 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study on Chinese Character Decomposition in Multiword Expression-Aware Neural Machine Translation
Dec 17, 2025
Word meaning, representation, and interpretation play fundamental roles in natural language understanding (NLU), natural language processing (NLP), and natural language generation (NLG) tasks. Many of the inherent difficulties in these tasks stem from Multi-word Expressions (MWEs), which complicate the tasks by introducing ambiguity, idiomatic expressions, infrequent usage, and a wide range of variations. Significant effort and substantial progress have been made in addressing the challenging nature of MWEs in Western languages, particularly English. This progress is attributed in part to the well-established research communities and the abundant availability of computational resources. However, the same level of progress is not true for language families such as Chinese and closely related Asian languages, which continue to lag behind in this regard. While sub-word modelling has been successfully applied to many Western languages to address rare words improving phrase comprehension, and enhancing machine translation (MT) through techniques like byte-pair encoding (BPE), it cannot be applied directly to ideograph language scripts like Chinese. In this work, we conduct a systematic study of the Chinese character decomposition technology in the context of MWE-aware neural machine translation (NMT). Furthermore, we report experiments to examine how Chinese character decomposition technology contributes to the representation of the original meanings of Chinese words and characters, and how it can effectively address the challenges of translating MWEs.
Report on the Workshop on Simulations for Information Access (Sim4IA 2024) at SIGIR 2024
Sep 26, 2024



This paper is a report of the Workshop on Simulations for Information Access (Sim4IA) workshop at SIGIR 2024. The workshop had two keynotes, a panel discussion, nine lightning talks, and two breakout sessions. Key takeaways were user simulation's importance in academia and industry, the possible bridging of online and offline evaluation, and the issues of organizing a companion shared task around user simulations for information access. We report on how we organized the workshop, provide a brief overview of what happened at the workshop, and summarize the main topics and findings of the workshop and future work.
Examining the Potential for Conversational Exploratory Search using a Smart Speaker Digital Assistant
Mar 18, 2023



Online Digital Assistants, such as Amazon Alexa, Google Assistant, Apple Siri are very popular and provide a range or services to their users, a key function is their ability to satisfy user information needs from the sources available to them. Users may often regard these applications as providing search services similar to Google type search engines. However, while it is clear that they are in general able to answer factoid questions effectively, it is much less obvious how well they support less specific or exploratory type search tasks. We describe an investigation examining the behaviour of the standard Amazon Alexa for exploratory search tasks. The results of our study show that it not effective in addressing these types of information needs. We propose extensions to Alexa designed to overcome these shortcomings. Our Custom Alexa application extends Alexa's conversational functionality for exploratory search. A user study shows that our extended Alexa application both enables users to more successfully complete exploratory search tasks and is well accepted by our test users.
