 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePODTILE: Facilitating Podcast Episode Browsing with Auto-generated Chapters
Oct 21, 2024


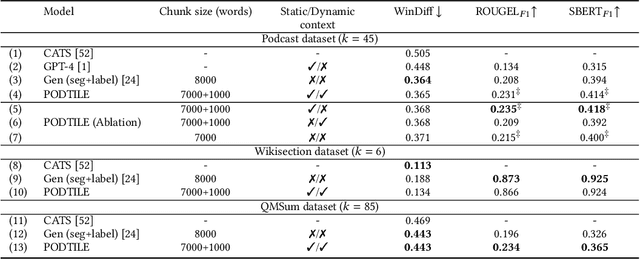
Listeners of long-form talk-audio content, such as podcast episodes, often find it challenging to understand the overall structure and locate relevant sections. A practical solution is to divide episodes into chapters--semantically coherent segments labeled with titles and timestamps. Since most episodes on our platform at Spotify currently lack creator-provided chapters, automating the creation of chapters is essential. Scaling the chapterization of podcast episodes presents unique challenges. First, episodes tend to be less structured than written texts, featuring spontaneous discussions with nuanced transitions. Second, the transcripts are usually lengthy, averaging about 16,000 tokens, which necessitates efficient processing that can preserve context. To address these challenges, we introduce PODTILE, a fine-tuned encoder-decoder transformer to segment conversational data. The model simultaneously generates chapter transitions and titles for the input transcript. To preserve context, each input text is augmented with global context, including the episode's title, description, and previous chapter titles. In our intrinsic evaluation, PODTILE achieved an 11% improvement in ROUGE score over the strongest baseline. Additionally, we provide insights into the practical benefits of auto-generated chapters for listeners navigating episode content. Our findings indicate that auto-generated chapters serve as a useful tool for engaging with less popular podcasts. Finally, we present empirical evidence that using chapter titles can enhance effectiveness of sparse retrieval in search tasks.
Long-term Off-Policy Evaluation and Learning
Apr 24, 2024



Short- and long-term outcomes of an algorithm often differ, with damaging downstream effects. A known example is a click-bait algorithm, which may increase short-term clicks but damage long-term user engagement. A possible solution to estimate the long-term outcome is to run an online experiment or A/B test for the potential algorithms, but it takes months or even longer to observe the long-term outcomes of interest, making the algorithm selection process unacceptably slow. This work thus studies the problem of feasibly yet accurately estimating the long-term outcome of an algorithm using only historical and short-term experiment data. Existing approaches to this problem either need a restrictive assumption about the short-term outcomes called surrogacy or cannot effectively use short-term outcomes, which is inefficient. Therefore, we propose a new framework called Long-term Off-Policy Evaluation (LOPE), which is based on reward function decomposition. LOPE works under a more relaxed assumption than surrogacy and effectively leverages short-term rewards to substantially reduce the variance. Synthetic experiments show that LOPE outperforms existing approaches particularly when surrogacy is severely violated and the long-term reward is noisy. In addition, real-world experiments on large-scale A/B test data collected on a music streaming platform show that LOPE can estimate the long-term outcome of actual algorithms more accurately than existing feasible methods.
