 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-term Off-Policy Evaluation and Learning
Apr 24, 2024



Short- and long-term outcomes of an algorithm often differ, with damaging downstream effects. A known example is a click-bait algorithm, which may increase short-term clicks but damage long-term user engagement. A possible solution to estimate the long-term outcome is to run an online experiment or A/B test for the potential algorithms, but it takes months or even longer to observe the long-term outcomes of interest, making the algorithm selection process unacceptably slow. This work thus studies the problem of feasibly yet accurately estimating the long-term outcome of an algorithm using only historical and short-term experiment data. Existing approaches to this problem either need a restrictive assumption about the short-term outcomes called surrogacy or cannot effectively use short-term outcomes, which is inefficient. Therefore, we propose a new framework called Long-term Off-Policy Evaluation (LOPE), which is based on reward function decomposition. LOPE works under a more relaxed assumption than surrogacy and effectively leverages short-term rewards to substantially reduce the variance. Synthetic experiments show that LOPE outperforms existing approaches particularly when surrogacy is severely violated and the long-term reward is noisy. In addition, real-world experiments on large-scale A/B test data collected on a music streaming platform show that LOPE can estimate the long-term outcome of actual algorithms more accurately than existing feasible methods.
Methods for Individual Treatment Assignment: An Application and Comparison for Playlist Generation
May 09, 2020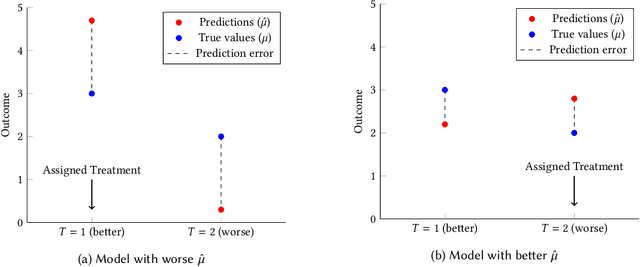

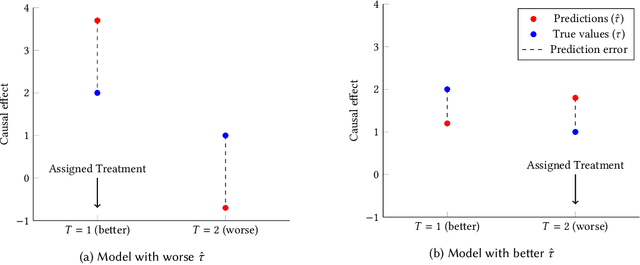

We present a systematic analysis of causal treatment assignment decision making, a general problem that arises in many applications and has received significant attention from economists, computer scientists, and social scientists. We focus on choosing, for each user, the best algorithm for playlist generation in order to optimize engagement. We characterize the various methods proposed in the literature into three general approaches: learning models to predict outcomes, learning models to predict causal effects, and learning models to predict optimal treatment assignments. We show analytically that optimizing for outcome or causal-effect prediction is not the same as optimizing for treatment assignments, and thus we should prefer learning models that optimize for treatment assignments. For our playlist generation application, we compare and contrast the three approaches empirically. This is the first comparison of the different treatment assignment approaches on a real-world application at scale (based on more than half a billion individual treatment assignments). Our results show (i) that applying different algorithms to different users can improve streams substantially compared to deploying the same algorithm for everyone, (ii) that personalized assignments improve substantially with larger data sets, and (iii) that learning models by optimizing treatment assignments rather than outcome or causal-effect predictions can improve treatment assignment performance by more than 28%.
Adaptively Pruning Features for Boosted Decision Trees
May 19, 2018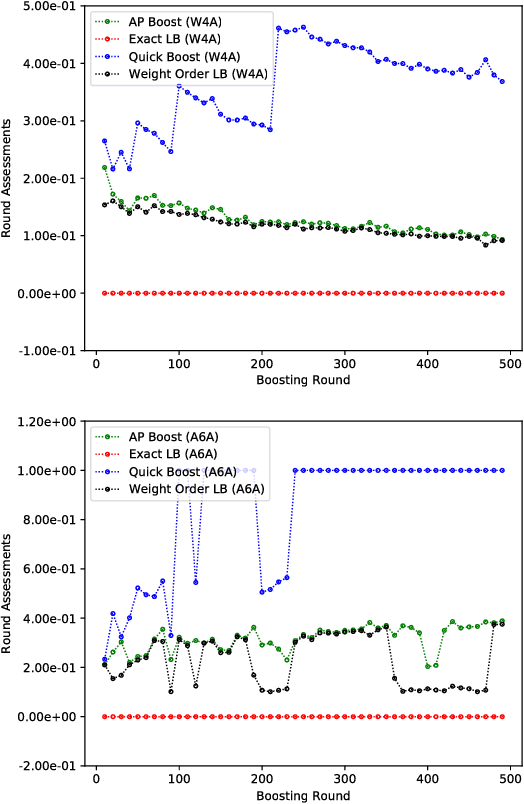

