 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReport on the Workshop on Simulations for Information Access (Sim4IA 2024) at SIGIR 2024
Sep 26, 2024



This paper is a report of the Workshop on Simulations for Information Access (Sim4IA) workshop at SIGIR 2024. The workshop had two keynotes, a panel discussion, nine lightning talks, and two breakout sessions. Key takeaways were user simulation's importance in academia and industry, the possible bridging of online and offline evaluation, and the issues of organizing a companion shared task around user simulations for information access. We report on how we organized the workshop, provide a brief overview of what happened at the workshop, and summarize the main topics and findings of the workshop and future work.
Are Large Language Models Reliable Argument Quality Annotators?
Apr 15, 2024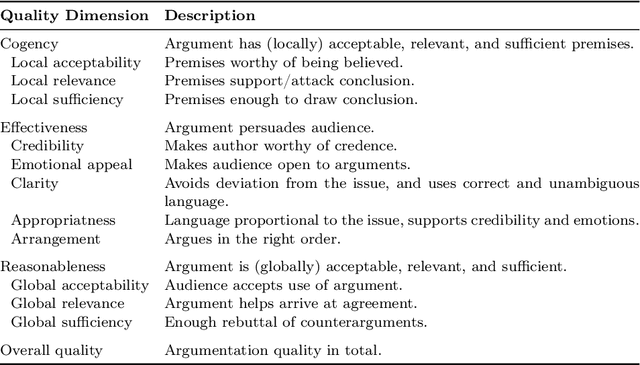

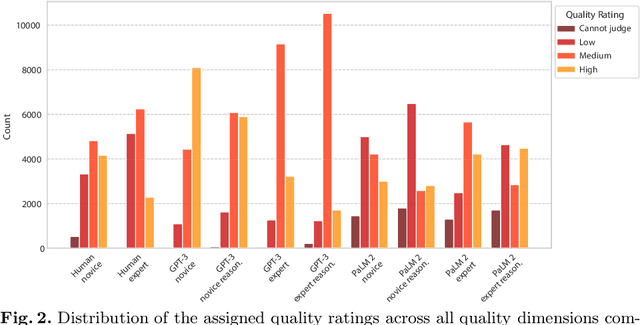
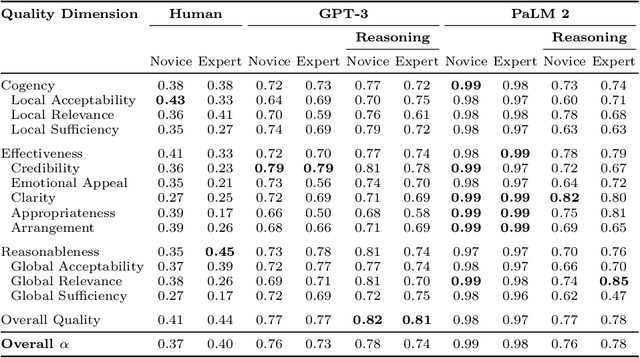
Evaluating the quality of arguments is a crucial aspect of any system leveraging argument mining. However, it is a challenge to obtain reliable and consistent annotations regarding argument quality, as this usually requires domain-specific expertise of the annotators. Even among experts, the assessment of argument quality is often inconsistent due to the inherent subjectivity of this task. In this paper, we study the potential of using state-of-the-art large language models (LLMs) as proxies for argument quality annotators. To assess the capability of LLMs in this regard, we analyze the agreement between model, human expert, and human novice annotators based on an established taxonomy of argument quality dimensions. Our findings highlight that LLMs can produce consistent annotations, with a moderately high agreement with human experts across most of the quality dimensions. Moreover, we show that using LLMs as additional annotators can significantly improve the agreement between annotators. These results suggest that LLMs can serve as a valuable tool for automated argument quality assessment, thus streamlining and accelerating the evaluation of large argument datasets.
Task-Oriented Paraphrase Analytics
Mar 26, 2024



Since paraphrasing is an ill-defined task, the term "paraphrasing" covers text transformation tasks with different characteristics. Consequently, existing paraphrasing studies have applied quite different (explicit and implicit) criteria as to when a pair of texts is to be considered a paraphrase, all of which amount to postulating a certain level of semantic or lexical similarity. In this paper, we conduct a literature review and propose a taxonomy to organize the 25~identified paraphrasing (sub-)tasks. Using classifiers trained to identify the tasks that a given paraphrasing instance fits, we find that the distributions of task-specific instances in the known paraphrase corpora vary substantially. This means that the use of these corpora, without the respective paraphrase conditions being clearly defined (which is the normal case), must lead to incomparable and misleading results.
Assisted Knowledge Graph Authoring: Human-Supervised Knowledge Graph Construction from Natural Language
Jan 15, 2024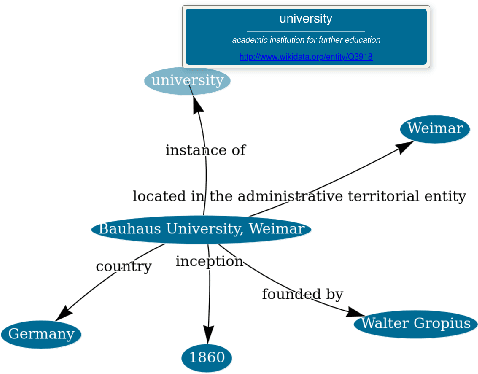