Distributionally-Informed Recommender System Evaluation
Sep 12, 2023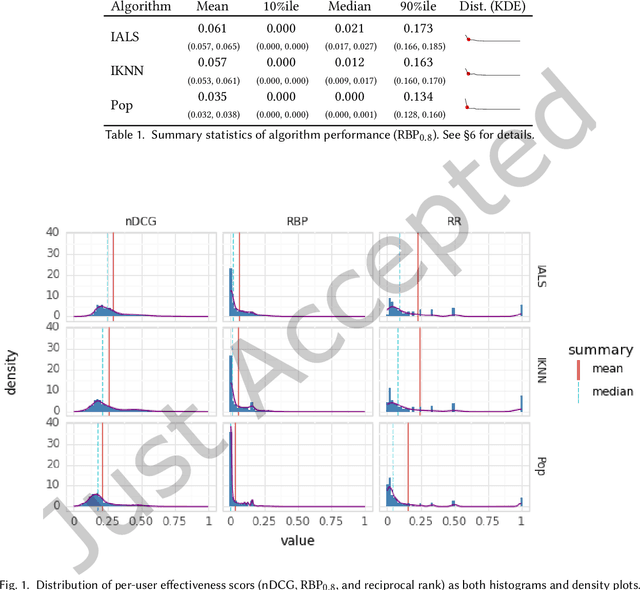
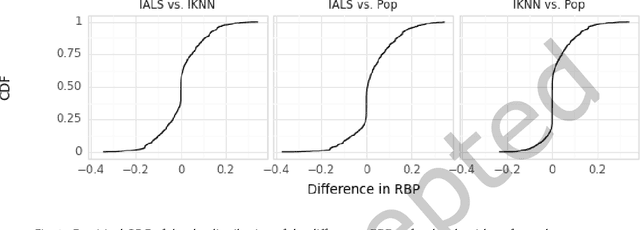
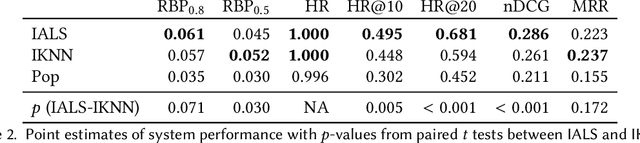
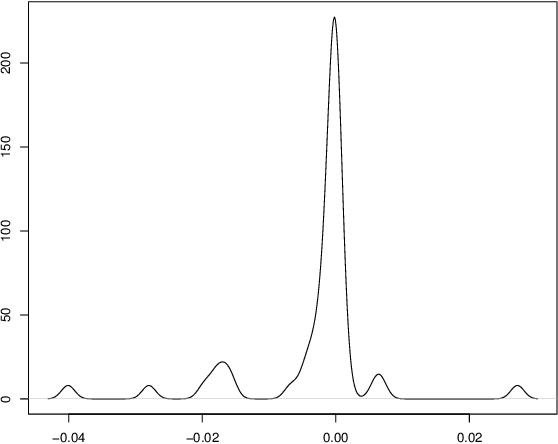
Current practice for evaluating recommender systems typically focuses on point estimates of user-oriented effectiveness metrics or business metrics, sometimes combined with additional metrics for considerations such as diversity and novelty. In this paper, we argue for the need for researchers and practitioners to attend more closely to various distributions that arise from a recommender system (or other information access system) and the sources of uncertainty that lead to these distributions. One immediate implication of our argument is that both researchers and practitioners must report and examine more thoroughly the distribution of utility between and within different stakeholder groups. However, distributions of various forms arise in many more aspects of the recommender systems experimental process, and distributional thinking has substantial ramifications for how we design, evaluate, and present recommender systems evaluation and research results. Leveraging and emphasizing distributions in the evaluation of recommender systems is a necessary step to ensure that the systems provide appropriate and equitably-distributed benefit to the people they affect.
Report from Dagstuhl Seminar 23031: Frontiers of Information Access Experimentation for Research and Education
Apr 18, 2023



This report documents the program and the outcomes of Dagstuhl Seminar 23031 ``Frontiers of Information Access Experimentation for Research and Education'', which brought together 37 participants from 12 countries. The seminar addressed technology-enhanced information access (information retrieval, recommender systems, natural language processing) and specifically focused on developing more responsible experimental practices leading to more valid results, both for research as well as for scientific education. The seminar brought together experts from various sub-fields of information access, namely IR, RS, NLP, information science, and human-computer interaction to create a joint understanding of the problems and challenges presented by next generation information access systems, from both the research and the experimentation point of views, to discuss existing solutions and impediments, and to propose next steps to be pursued in the area in order to improve not also our research methods and findings but also the education of the new generation of researchers and developers. The seminar featured a series of long and short talks delivered by participants, who helped in setting a common ground and in letting emerge topics of interest to be explored as the main output of the seminar. This led to the definition of five groups which investigated challenges, opportunities, and next steps in the following areas: reality check, i.e. conducting real-world studies, human-machine-collaborative relevance judgment frameworks, overcoming methodological challenges in information retrieval and recommender systems through awareness and education, results-blind reviewing, and guidance for authors.
