 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREANIMATOR: Reanimate Retrieval Test Collections with Extracted and Synthetic Resources
Apr 10, 2025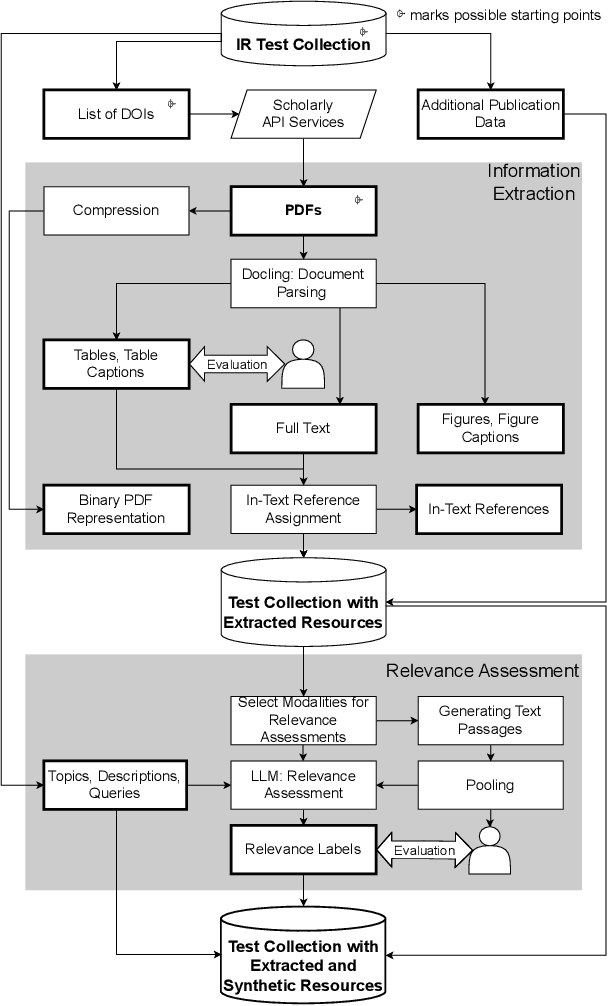


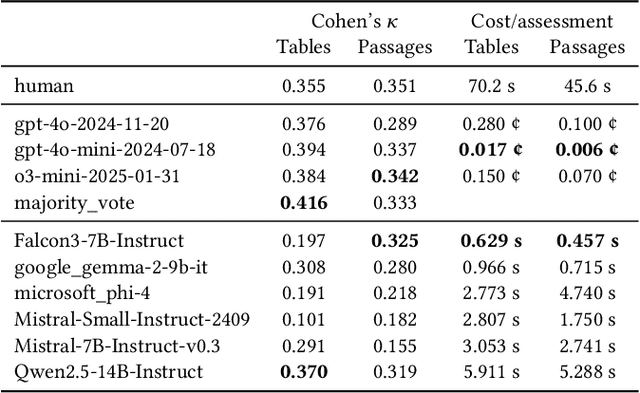
Retrieval test collections are essential for evaluating information retrieval systems, yet they often lack generalizability across tasks. To overcome this limitation, we introduce REANIMATOR, a versatile framework designed to enable the repurposing of existing test collections by enriching them with extracted and synthetic resources. REANIMATOR enhances test collections from PDF files by parsing full texts and machine-readable tables, as well as related contextual information. It then employs state-of-the-art large language models to produce synthetic relevance labels. Including an optional human-in-the-loop step can help validate the resources that have been extracted and generated. We demonstrate its potential with a revitalized version of the TREC-COVID test collection, showcasing the development of a retrieval-augmented generation system and evaluating the impact of tables on retrieval-augmented generation. REANIMATOR enables the reuse of test collections for new applications, lowering costs and broadening the utility of legacy resources.
