 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlaws in the LLM Automation Narrative
Jun 09, 2026Large Language Models (LLMs) are increasingly described as performing at the level of human experts on knowledge economy tasks. These claims are primarily based on how LLMs perform on benchmarking tasks that measure average performance across standardized datasets. Primary limitations of many benchmarking tasks are that they often measure performance based on content directly included in LLM training data, and they frequently do not assess the reliability of LLM performance or the magnitude of LLM errors. However, in high stakes contexts, these qualities are critically important. Through a novel LLM benchmarking task that requires writing computer code to complete a data analysis task, we compare the performance of a frontier LLM against submissions from human experts and explicitly measure the variance of responses and the magnitude of errors. Our study reveals that the human experts perform better on average on a range of metrics and demonstrate less variability in performance. Our results provide evidence that LLMs do not consistently perform at the level of human experts and demonstrate the importance of measuring variance and assessing error magnitude in LLM benchmark evaluations.
Causal Fine-Tuning and Effect Calibration of Non-Causal Predictive Models
Jun 13, 2024


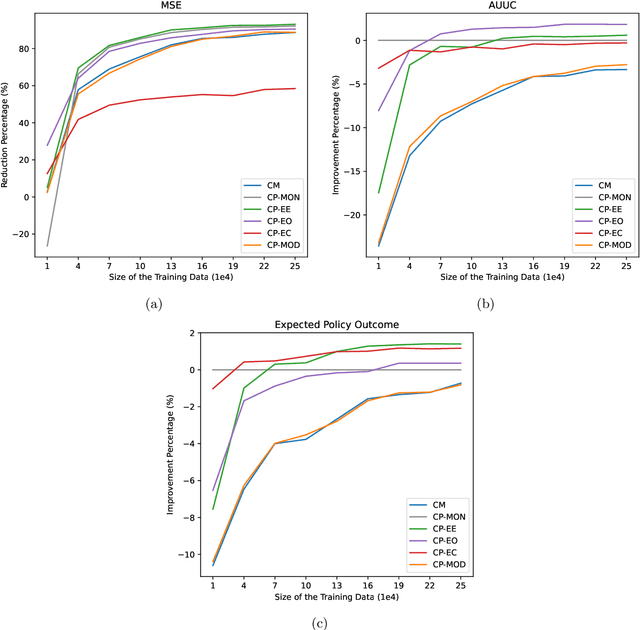
This paper proposes techniques to enhance the performance of non-causal models for causal inference using data from randomized experiments. In domains like advertising, customer retention, and precision medicine, non-causal models that predict outcomes under no intervention are often used to score individuals and rank them according to the expected effectiveness of an intervention (e.g, an ad, a retention incentive, a nudge). However, these scores may not perfectly correspond to intervention effects due to the inherent non-causal nature of the models. To address this limitation, we propose causal fine-tuning and effect calibration, two techniques that leverage experimental data to refine the output of non-causal models for different causal tasks, including effect estimation, effect ordering, and effect classification. They are underpinned by two key advantages. First, they can effectively integrate the predictive capabilities of general non-causal