Podcast Metadata and Content: Episode Relevance andAttractiveness in Ad Hoc Search
Aug 25, 2021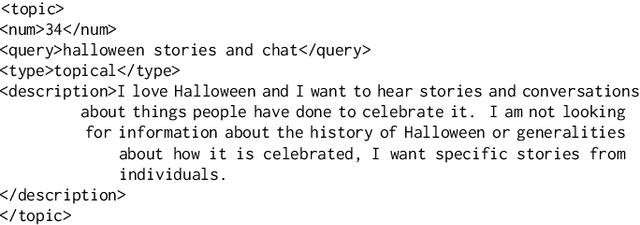

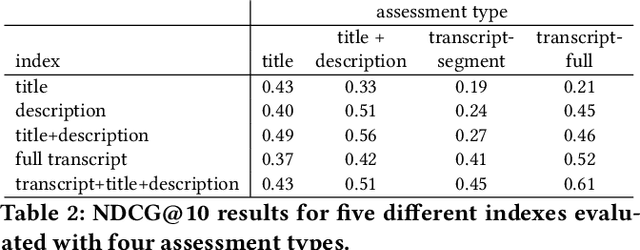
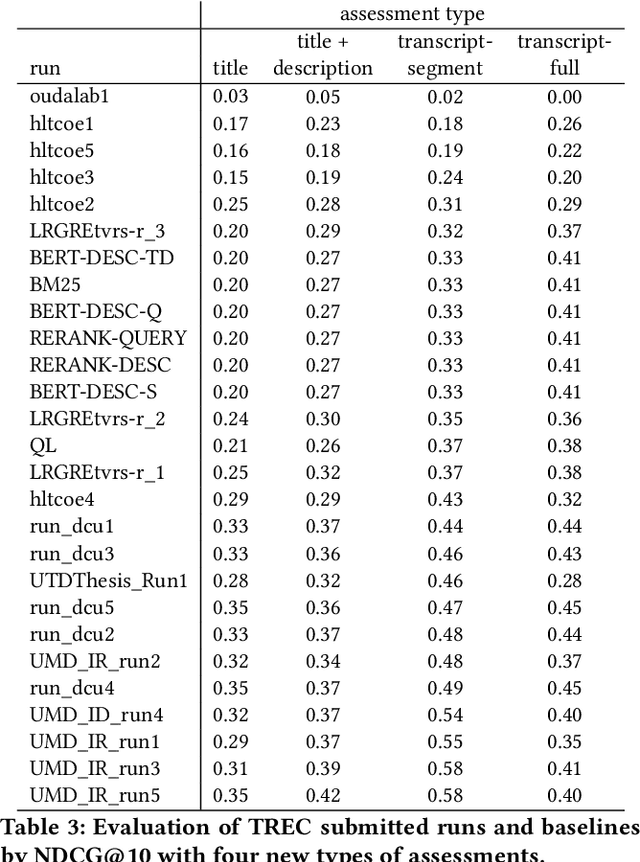
Rapidly growing online podcast archives contain diverse content on a wide range of topics. These archives form an important resource for entertainment and professional use, but their value can only be realized if users can rapidly and reliably locate content of interest. Search for relevant content can be based on metadata provided by content creators, but also on transcripts of the spoken content itself. Excavating relevant content from deep within these audio streams for diverse types of information needs requires varying the approach to systems prototyping. We describe a set of diverse podcast information needs and different approaches to assessing retrieved content for relevance. We use these information needs in an investigation of the utility and effectiveness of these information sources. Based on our analysis, we recommend approaches for indexing and retrieving podcast content for ad hoc search.