Achieving Reliable Human Assessment of Open-Domain Dialogue Systems
Mar 11, 2022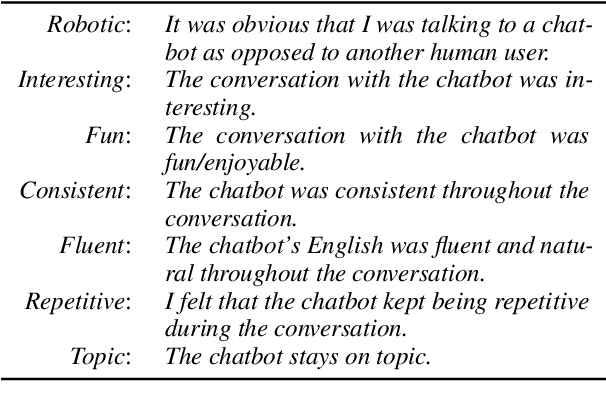

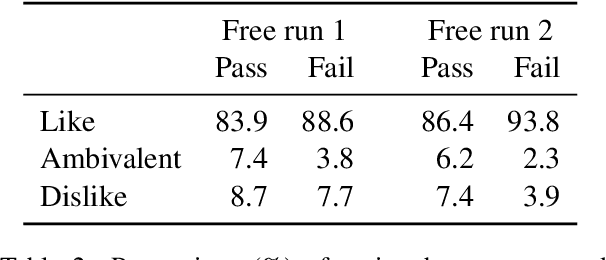
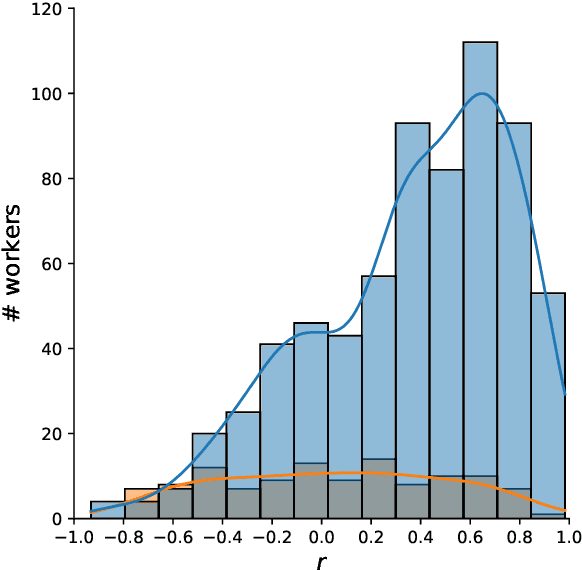
Evaluation of open-domain dialogue systems is highly challenging and development of better techniques is highlighted time and again as desperately needed. Despite substantial efforts to carry out reliable live evaluation of systems in recent competitions, annotations have been abandoned and reported as too unreliable to yield sensible results. This is a serious problem since automatic metrics are not known to provide a good indication of what may or may not be a high-quality conversation. Answering the distress call of competitions that have emphasized the urgent need for better evaluation techniques in dialogue, we present the successful development of human evaluation that is highly reliable while still remaining feasible and low cost. Self-replication experiments reveal almost perfectly repeatable results with a correlation of $r=0.969$. Furthermore, due to the lack of appropriate methods of statistical significance testing, the likelihood of potential improvements to systems occurring due to chance is rarely taken into account in dialogue evaluation, and the evaluation we propose facilitates application of standard tests. Since we have developed a highly reliable evaluation method, new insights into system performance can be revealed. We therefore include a comparison of state-of-the-art models (i) with and without personas, to measure the contribution of personas to conversation quality, as well as (ii) prescribed versus freely chosen topics. Interestingly with respect to personas, results indicate that personas do not positively contribute to conversation quality as expected.
Translation Quality Assessment: A Brief Survey on Manual and Automatic Methods
May 05, 2021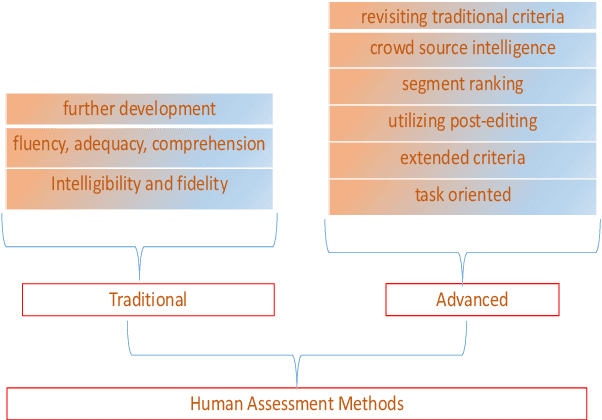
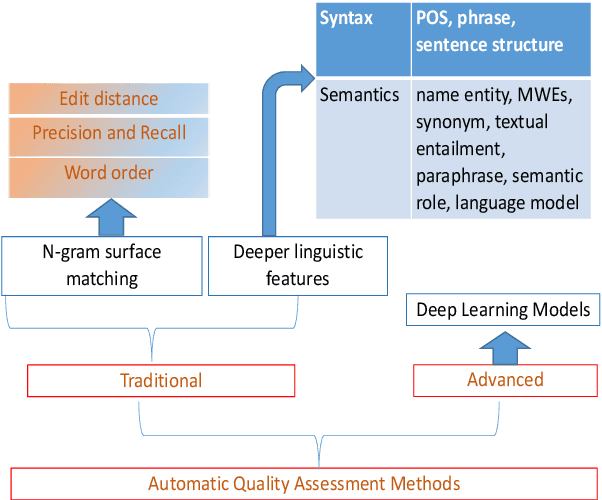
To facilitate effective translation modeling and translation studies, one of the crucial questions to address is how to assess translation quality. From the perspectives of accuracy, reliability, repeatability and cost, translation quality assessment (TQA) itself is a rich and challenging task. In this work, we present a high-level and concise survey of TQA methods, including both manual judgement criteria and automated evaluation metrics, which we classify into further detailed sub-categories. We hope that this work will be an asset for both translation model researchers and quality assessment researchers. In addition, we hope that it will enable practitioners to quickly develop a better understanding of the conventional TQA field, and to find corresponding closely relevant evaluation solutions for their own needs. This work may also serve inspire further development of quality assessment and evaluation methodologies for other natural language processing (NLP) tasks in addition to machine translation (MT), such as automatic text summarization (ATS), natural language understanding (NLU) and natural language generation (NLG).
