 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePodcast Metadata and Content: Episode Relevance andAttractiveness in Ad Hoc Search
Aug 25, 2021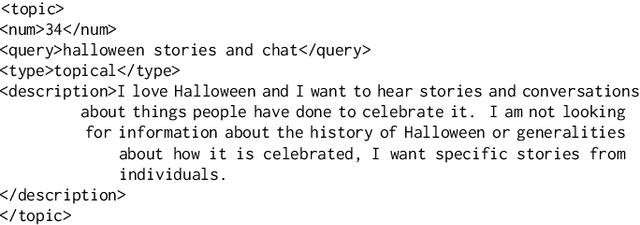

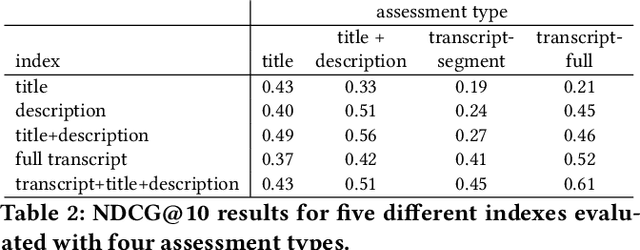
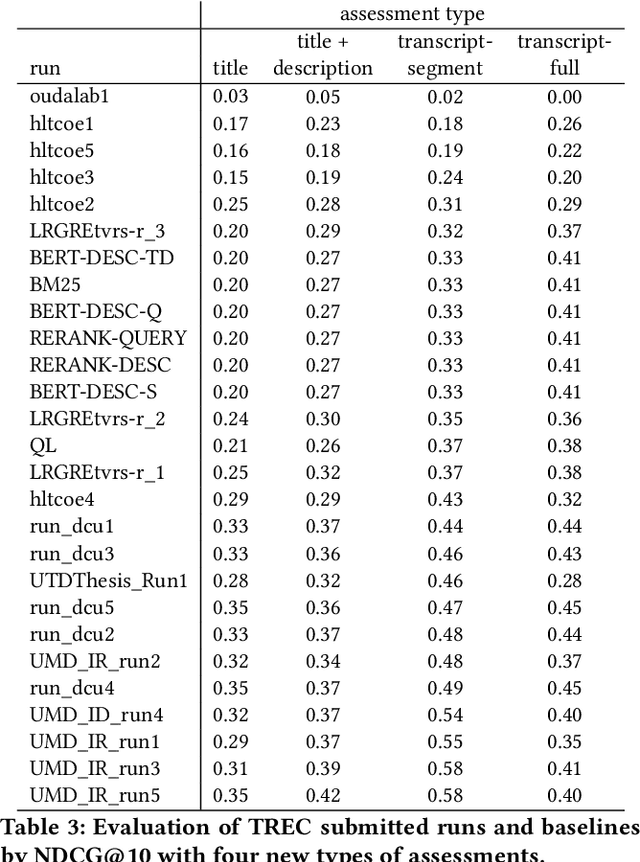
Rapidly growing online podcast archives contain diverse content on a wide range of topics. These archives form an important resource for entertainment and professional use, but their value can only be realized if users can rapidly and reliably locate content of interest. Search for relevant content can be based on metadata provided by content creators, but also on transcripts of the spoken content itself. Excavating relevant content from deep within these audio streams for diverse types of information needs requires varying the approach to systems prototyping. We describe a set of diverse podcast information needs and different approaches to assessing retrieved content for relevance. We use these information needs in an investigation of the utility and effectiveness of these information sources. Based on our analysis, we recommend approaches for indexing and retrieving podcast content for ad hoc search.
