 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHonesty in Causal Forests: When It Helps and When It Hurts
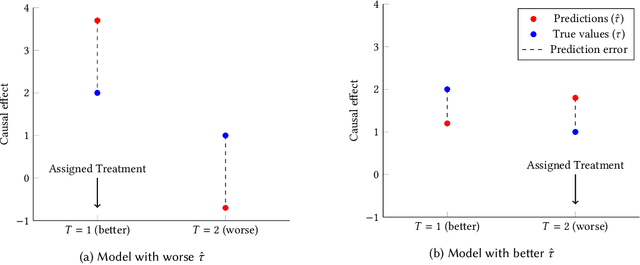
Jun 16, 2025Causal forests are increasingly used to personalize decisions based on estimated treatment effects. A distinctive modeling choice in this method is honest estimation: using separate data for splitting and for estimating effects within leaves. This practice is the default in most implementations and is widely seen as desirable for causal inference. But we show that honesty can hurt the accuracy of individual-level effect estimates. The reason is a classic bias-variance trade-off: honesty reduces variance by preventing overfitting, but increases bias by limiting the model's ability to discover and exploit meaningful heterogeneity in treatment effects. This trade-off depends on the signal-to-noise ratio (SNR): honesty helps when effect heterogeneity is hard to detect (low SNR), but hurts when the signal is strong (high SNR). In essence, honesty acts as a form of regularization, and like any regularization choice, it should be guided by out-of-sample performance, not adopted by default.
Causal Inference Isn't Special: Why It's Just Another Prediction Problem
Apr 06, 2025Causal inference is often portrayed as fundamentally distinct from predictive modeling, with its own terminology, goals, and intellectual challenges. But at its core, causal inference is simply a structured instance of prediction under distribution shift. In both cases, we begin with labeled data from a source domain and seek to generalize to a target domain where outcomes are not observed. The key difference is that in causal inference, the labels -- potential outcomes -- are selectively observed based on treatment assignment, introducing bias that must be addressed through assumptions. This perspective reframes causal estimation as a familiar generalization problem and highlights how techniques from predictive modeling, such as reweighting and domain adaptation, apply directly to causal tasks. It also clarifies that causal assumptions are not uniquely strong -- they are simply more explicit. By viewing causal inference through the lens of prediction, we demystify its logic, connect it to familiar tools, and make it more accessible to practitioners and educators alike.
The Amenability Framework: Rethinking Causal Ordering Without Estimating Causal Effects
Apr 03, 2025Who should we prioritize for intervention when we cannot estimate intervention effects? In many applied domains (e.g., advertising, customer retention, and behavioral nudging) prioritization is guided by predictive models that estimate outcome probabilities rather than causal effects. This paper investigates when these predictions (scores) can effectively rank individuals by their intervention effects, particularly when direct effect estimation is infeasible or unreliable. We propose a conceptual framework based on amenability: an individual's latent proclivity to be influenced by an intervention. We then formalize conditions under which predictive scores serve as effective proxies for amenability. These conditions justify using non-causal scores for intervention prioritization, even when the scores do not directly estimate effects. We further show that, under plausible assumptions, predictive models can outperform causal effect estimators in ranking individuals by intervention effects. Empirical evidence from an advertising context supports our theoretical findings, demonstrating that predictive modeling can offer a more robust approach to targeting than effect estimation. Our framework suggests a shift in focus, from estimating effects to inferring who is amenable, as a practical and theoretically grounded strategy for prioritizing interventions in resource-constrained environments.