TRECVID 2020: A comprehensive campaign for evaluating video retrieval tasks across multiple application domains
Apr 27, 2021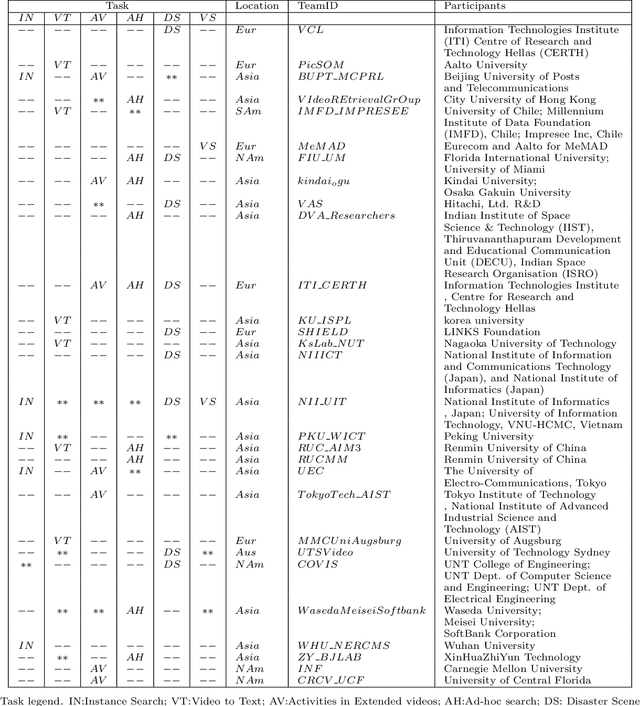

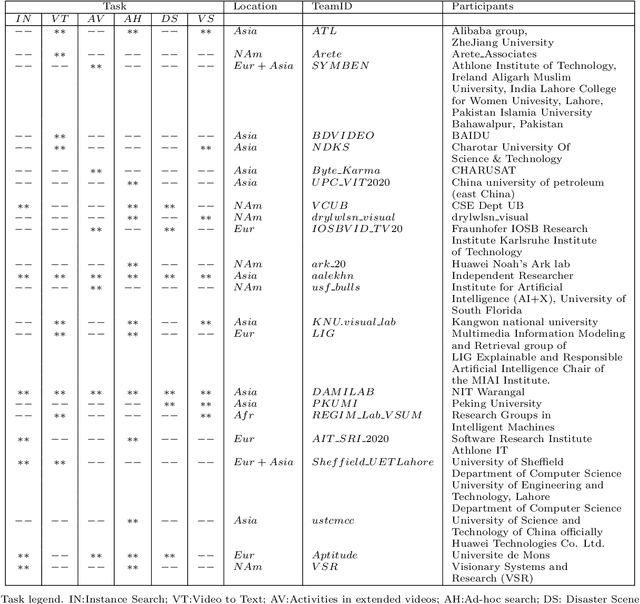
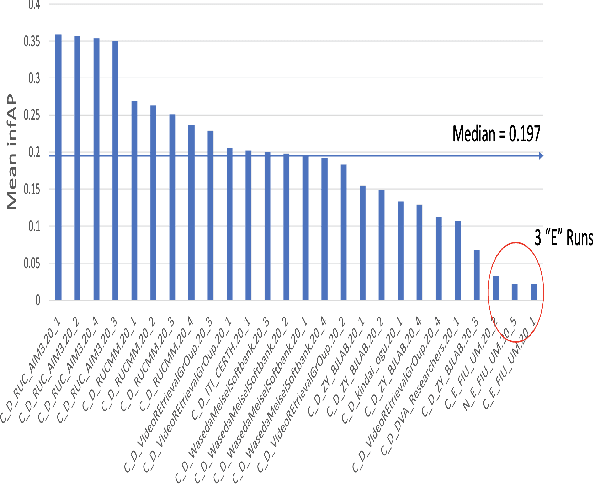
The TREC Video Retrieval Evaluation (TRECVID) is a TREC-style video analysis and retrieval evaluation with the goal of promoting progress in research and development of content-based exploitation and retrieval of information from digital video via open, metrics-based evaluation. Over the last twenty years this effort has yielded a better understanding of how systems can effectively accomplish such processing and how one can reliably benchmark their performance. TRECVID has been funded by NIST (National Institute of Standards and Technology) and other US government agencies. In addition, many organizations and individuals worldwide contribute significant time and effort. TRECVID 2020 represented a continuation of four tasks and the addition of two new tasks. In total, 29 teams from various research organizations worldwide completed one or more of the following six tasks: 1. Ad-hoc Video Search (AVS), 2. Instance Search (INS), 3. Disaster Scene Description and Indexing (DSDI), 4. Video to Text Description (VTT), 5. Activities in Extended Video (ActEV), 6. Video Summarization (VSUM). This paper is an introduction to the evaluation framework, tasks, data, and measures used in the evaluation campaign.