Estimation of Fair Ranking Metrics with Incomplete Judgments
Aug 11, 2021
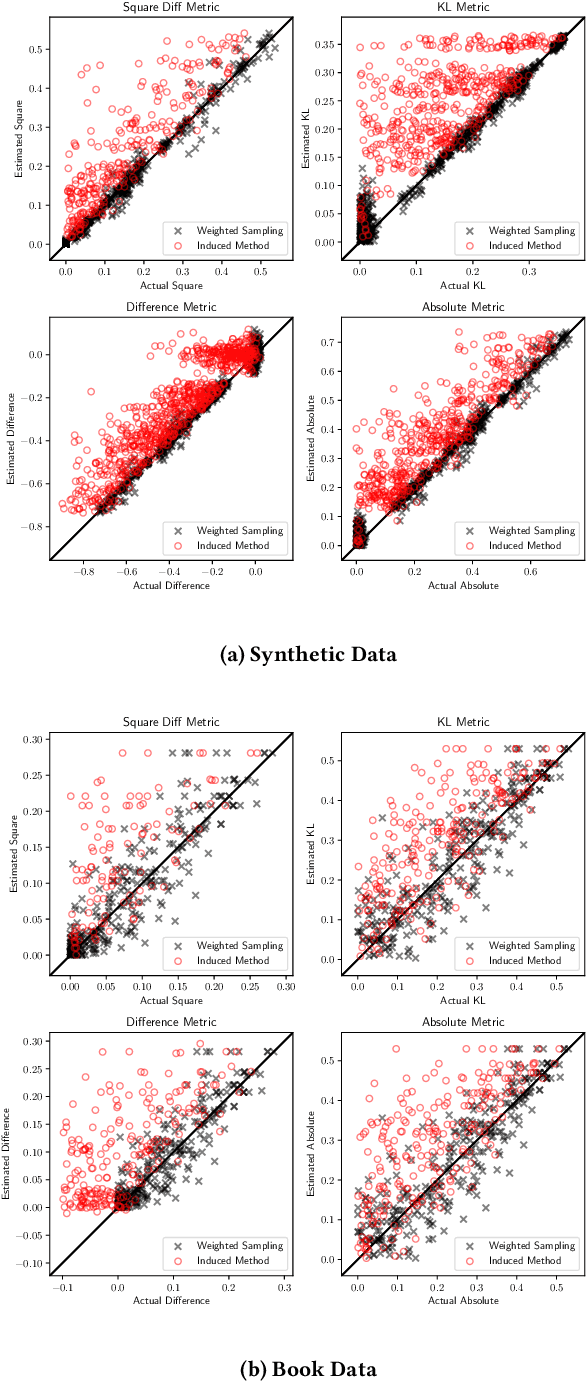
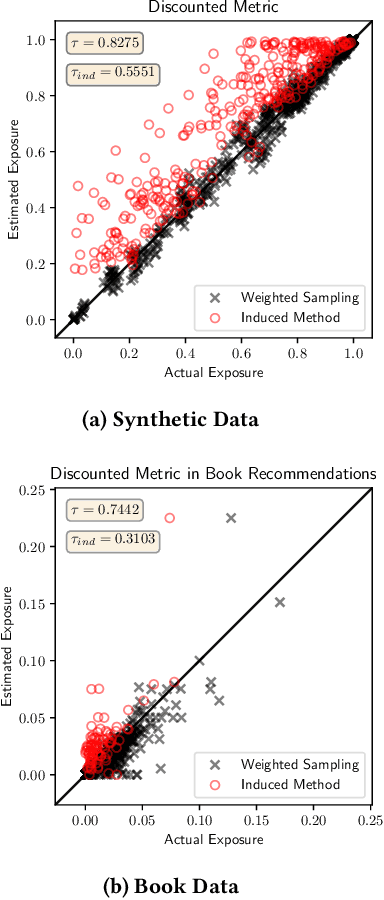

There is increasing attention to evaluating the fairness of search system ranking decisions. These metrics often consider the membership of items to particular groups, often identified using protected attributes such as gender or ethnicity. To date, these metrics typically assume the availability and completeness of protected attribute labels of items. However, the protected attributes of individuals are rarely present, limiting the application of fair ranking metrics in large scale systems. In order to address this problem, we propose a sampling strategy and estimation technique for four fair ranking metrics. We formulate a robust and unbiased estimator which can operate even with very limited number of labeled items. We evaluate our approach using both simulated and real world data. Our experimental results demonstrate that our method can estimate this family of fair ranking metrics and provides a robust, reliable alternative to exhaustive or random data annotation.