Causal Fine-Tuning and Effect Calibration of Non-Causal Predictive Models
Jun 13, 2024


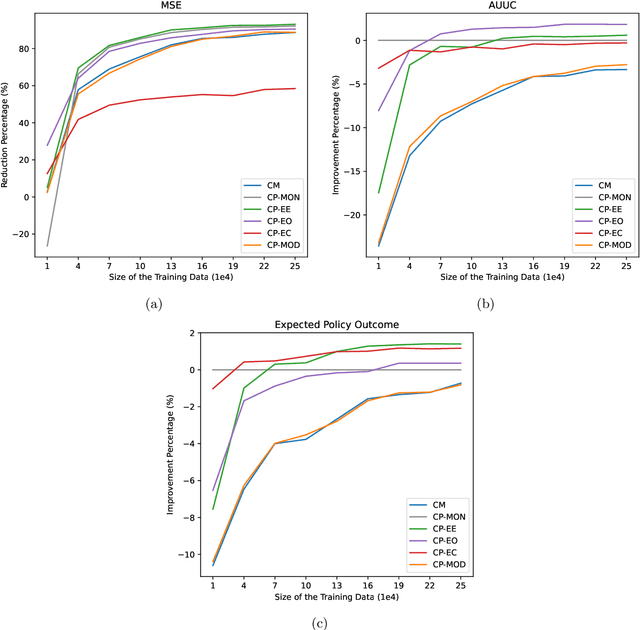
This paper proposes techniques to enhance the performance of non-causal models for causal inference using data from randomized experiments. In domains like advertising, customer retention, and precision medicine, non-causal models that predict outcomes under no intervention are often used to score individuals and rank them according to the expected effectiveness of an intervention (e.g, an ad, a retention incentive, a nudge). However, these scores may not perfectly correspond to intervention effects due to the inherent non-causal nature of the models. To address this limitation, we propose causal fine-tuning and effect calibration, two techniques that leverage experimental data to refine the output of non-causal models for different causal tasks, including effect estimation, effect ordering, and effect classification. They are underpinned by two key advantages. First, they can effectively integrate the predictive capabilities of general non-causal models with the requirements of a causal task in a specific context, allowing decision makers to support diverse causal applications with a "foundational" scoring model. Second, through simulations and an empirical example, we demonstrate that they can outperform the alternative of building a causal-effect model from scratch, particularly when the available experimental data is limited and the non-causal scores already capture substantial information about the relative sizes of causal effects. Overall, this research underscores the practical advantages of combining experimental data with non-causal models to support causal applications.
Learning the Ranking of Causal Effects with Confounded Data
Jun 25, 2022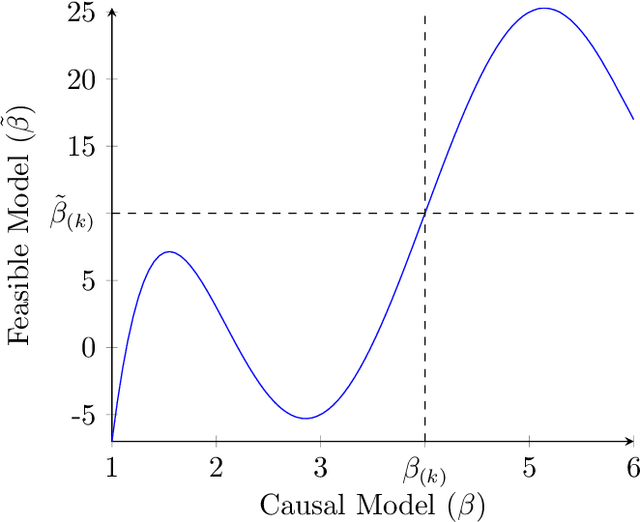

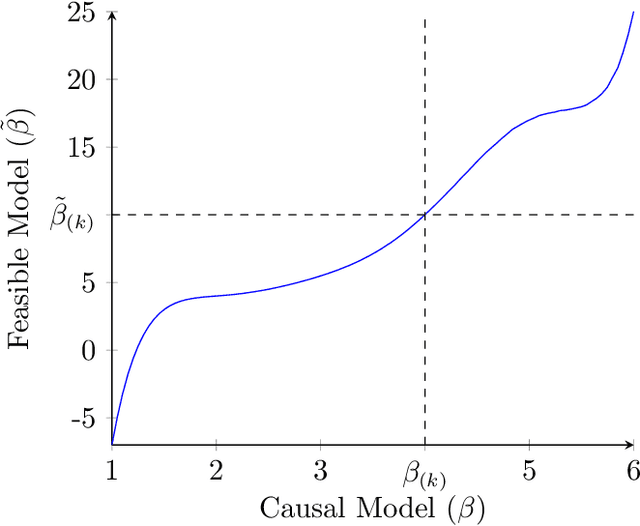
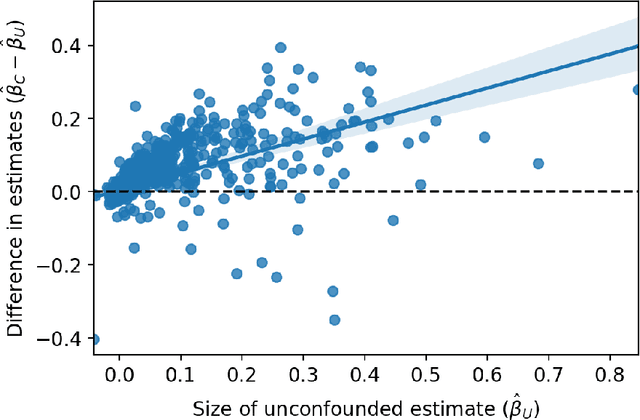
Decision makers often want to identify the individuals for whom some intervention or treatment will be most effective in order to decide who to treat. In such cases, decision makers would ideally like to rank potential recipients of the treatment according to their individual causal effects. However, the historical data available to estimate the causal effects could be confounded, and as a result, accurately estimating the effects could be impossible. We propose a new and less restrictive assumption about historical data, called