 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSim4IA-Bench: A User Simulation Benchmark Suite for Next Query and Utterance Prediction
Nov 12, 2025Validating user simulation is a difficult task due to the lack of established measures and benchmarks, which makes it challenging to assess whether a simulator accurately reflects real user behavior. As part of the Sim4IA Micro-Shared Task at the Sim4IA Workshop, SIGIR 2025, we present Sim4IA-Bench, a simulation benchmark suit for the prediction of the next queries and utterances, the first of its kind in the IR community. Our dataset as part of the suite comprises 160 real-world search sessions from the CORE search engine. For 70 of these sessions, up to 62 simulator runs are available, divided into Task A and Task B, in which different approaches predicted users next search queries or utterances. Sim4IA-Bench provides a basis for evaluating and comparing user simulation approaches and for developing new measures of simulator validity. Although modest in size, the suite represents the first publicly available benchmark that links real search sessions with simulated next-query predictions. In addition to serving as a testbed for next query prediction, it also enables exploratory studies on query reformulation behavior, intent drift, and interaction-aware retrieval evaluation. We also introduce a new measure for evaluating next-query predictions in this task. By making the suite publicly available, we aim to promote reproducible research and stimulate further work on realistic and explainable user simulation for information access: https://github.com/irgroup/Sim4IA-Bench.
Second SIGIR Workshop on Simulations for Information Access (Sim4IA 2025)
May 16, 2025Simulations in information access (IA) have recently gained interest, as shown by various tutorials and workshops around that topic. Simulations can be key contributors to central IA research and evaluation questions, especially around interactive settings when real users are unavailable, or their participation is impossible due to ethical reasons. In addition, simulations in IA can help contribute to a better understanding of users, reduce complexity of evaluation experiments, and improve reproducibility. Building on recent developments in methods and toolkits, the second iteration of our Sim4IA workshop aims to again bring together researchers and practitioners to form an interactive and engaging forum for discussions on the future perspectives of the field. An additional aim is to plan an upcoming TREC/CLEF campaign.
Evaluating Contrastive Feedback for Effective User Simulations
May 05, 2025

The use of Large Language Models (LLMs) for simulating user behavior in the domain of Interactive Information Retrieval has recently gained significant popularity. However, their application and capabilities remain highly debated and understudied. This study explores whether the underlying principles of contrastive training techniques, which have been effective for fine-tuning LLMs, can also be applied beneficially in the area of prompt engineering for user simulations. Previous research has shown that LLMs possess comprehensive world knowledge, which can be leveraged to provide accurate estimates of relevant documents. This study attempts to simulate a knowledge state by enhancing the model with additional implicit contextual information gained during the simulation. This approach enables the model to refine the scope of desired documents further. The primary objective of this study is to analyze how different modalities of contextual information influence the effectiveness of user simulations. Various user configurations were tested, where models are provided with summaries of already judged relevant, irrelevant, or both types of documents in a contrastive manner. The focus of this study is the assessment of the impact of the prompting techniques on the simulated user agent performance. We hereby lay the foundations for leveraging LLMs as part of more realistic simulated users.
Data Fusion of Synthetic Query Variants With Generative Large Language Models
Nov 06, 2024

Considering query variance in information retrieval (IR) experiments is beneficial for retrieval effectiveness. Especially ranking ensembles based on different topically related queries retrieve better results than rankings based on a single query alone. Recently, generative instruction-tuned Large Language Models (LLMs) improved on a variety of different tasks in capturing human language. To this end, this work explores the feasibility of using synthetic query variants generated by instruction-tuned LLMs in data fusion experiments. More specifically, we introduce a lightweight, unsupervised, and cost-efficient approach that exploits principled prompting and data fusion techniques. In our experiments, LLMs produce more effective queries when provided with additional context information on the topic. Furthermore, our analysis based on four TREC newswire benchmarks shows that data fusion based on synthetic query variants is significantly better than baselines with single queries and also outperforms pseudo-relevance feedback methods. We publicly share the code and query datasets with the community as resources for follow-up studies.
Report on the Workshop on Simulations for Information Access (Sim4IA 2024) at SIGIR 2024
Sep 26, 2024



This paper is a report of the Workshop on Simulations for Information Access (Sim4IA) workshop at SIGIR 2024. The workshop had two keynotes, a panel discussion, nine lightning talks, and two breakout sessions. Key takeaways were user simulation's importance in academia and industry, the possible bridging of online and offline evaluation, and the issues of organizing a companion shared task around user simulations for information access. We report on how we organized the workshop, provide a brief overview of what happened at the workshop, and summarize the main topics and findings of the workshop and future work.
Replicability Measures for Longitudinal Information Retrieval Evaluation
Sep 09, 2024Information Retrieval (IR) systems are exposed to constant changes in most components. Documents are created, updated, or deleted, the information needs are changing, and even relevance might not be static. While it is generally expected that the IR systems retain a consistent utility for the users, test collection evaluations rely on a fixed experimental setup. Based on the LongEval shared task and test collection, this work explores how the effectiveness measured in evolving experiments can be assessed. Specifically, the persistency of effectiveness is investigated as a replicability task. It is observed how the effectiveness progressively deteriorates over time compared to the initial measurement. Employing adapted replicability measures provides further insight into the persistence of effectiveness. The ranking of systems varies across retrieval measures and time. In conclusion, it was found that the most effective systems are not necessarily the ones with the most persistent performance.
The Two Sides of the Coin: Hallucination Generation and Detection with LLMs as Evaluators for LLMs
Jul 12, 2024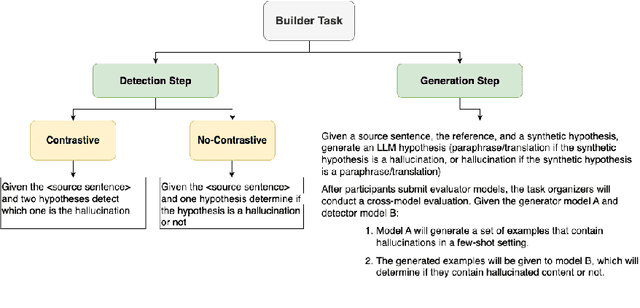