Modeling Language Usage and Listener Engagement in Podcasts
Jun 11, 2021

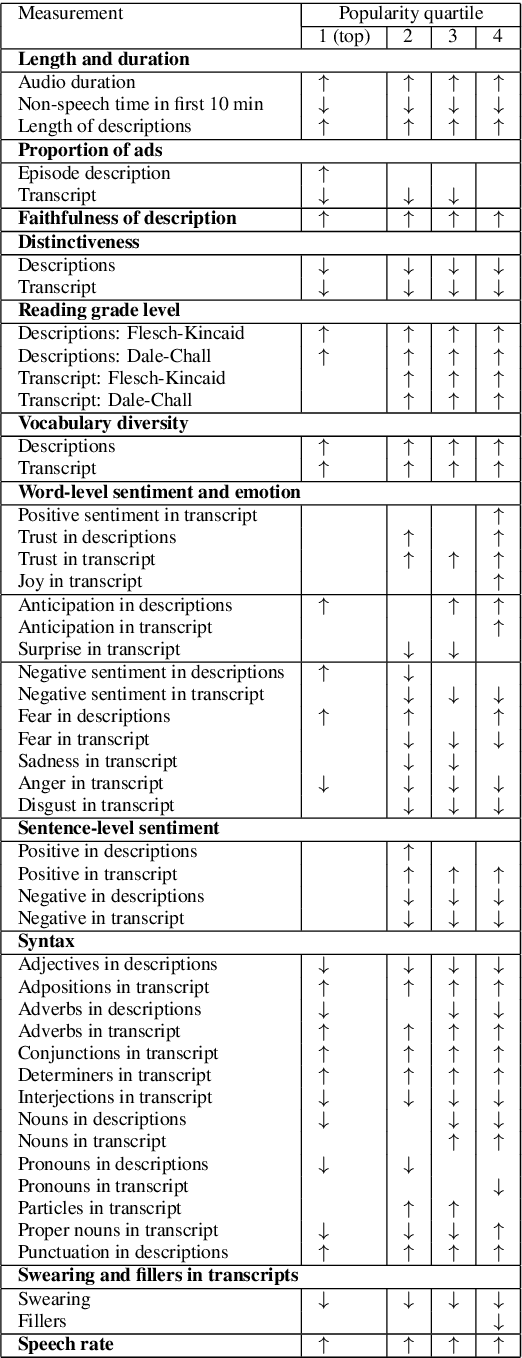
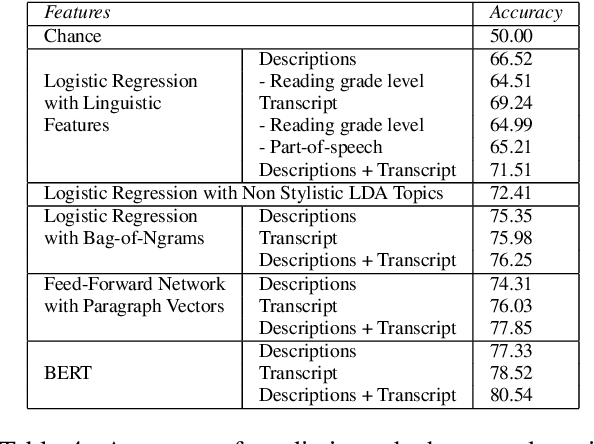
While there is an abundance of popular writing targeted to podcast creators on how to speak in ways that engage their listeners, there has been little data-driven analysis of podcasts that relates linguistic style with listener engagement. In this paper, we investigate how various factors -- vocabulary diversity, distinctiveness, emotion, and syntax, among others -- correlate with engagement, based on analysis of the creators' written descriptions and transcripts of the audio. We build models with different textual representations, and show that the identified features are highly predictive of engagement. Our analysis tests popular wisdom about stylistic elements in high-engagement podcasts, corroborating some aspects, and adding new perspectives on others.