the ranking preservation assumption (RPA), under which the ranking of the individual effects can be consistently estimated even if the effects themselves cannot be accurately estimated. Importantly, we find that confounding can be helpful for the estimation of the causal-effect ranking when the confounding bias is larger for individuals with larger causal effects, and that even when this is not the case, any detrimental impact of confounding can be corrected with larger training data when the RPA is met. We then analytically show that the RPA can be met in a variety of scenarios, including common business applications such as online advertising and customer retention. We support this finding with an empirical example in the context of online advertising. The example also shows how to evaluate the decision making of a confounded model in practice. The main takeaway is that what might traditionally be considered "good" data for causal estimation (i.e., unconfounded data) may not be necessary to make good causal decisions, so treatment assignment methods may work better than we give them credit for in the presence of confounding.
Causal Decision Making and Causal Effect Estimation Are Not the Same... and Why It Matters
Apr 08, 2021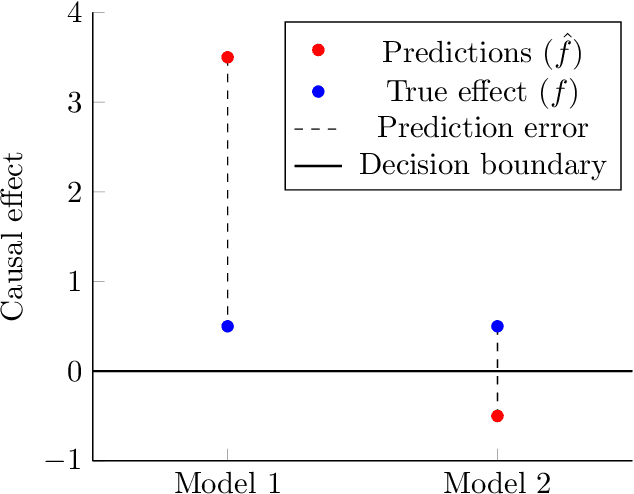
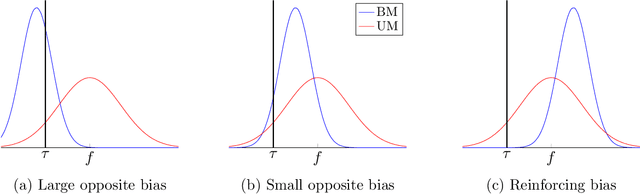
Causal decision making (CDM) at scale has become a routine part of business, and increasingly CDM is based on machine learning algorithms. For example, businesses often target offers, incentives, and recommendations with the goal of affecting consumer behavior. Recently, we have seen an acceleration of research related to CDM and to causal effect estimation (CEE) using machine learned models. This article highlights an important perspective: CDM is not the same as CEE, and counterintuitively, accurate CEE is not necessary for accurate CDM. Our experience is that this is not well understood by practitioners nor by most researchers. Technically, the estimand of interest is different, and this has important implications both for modeling and for the use of statistical models for CDM. We draw on recent research to highlight three of these implications. (1) We should carefully consider the objective function of the causal machine learning, and if possible, we should optimize for accurate "treatment assignment" rather than for accurate effect-size estimation. (2) Confounding does not have the same effect on CDM as it does on