Investigating Bias in Political Search Query Suggestions by Relative Comparison with LLMs
Oct 31, 2024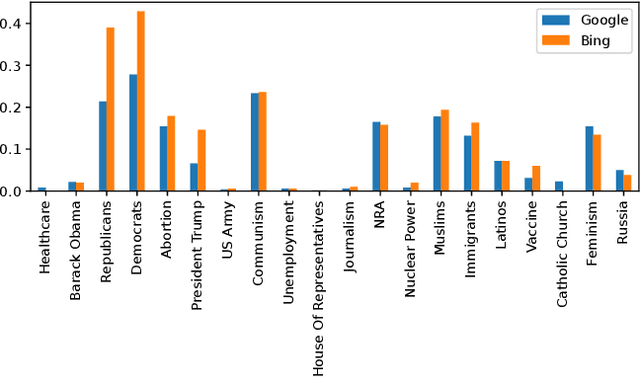

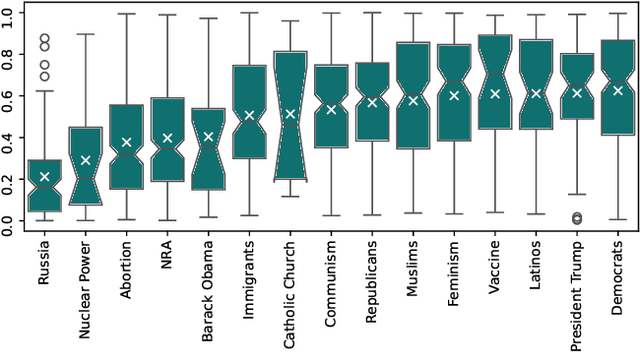
Search query suggestions affect users' interactions with search engines, which then influences the information they encounter. Thus, bias in search query suggestions can lead to exposure to biased search results and can impact opinion formation. This is especially critical in the political domain. Detecting and quantifying bias in web search engines is difficult due to its topic dependency, complexity, and subjectivity. The lack of context and phrasality of query suggestions emphasizes this problem. In a multi-step approach, we combine the benefits of large language models, pairwise comparison, and Elo-based scoring to identify and quantify bias in English search query suggestions. We apply our approach to the U.S. political news domain and compare bias in Google and Bing.
Context-Driven Interactive Query Simulations Based on Generative Large Language Models
Dec 15, 2023Simulating user interactions enables a more user-oriented evaluation of information retrieval (IR) systems. While user simulations are cost-efficient and reproducible, many approaches often lack fidelity regarding real user behavior. Most notably, current user models neglect the user's context, which is the primary driver of perceived relevance and the interactions with the search results. To this end, this work introduces the simulation of context-driven query reformulations. The proposed query generation methods build upon recent Large Language Model (LLM) approaches and consider the user's context throughout the simulation of a search session. Compared to simple context-free query generation approaches, these methods show better effectiveness and allow the simulation of more efficient IR sessions. Similarly, our evaluations consider more interaction context than current session-based measures and reveal interesting complementary insights in addition to the established evaluation protocols. We conclude with directions for future work and provide an entirely open experimental setup.
Simulating Users in Interactive Web Table Retrieval
Oct 18, 2023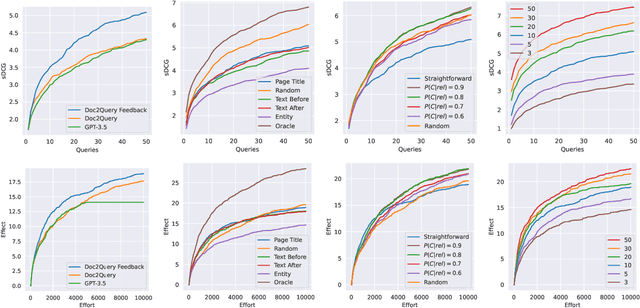
Considering the multimodal signals of search items is beneficial for retrieval effectiveness. Especially in web table retrieval (WTR) experiments, accounting for multimodal properties of tables boosts effectiveness. However, it still remains an open question how the single modalities affect user experience in particular. Previous work analyzed WTR performance in ad-hoc retrieval benchmarks, which neglects interactive search behavior and limits the conclusion about the implications for real-world user environments. To this end, this work presents an in-depth evaluation of simulated interactive WTR search sessions as a more cost-efficient and reproducible alternative to real user studies. As a first of its kind, we introduce interactive query reformulation strategies based on Doc2Query, incorporating cognitive states of simulated user knowledge. Our evaluations include two perspectives on user effectiveness by considering different cost paradigms, namely query-wise and time-oriented measures of effort. Our multi-perspective evaluation scheme reveals new insights about query strategies, the impact of modalities, and different user types in simulated WTR search sessions.
* 4 pages + references; accepted at CIKM'23
Text Simplification of Scientific Texts for Non-Expert Readers
Jul 07, 2023Reading levels are highly individual and can depend on a text's language, a person's cognitive abilities, or knowledge on a topic. Text simplification is the task of rephrasing a text to better cater to the abilities of a specific target reader group. Simplification of scientific abstracts helps non-experts to access the core information by bypassing formulations that require domain or expert knowledge. This is especially relevant for, e.g., cancer patients reading about novel treatment options. The SimpleText lab hosts the simplification of scientific abstracts for non-experts (Task 3) to advance this field. We contribute three runs employing out-of-the-box summarization models (two based on T5, one based on PEGASUS) and one run using ChatGPT with complex phrase identification.