Encyclopedic knowledge graphs, such as Wikidata, host an extensive repository of millions of knowledge statements. However, domain-specific knowledge from fields such as history, physics, or medicine is significantly underrepresented in those graphs. Although few domain-specific knowledge graphs exist (e.g., Pubmed for medicine), developing specialized retrieval applications for many domains still requires constructing knowledge graphs from scratch. To facilitate knowledge graph construction, we introduce WAKA: a Web application that allows domain experts to create knowledge graphs through the medium with which they are most familiar: natural language.
Paraphrase Acquisition from Image Captions
Jan 26, 2023

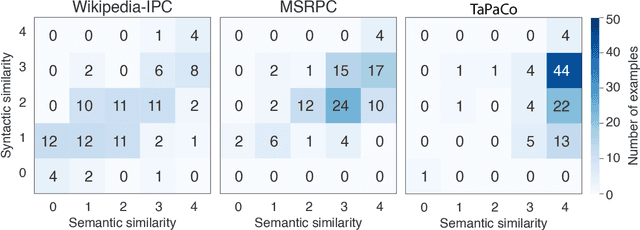
We propose to use captions from the Web as a previously underutilized resource for paraphrases (i.e., texts with the same "message") and to create and analyze a corresponding dataset. When an image is reused on the Web, an original caption is often assigned. We hypothesize that different captions for the same image naturally form a set of mutual paraphrases. To demonstrate the suitability of this idea, we analyze captions in the English Wikipedia, where editors frequently relabel the same image for different articles. The paper introduces the underlying mining technology and compares known paraphrase corpora with respect to their syntactic and semantic paraphrase similarity to our new resource. In this context, we introduce characteristic maps along the two similarity dimensions to identify the style of paraphrases coming from different sources. An annotation study demonstrates the high reliability of the algorithmically determined characteristic maps.
Entity-Based Query Interpretation
May 18, 2021


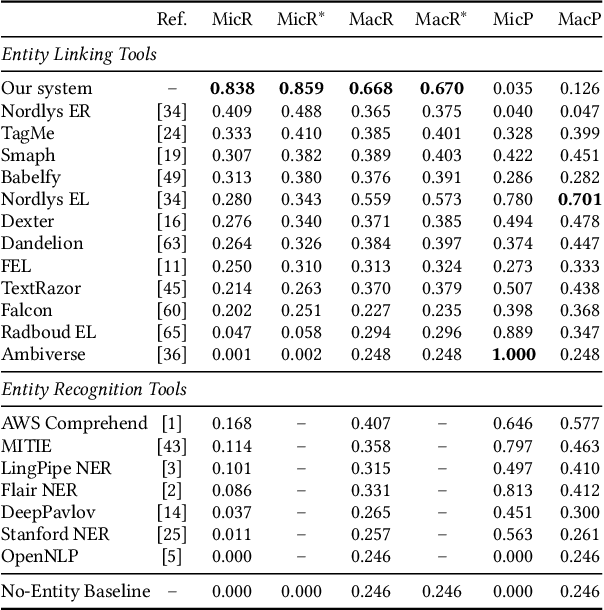
Web search queries can be rather ambiguous: Is "paris hilton" meant to find the latest news on the celebrity or to find a specific hotel in Paris? And in which of the worldwide more than 20 "Parises"? We propose to solve this ambiguity problem by deriving entity-based query interpretations: given some query, the task is to link suitable parts of the query to semantically compatible entities in a background knowledge base. Our suggested approach to identify the most reasonable interpretations of a query based on the contained entities focuses on effectiveness but also on efficiency since web search response times should not exceed some hundreds of milliseconds. In our approach, we propose to use query segmentation as a pre-processing step that finds promising segment-based "skeletons". These skeletons are then enhanced to "interpretations" by linking the contained segments to entities from a knowledge base and then ranking the interpretations in a final step. An experimental comparison on a corpus of 2,800 queries shows our approach to have a better interpretation accuracy at a better run time than the previously most effective query entity linking methods.