TREC 2020 Podcasts Track Overview
Mar 29, 2021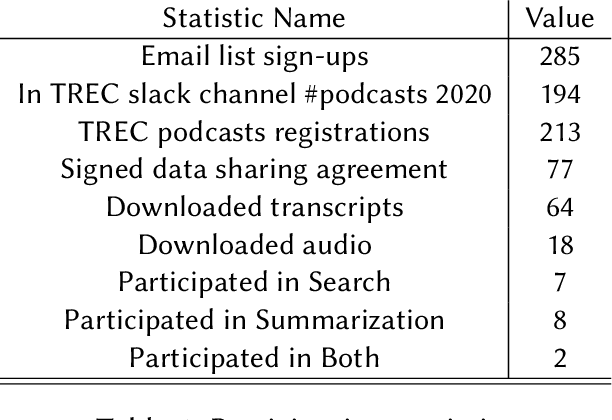
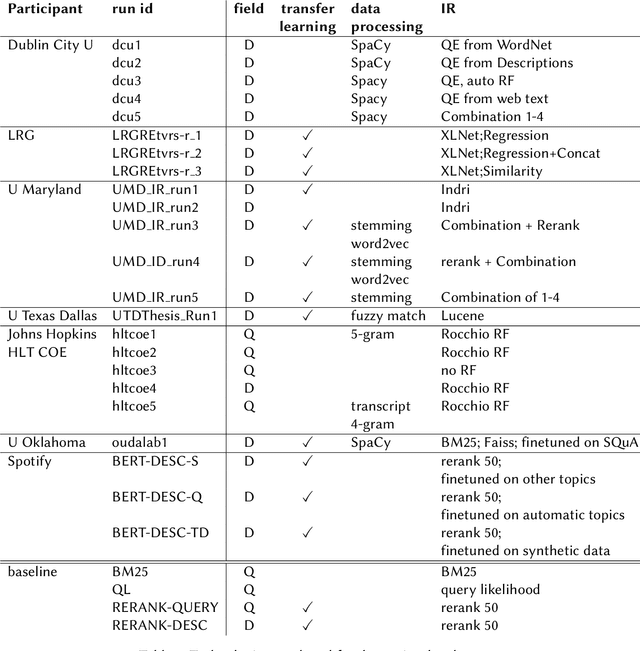
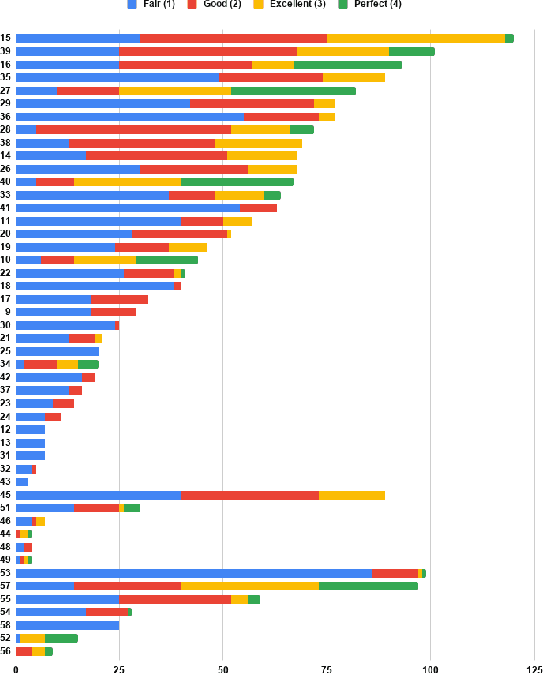
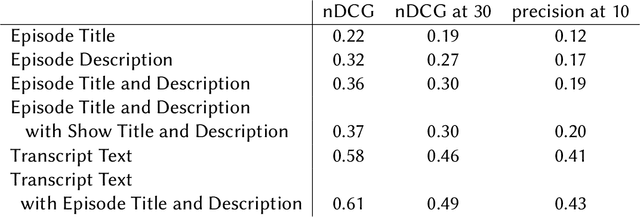
The Podcast Track is new at the Text Retrieval Conference (TREC) in 2020. The podcast track was designed to encourage research into podcasts in the information retrieval and NLP research communities. The track consisted of two shared tasks: segment retrieval and summarization, both based on a dataset of over 100,000 podcast episodes (metadata, audio, and automatic transcripts) which was released concurrently with the track. The track generated considerable interest, attracted hundreds of new registrations to TREC and fifteen teams, mostly disjoint between search and summarization, made final submissions for assessment. Deep learning was the dominant experimental approach for both search experiments and summarization. This paper gives an overview of the tasks and the results of the participants' experiments. The track will return to TREC 2021 with the same two tasks, incorporating slight modifications in response to participant feedback.