Exploring Current User Web Search Behaviours in Analysis Tasks to be Supported in Conversational Search
Apr 09, 2021

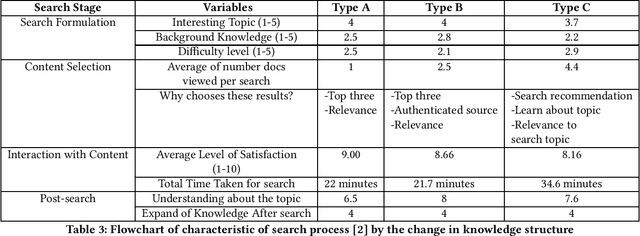

Conversational search presents opportunities to support users in their search activities to improve the effectiveness and efficiency of search while reducing their cognitive load. Limitations of the potential competency of conversational agents restrict the situations for which conversational search agents can replace human intermediaries. It is thus more interesting, initially at least, to investigate opportunities for conversational interaction to support less complex information retrieval tasks, such as typical web search, which do not require human-level intelligence in the conversational agent. In order to move towards the development of a system to enable conversational search of this type, we need to understand their required capabilities. To progress our understanding of these, we report a study examining the behaviour of users when using a standard web search engine, designed to enable us to identify opportunities to support their search activities using a conversational agent.
Chinese Character Decomposition for Neural MT with Multi-Word Expressions
Apr 09, 2021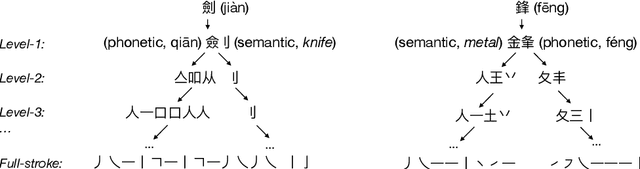
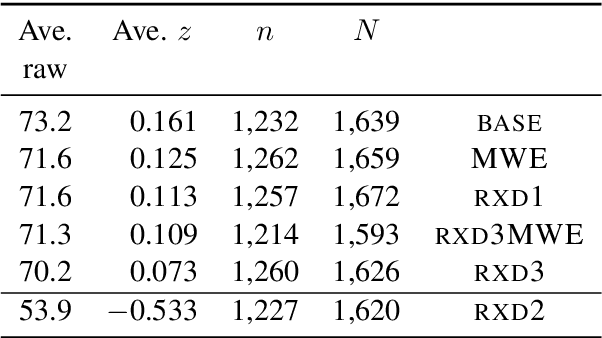
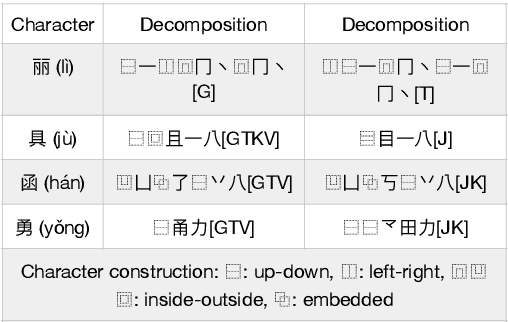
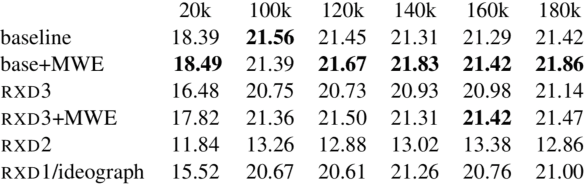
Chinese character decomposition has been used as a feature to enhance Machine Translation (MT) models, combining radicals into character and word level models. Recent work has investigated ideograph or stroke level embedding. However, questions remain about different decomposition levels of Chinese character representations, radical and strokes, best suited for MT. To investigate the impact of Chinese decomposition embedding in detail, i.e., radical, stroke, and intermediate levels, and how well these decompositions represent the meaning of the original character sequences, we carry out analysis with both automated and human evaluation of MT. Furthermore, we investigate if the combination of decomposed Multiword Expressions (MWEs) can enhance the model learning. MWE integration into MT has seen more than a decade of exploration. However, decomposed MWEs has not previously been explored.