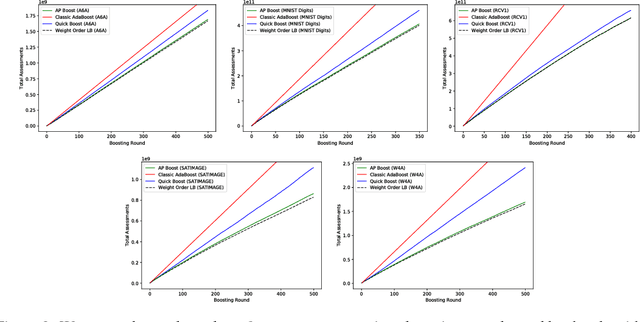

Boosted decision trees enjoy popularity in a variety of applications; however, for large-scale datasets, the cost of training a decision tree in each round can be prohibitively expensive. Inspired by ideas from the multi-arm bandit literature, we develop a highly efficient algorithm for computing exact greedy-optimal decision trees, outperforming the state-of-the-art Quick Boost method. We further develop a framework for deriving lower bounds on the problem that applies to a wide family of conceivable algorithms for the task (including our algorithm and Quick Boost), and we demonstrate empirically on a wide variety of data sets that our algorithm is near-optimal within this family of algorithms. We also derive a lower bound applicable to any algorithm solving the task, and we demonstrate that our algorithm empirically achieves performance close to this best-achievable lower bound.
Pure Exploration in Infinitely-Armed Bandit Models with Fixed-Confidence
Mar 13, 2018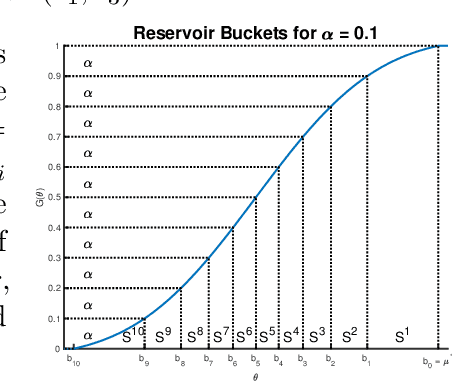
We consider the problem of near-optimal arm identification in the fixed confidence setting of the infinitely armed bandit problem when nothing is known about the arm reservoir distribution. We (1) introduce a PAC-like framework within which to derive and cast results; (2) derive a sample complexity lower bound for near-optimal arm identification; (3) propose an algorithm that identifies a nearly-optimal arm with high probability and derive an upper bound on its sample complexity which is within a log factor of our lower bound; and (4) discuss whether our log^2(1/delta) dependence is inescapable for "two-phase" (select arms first, identify the best later) algorithms in the infinite setting. This work permits the application of bandit models to a broader class of problems where fewer assumptions hold.
Measuring Human-perceived Similarity in Heterogeneous Collections
Feb 16, 2018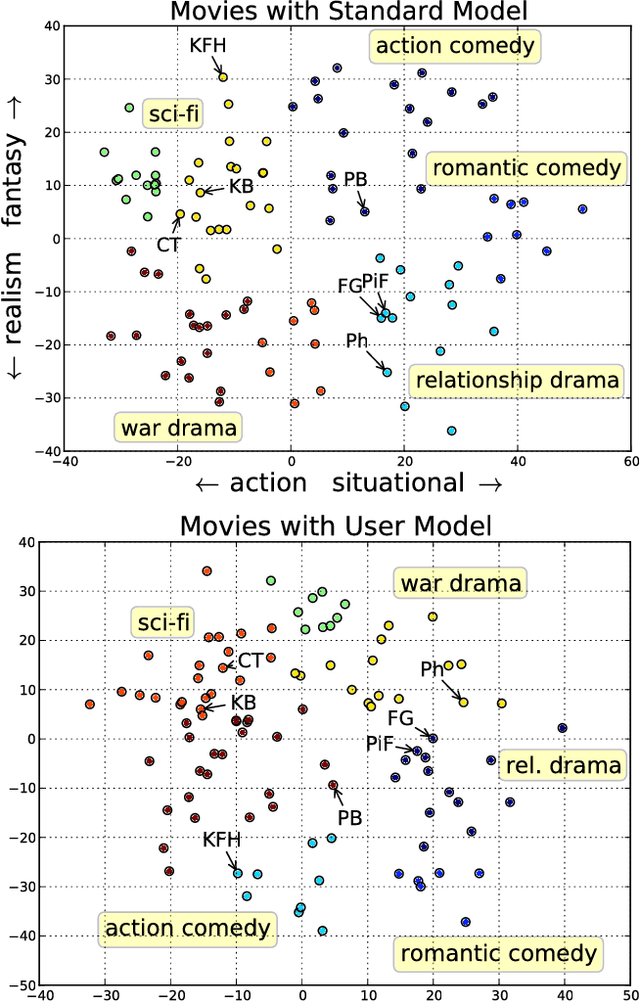