Current Challenges and Future Directions in Podcast Information Access
Jun 17, 2021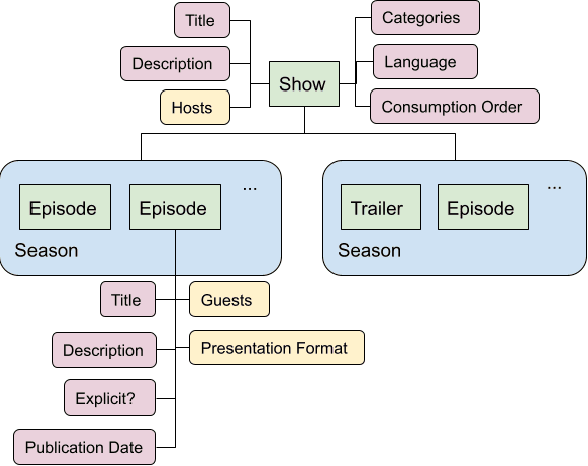
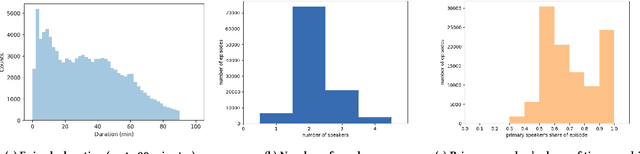
Podcasts are spoken documents across a wide-range of genres and styles, with growing listenership across the world, and a rapidly lowering barrier to entry for both listeners and creators. The great strides in search and recommendation in research and industry have yet to see impact in the podcast space, where recommendations are still largely driven by word of mouth. In this perspective paper, we highlight the many differences between podcasts and other media, and discuss our perspective on challenges and future research directions in the domain of podcast information access.
Model Selection for Production System via Automated Online Experiments
May 27, 2021
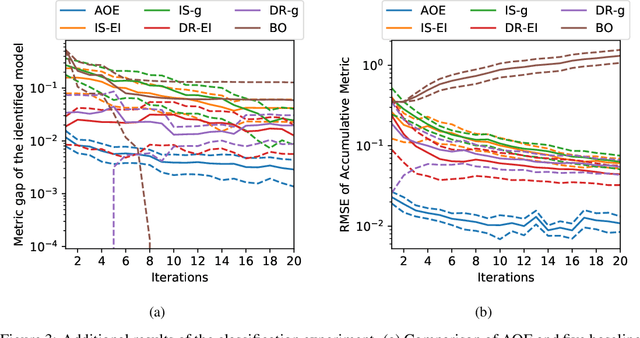
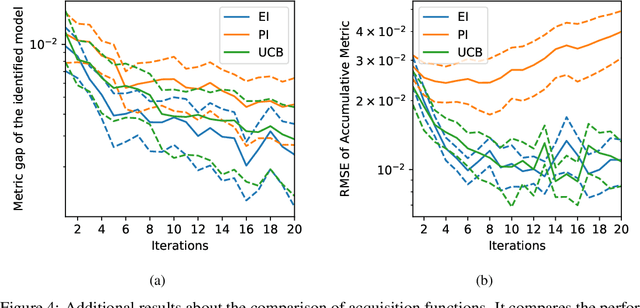
A challenge that machine learning practitioners in the industry face is the task of selecting the best model to deploy in production. As a model is often an intermediate component of a production system, online controlled experiments such as A/B tests yield the most reliable estimation of the effectiveness of the whole system, but can only compare two or a few models due to budget constraints. We propose an automated online experimentation mechanism that can efficiently perform model selection from a large pool of models with a small number of online experiments. We derive the probability distribution of the metric of interest that contains the model uncertainty from our Bayesian surrogate model trained using historical logs. Our method efficiently identifies the best model by sequentially selecting and deploying a list of models from the candidate set that balance exploration-exploitation. Using simulations based on real data, we demonstrate the effectiveness of our method on two different tasks.