A Conceptual Framework for Implicit Evaluation of Conversational Search Interfaces
Apr 08, 2021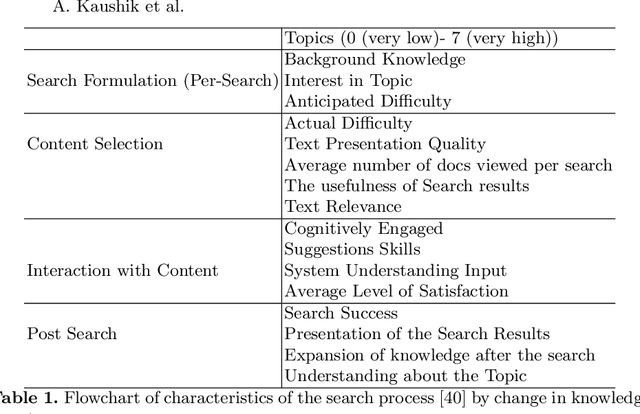
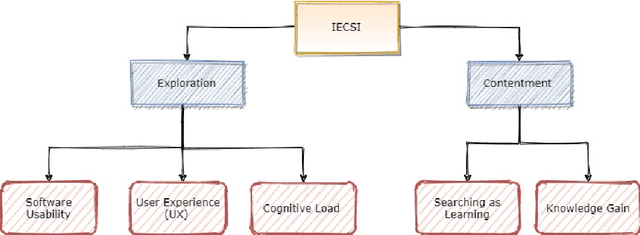
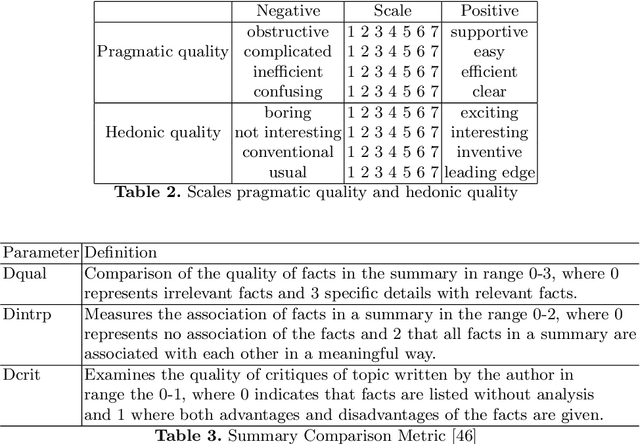
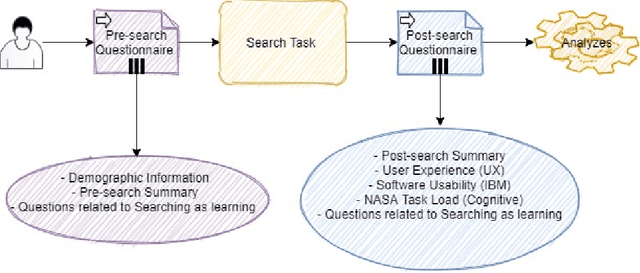
Conversational search (CS) has recently become a significant focus of the information retrieval (IR) research community. Multiple studies have been conducted which explore the concept of conversational search. Understanding and advancing research in CS requires careful and detailed evaluation. Existing CS studies have been limited to evaluation based on simple user feedback on task completion. We propose a CS evaluation framework which includes multiple dimensions: search experience, knowledge gain, software usability, cognitive load and user experience, based on studies of conversational systems and IR. We introduce these evaluation criteria and propose their use in a framework for the evaluation of CS systems.