models with the requirements of a causal task in a specific context, allowing decision makers to support diverse causal applications with a "foundational" scoring model. Second, through simulations and an empirical example, we demonstrate that they can outperform the alternative of building a causal-effect model from scratch, particularly when the available experimental data is limited and the non-causal scores already capture substantial information about the relative sizes of causal effects. Overall, this research underscores the practical advantages of combining experimental data with non-causal models to support causal applications.
Automated versus do-it-yourself methods for causal inference: Lessons learned from a data analysis competition
Jul 20, 2018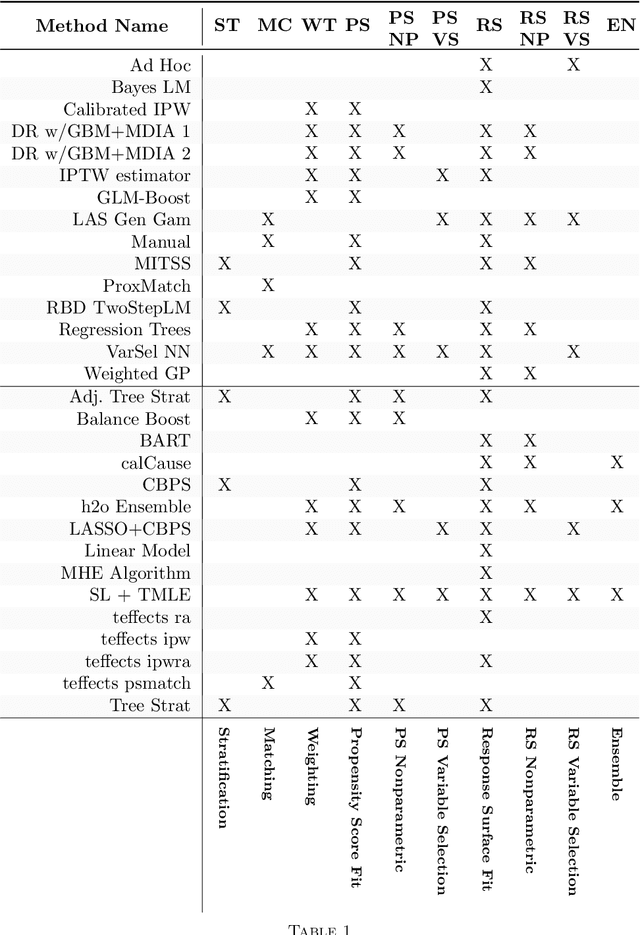
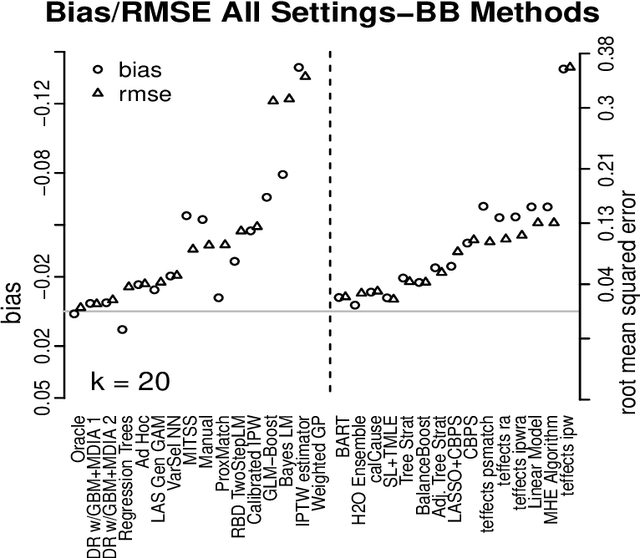
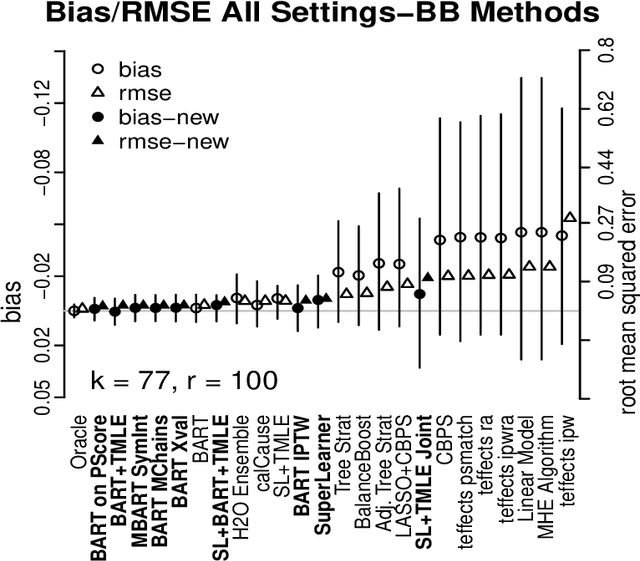
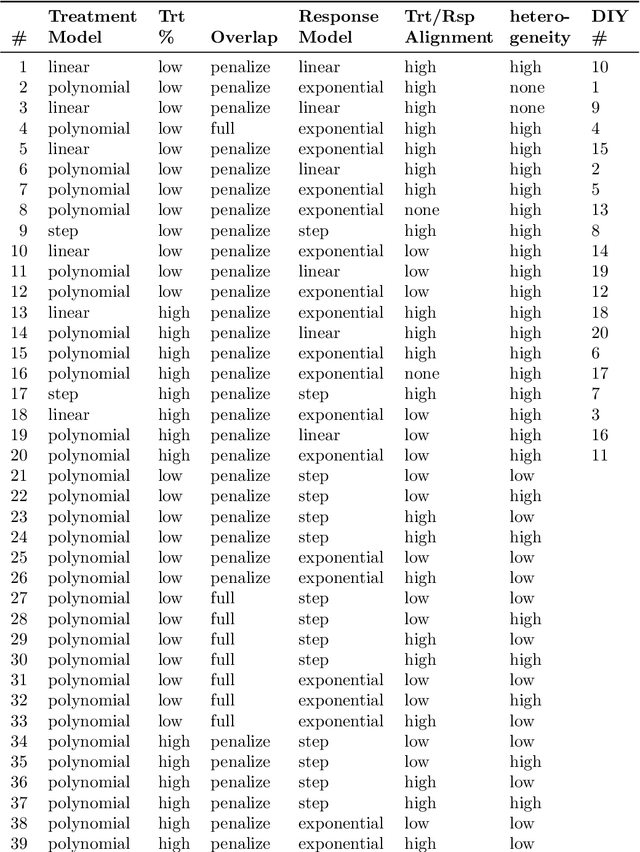
Statisticians have made great progress in creating methods that reduce our reliance on parametric assumptions. However this explosion in research has resulted in a breadth of inferential strategies that both create opportunities for more reliable inference as well as complicate the choices that an applied researcher has to make and defend. Relatedly, researchers advocating for new methods typically compare their method to at best 2 or 3 other causal inference strategies and test using simulations that may or may not be designed to equally tease out flaws in all the competing methods. The causal inference data analysis challenge, "Is Your SATT Where It's At?", launched as part of the 2016 Atlantic Causal Inference Conference, sought to make progress with respect to both of these issues. The researchers creating the data testing grounds were distinct from the researchers submitting methods whose efficacy would be evaluated. Results from 30 competitors across the two versions of the competition (black box algorithms and do-it-yourself analyses) are presented along with post-hoc analyses that reveal information about the characteristics of causal inference strategies and settings that affect performance. The most consistent conclusion was that methods that flexibly model the response surface perform better overall than methods that fail to do so. Finally new methods are proposed that combine features of several of the top-performing submitted methods.