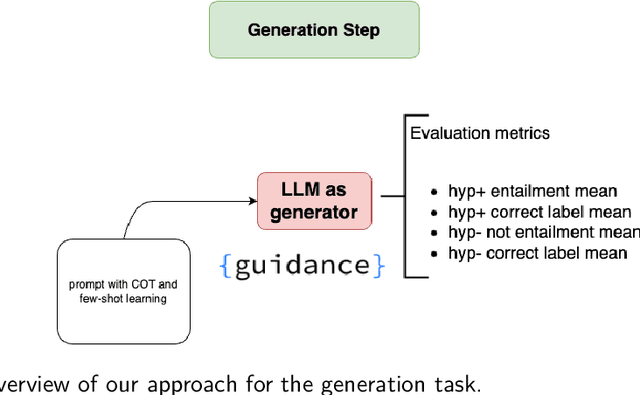

Hallucination detection in Large Language Models (LLMs) is crucial for ensuring their reliability. This work presents our participation in the CLEF ELOQUENT HalluciGen shared task, where the goal is to develop evaluators for both generating and detecting hallucinated content. We explored the capabilities of four LLMs: Llama 3, Gemma, GPT-3.5 Turbo, and GPT-4, for this purpose. We also employed ensemble majority voting to incorporate all four models for the detection task. The results provide valuable insights into the strengths and weaknesses of these LLMs in handling hallucination generation and detection tasks.
Evaluation of Temporal Change in IR Test Collections
Jul 01, 2024



Information retrieval systems have been evaluated using the Cranfield paradigm for many years. This paradigm allows a systematic, fair, and reproducible evaluation of different retrieval methods in fixed experimental environments. However, real-world retrieval systems must cope with dynamic environments and temporal changes that affect the document collection, topical trends, and the individual user's perception of what is considered relevant. Yet, the temporal dimension in IR evaluations is still understudied. To this end, this work investigates how the temporal generalizability of effectiveness evaluations can be assessed. As a conceptual model, we generalize Cranfield-type experiments to the temporal context by classifying the change in the essential components according to the create, update, and delete operations of persistent storage known from CRUD. From the different types of change different evaluation scenarios are derived and it is outlined what they imply. Based on these scenarios, renowned state-of-the-art retrieval systems are tested and it is investigated how the retrieval effectiveness changes on different levels of granularity. We show that the proposed measures can be well adapted to describe the changes in the retrieval results. The experiments conducted confirm that the retrieval effectiveness strongly depends on the evaluation scenario investigated. We find that not only the average retrieval performance of single systems but also the relative system performance are strongly affected by the components that change and to what extent these components changed.
Context-Driven Interactive Query Simulations Based on Generative Large Language Models
Dec 15, 2023Simulating user interactions enables a more user-oriented evaluation of information retrieval (IR) systems. While user simulations are cost-efficient and reproducible, many approaches often lack fidelity regarding real user behavior. Most notably, current user models neglect the user's context, which is the primary driver of perceived relevance and the interactions with the search results. To this end, this work introduces the simulation of context-driven query reformulations. The proposed query generation methods build upon recent Large Language Model (LLM) approaches and consider the user's context throughout the simulation of a search session. Compared to simple context-free query generation approaches, these methods show better effectiveness and allow the simulation of more efficient IR sessions. Similarly, our evaluations consider more interaction context than current session-based measures and reveal interesting complementary insights in addition to the established evaluation protocols. We conclude with directions for future work and provide an entirely open experimental setup.
Simulating Users in Interactive Web Table Retrieval
Oct 18, 2023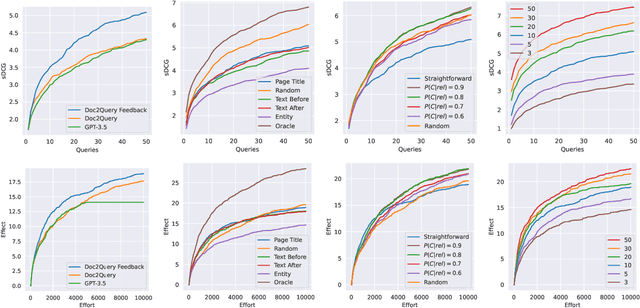
Considering the multimodal signals of search items is beneficial for retrieval effectiveness. Especially in web table retrieval (WTR) experiments, accounting for multimodal properties of tables boosts effectiveness. However, it still remains an open question how the single modalities affect user experience in particular. Previous work analyzed WTR performance in ad-hoc retrieval benchmarks, which neglects interactive search behavior and limits the conclusion about the implications for real-world user environments. To this end, this work presents an in-depth evaluation of simulated interactive WTR search sessions as a more cost-efficient and reproducible alternative to real user studies. As a first of its kind, we introduce interactive query reformulation strategies based on Doc2Query, incorporating cognitive states of simulated user knowledge. Our evaluations include two perspectives on user effectiveness by considering different cost paradigms, namely query-wise and time-oriented measures of effort. Our multi-perspective evaluation scheme reveals new insights about query strategies, the impact of modalities, and different user types in simulated WTR search sessions.
* 4 pages + references; accepted at CIKM'23