TREC 2020 Podcasts Track Overview
Mar 29, 2021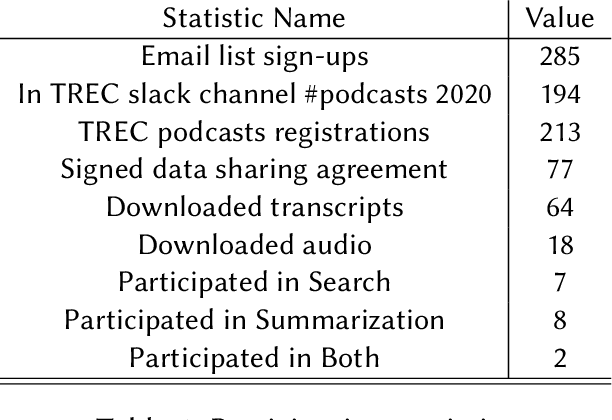
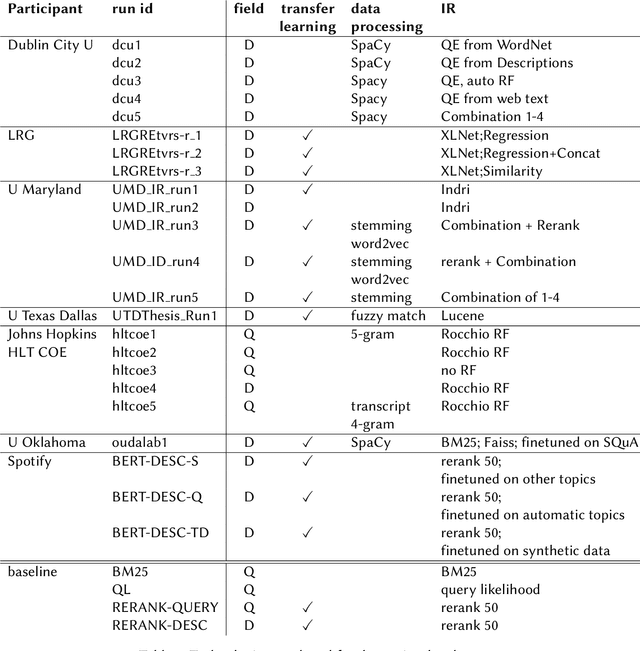
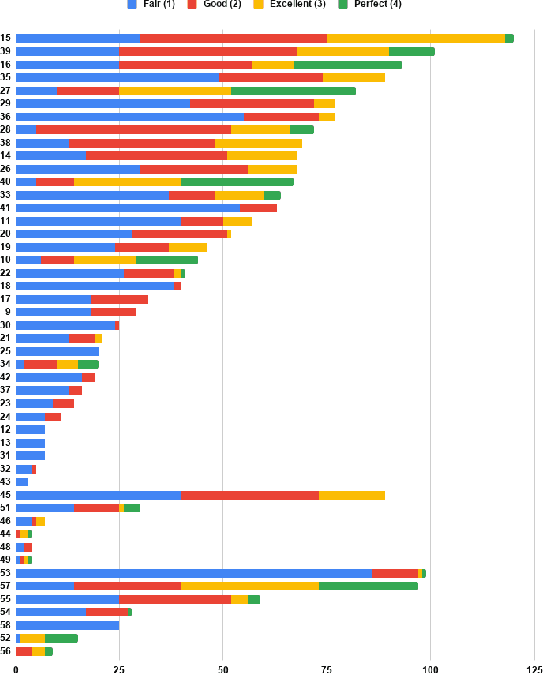
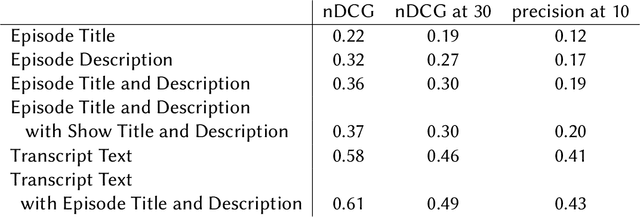
The Podcast Track is new at the Text Retrieval Conference (TREC) in 2020. The podcast track was designed to encourage research into podcasts in the information retrieval and NLP research communities. The track consisted of two shared tasks: segment retrieval and summarization, both based on a dataset of over 100,000 podcast episodes (metadata, audio, and automatic transcripts) which was released concurrently with the track. The track generated considerable interest, attracted hundreds of new registrations to TREC and fifteen teams, mostly disjoint between search and summarization, made final submissions for assessment. Deep learning was the dominant experimental approach for both search experiments and summarization. This paper gives an overview of the tasks and the results of the participants' experiments. The track will return to TREC 2021 with the same two tasks, incorporating slight modifications in response to participant feedback.