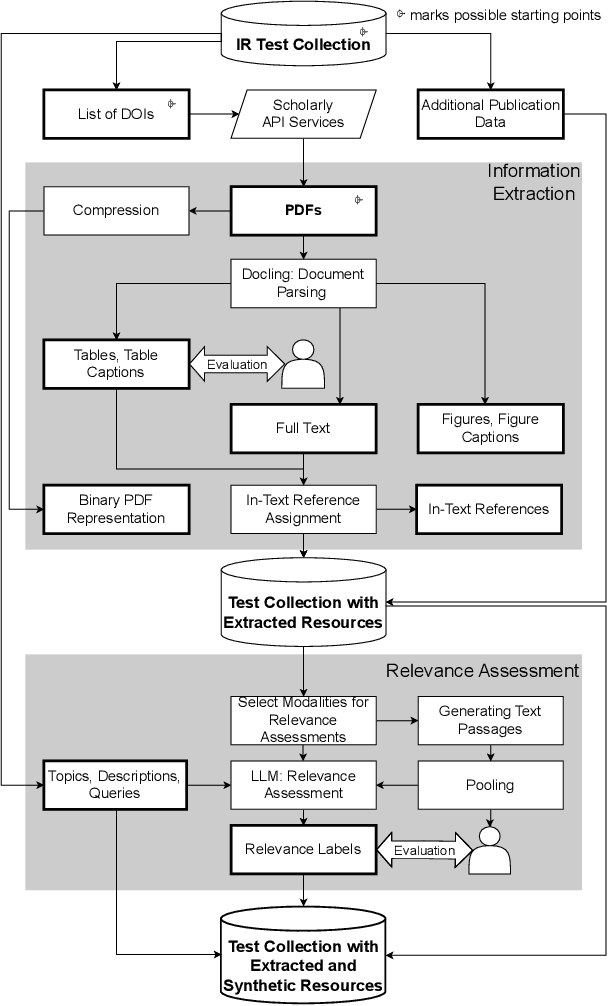


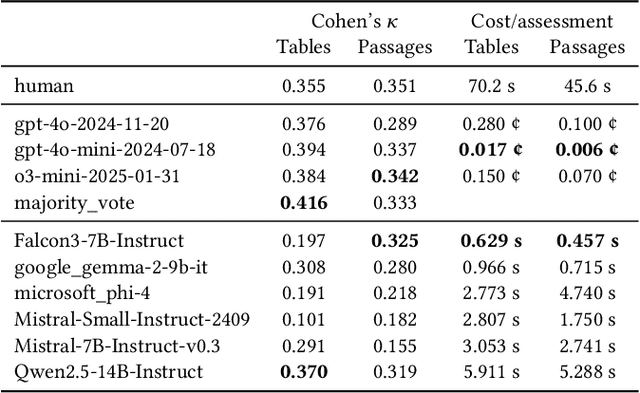
Retrieval test collections are essential for evaluating information retrieval systems, yet they often lack generalizability across tasks. To overcome this limitation, we introduce REANIMATOR, a versatile framework designed to enable the repurposing of existing test collections by enriching them with extracted and synthetic resources. REANIMATOR enhances test collections from PDF files by parsing full texts and machine-readable tables, as well as related contextual information. It then employs state-of-the-art large language models to produce synthetic relevance labels. Including an optional human-in-the-loop step can help validate the resources that have been extracted and generated. We demonstrate its potential with a revitalized version of the TREC-COVID test collection, showcasing the development of a retrieval-augmented generation system and evaluating the impact of tables on retrieval-augmented generation. REANIMATOR enables the reuse of test collections for new applications, lowering costs and broadening the utility of legacy resources.