TREC 2020 Podcasts Track Overview
Mar 29, 2021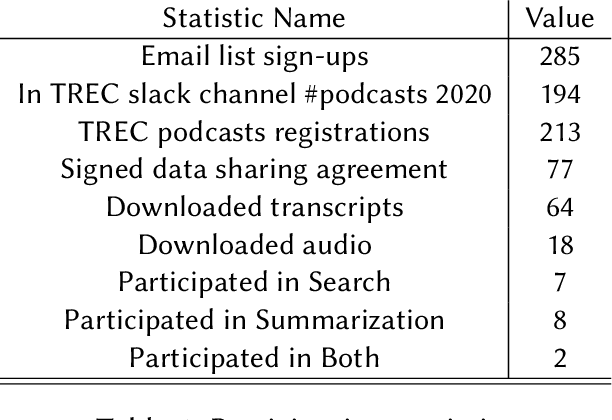
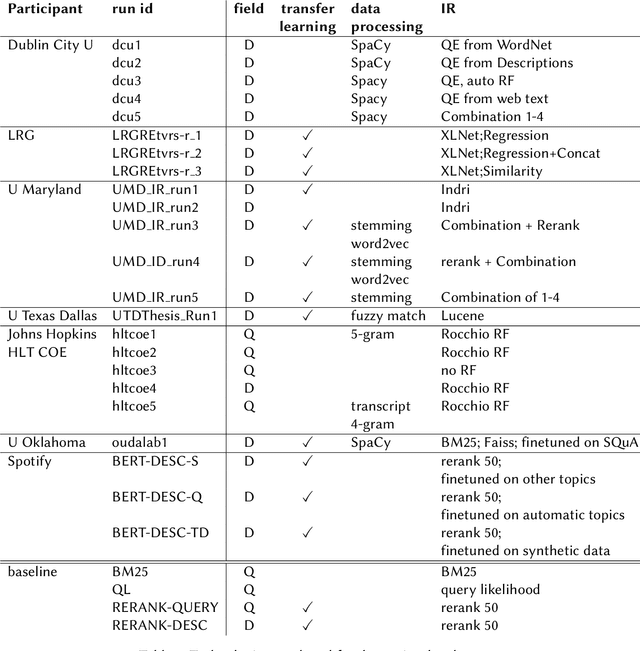
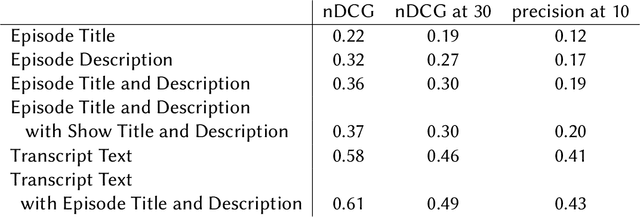
The Podcast Track is new at the Text Retrieval Conference (TREC) in 2020. The podcast track was designed to encourage research into podcasts in the information retrieval and NLP research communities. The track consisted of two shared tasks: segment retrieval and summarization, both based on a dataset of over 100,000 podcast episodes (metadata, audio, and automatic transcripts) which was released concurrently with the track. The track generated considerable interest, attracted hundreds of new registrations to TREC and fifteen teams, mostly disjoint between search and summarization, made final submissions for assessment. Deep learning was the dominant experimental approach for both search experiments and summarization. This paper gives an overview of the tasks and the results of the participants' experiments. The track will return to TREC 2021 with the same two tasks, incorporating slight modifications in response to participant feedback.
Trajectory Based Podcast Recommendation
Sep 08, 2020
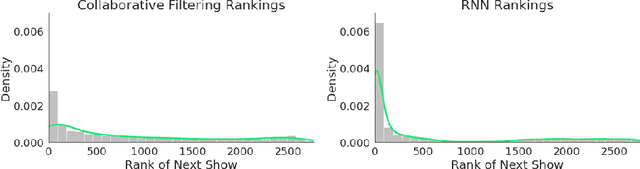

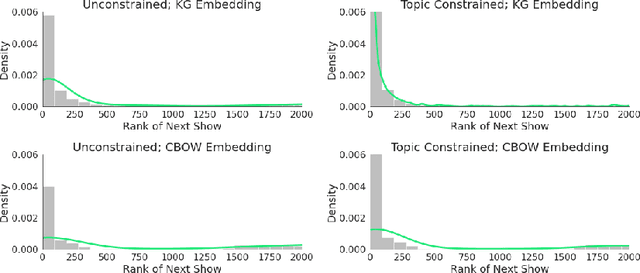
Podcast recommendation is a growing area of research that presents new challenges and opportunities. Individuals interact with podcasts in a way that is distinct from most other media; and primary to our concerns is distinct from music consumption. We show that successful and consistent recommendations can be made by viewing users as moving through the podcast library sequentially. Recommendations for future podcasts are then made using the trajectory taken from their sequential behavior. Our experiments provide evidence that user behavior is confined to local trends, and that listening patterns tend to be found over short sequences of similar types of shows. Ultimately, our approach gives a450%increase in effectiveness over a collaborative filtering baseline.