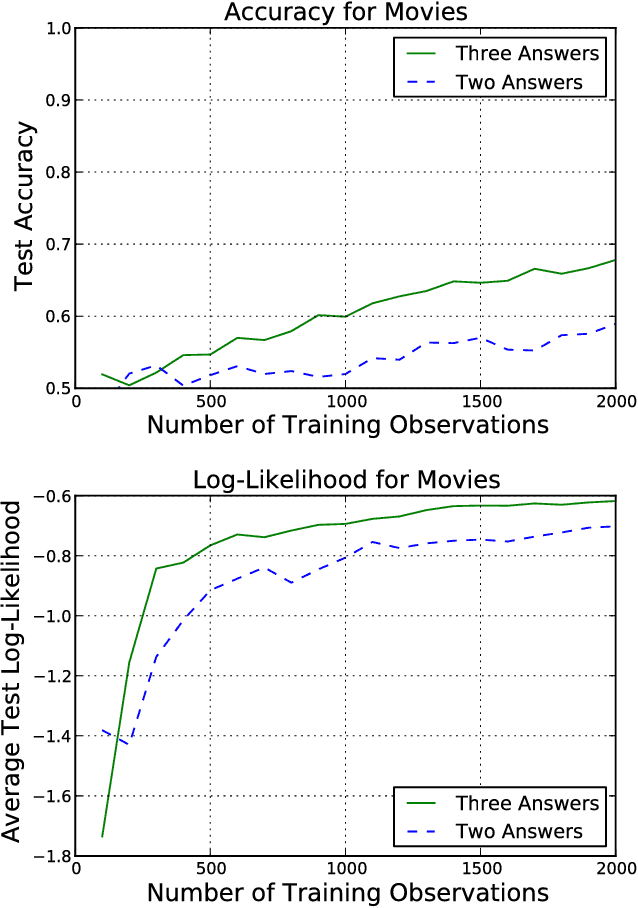
We present a technique for estimating the similarity between objects such as movies or foods whose proper representation depends on human perception. Our technique combines a modest number of human similarity assessments to infer a pairwise similarity function between the objects. This similarity function captures some human notion of similarity which may be difficult or impossible to automatically extract, such as which movie from a collection would be a better substitute when the desired one is unavailable. In contrast to prior techniques, our method does not assume that all similarity questions on the collection can be answered or that all users perceive similarity in the same way. When combined with a user model, we find how each assessor's tastes vary, affecting their perception of similarity.