Detecting Extraneous Content in Podcasts
Mar 03, 2021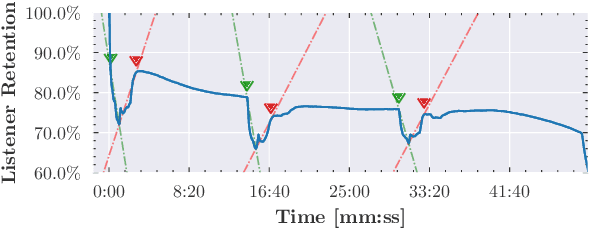
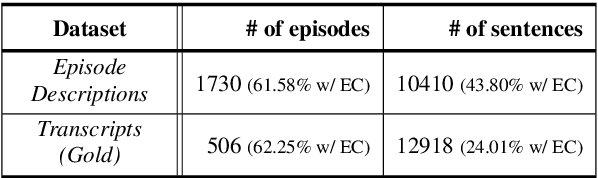
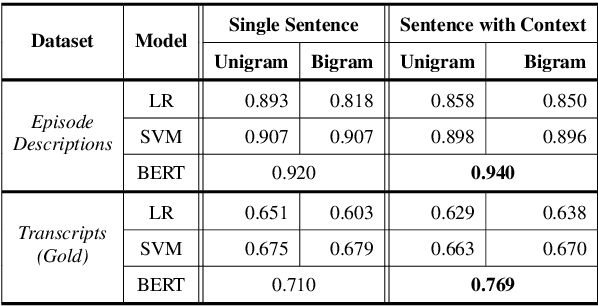
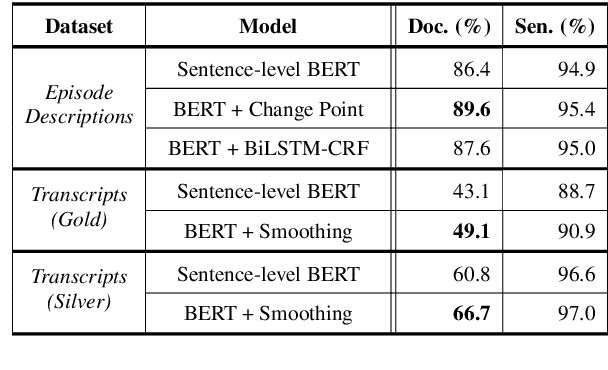
Podcast episodes often contain material extraneous to the main content, such as advertisements, interleaved within the audio and the written descriptions. We present classifiers that leverage both textual and listening patterns in order to detect such content in podcast descriptions and audio transcripts. We demonstrate that our models are effective by evaluating them on the downstream task of podcast summarization and show that we can substantively improve ROUGE scores and reduce the extraneous content generated in the summaries.
The Spotify Podcasts Dataset
Apr 08, 2020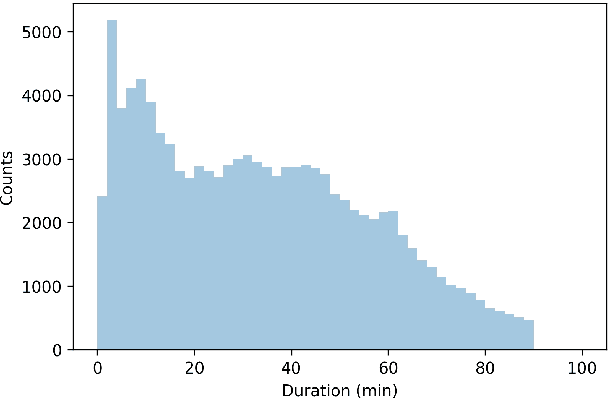
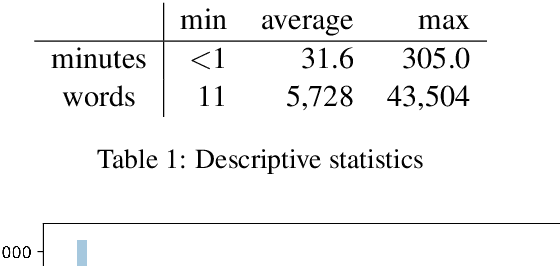

Podcasts are a relatively new form of audio media. Episodes appear on a regular cadence, and come in many different formats and levels of formality. They can be formal news journalism or conversational chat; fiction or non-fiction. They are rapidly growing in popularity and yet have been relatively little studied. As an audio format, podcasts are more varied in style and production types than, say, broadcast news, and contain many more genres than typically studied in video research. The medium is therefore a rich domain with many research avenues for the IR and NLP communities. We present the Spotify Podcasts Dataset, a set of approximately 100K podcast episodes comprised of raw audio files along with accompanying ASR transcripts. This represents over 47,000 hours of transcribed audio, and is an order of magnitude larger than previous speech-to-text corpora.