CEE. The upshot here is that for supporting CDM it may be just as good to learn with confounded data as with unconfounded data. Finally, (3) causal statistical modeling may not be necessary at all to support CDM, because there may be (and perhaps often is) a proxy target for statistical modeling that can do as well or better. This observation helps to explain at least one broad common CDM practice that seems "wrong" at first blush: the widespread use of non-causal models for targeting interventions. Our perspective is that these observations open up substantial fertile ground for future research. Whether or not you share our perspective completely, we hope we facilitate future research in this area by pointing to related articles from multiple contributing fields.
Methods for Individual Treatment Assignment: An Application and Comparison for Playlist Generation
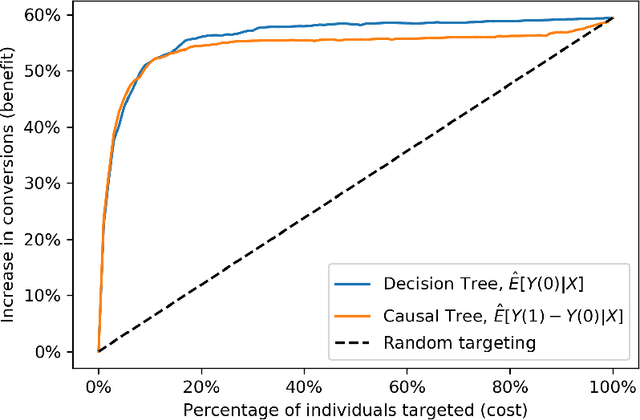
May 09, 2020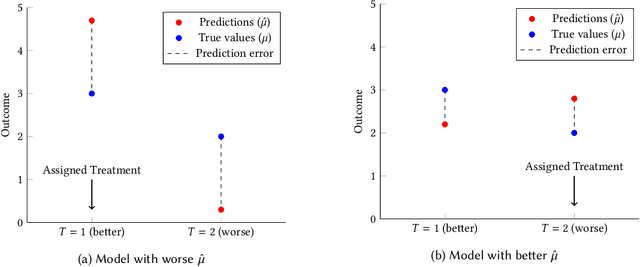


We present a systematic analysis of causal treatment assignment decision making, a general problem that arises in many applications and has received significant attention from economists, computer scientists, and social scientists. We focus on choosing, for each user, the best algorithm for playlist generation in order to optimize engagement. We characterize the various methods proposed in the literature into three general approaches: learning models to predict outcomes, learning models to predict causal effects, and learning models to predict optimal treatment assignments. We show analytically that optimizing for outcome or causal-effect prediction is not the same as optimizing for treatment assignments, and thus we should prefer learning models that optimize for treatment assignments. For our playlist generation application, we compare and contrast the three approaches empirically. This is the first comparison of the different treatment assignment approaches on a real-world application at scale (based on more than half a billion individual treatment assignments). Our results show (i) that applying different algorithms to different users can improve streams substantially compared to deploying the same algorithm for everyone, (ii) that personalized assignments improve substantially with larger data sets, and (iii) that learning models by optimizing treatment assignments rather than outcome or causal-effect predictions can improve treatment assignment performance by more than 28%.