 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHonesty in Causal Forests: When It Helps and When It Hurts
Jun 16, 2025Causal forests are increasingly used to personalize decisions based on estimated treatment effects. A distinctive modeling choice in this method is honest estimation: using separate data for splitting and for estimating effects within leaves. This practice is the default in most implementations and is widely seen as desirable for causal inference. But we show that honesty can hurt the accuracy of individual-level effect estimates. The reason is a classic bias-variance trade-off: honesty reduces variance by preventing overfitting, but increases bias by limiting the model's ability to discover and exploit meaningful heterogeneity in treatment effects. This trade-off depends on the signal-to-noise ratio (SNR): honesty helps when effect heterogeneity is hard to detect (low SNR), but hurts when the signal is strong (high SNR). In essence, honesty acts as a form of regularization, and like any regularization choice, it should be guided by out-of-sample performance, not adopted by default.
Causal Fine-Tuning and Effect Calibration of Non-Causal Predictive Models
Jun 13, 2024


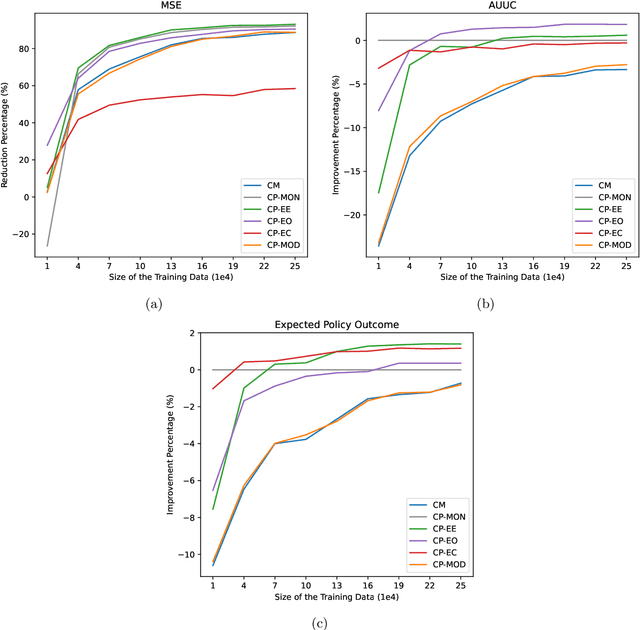
This paper proposes techniques to enhance the performance of non-causal models for causal inference using data from randomized experiments. In domains like advertising, customer retention, and precision medicine, non-causal models that predict outcomes under no intervention are often used to score individuals and rank them according to the expected effectiveness of an intervention (e.g, an ad, a retention incentive, a nudge). However, these scores may not perfectly correspond to intervention effects due to the inherent non-causal nature of the models. To address this limitation, we propose causal fine-tuning and effect calibration, two techniques that leverage experimental data to refine the output of non-causal models for different causal tasks, including effect estimation, effect ordering, and effect classification. They are underpinned by two key advantages. First, they can effectively integrate the predictive capabilities of general non-causal models with the requirements of a causal task in a specific context, allowing decision makers to support diverse causal applications with a "foundational" scoring model. Second, through simulations and an empirical example, we demonstrate that they can outperform the alternative of building a causal-effect model from scratch, particularly when the available experimental data is limited and the non-causal scores already capture substantial information about the relative sizes of causal effects. Overall, this research underscores the practical advantages of combining experimental data with non-causal models to support causal applications.
The COVMis-Stance dataset: Stance Detection on Twitter for COVID-19 Misinformation
Apr 05, 2022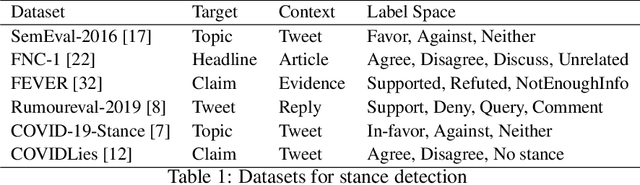
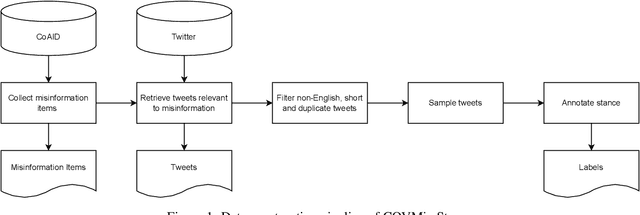

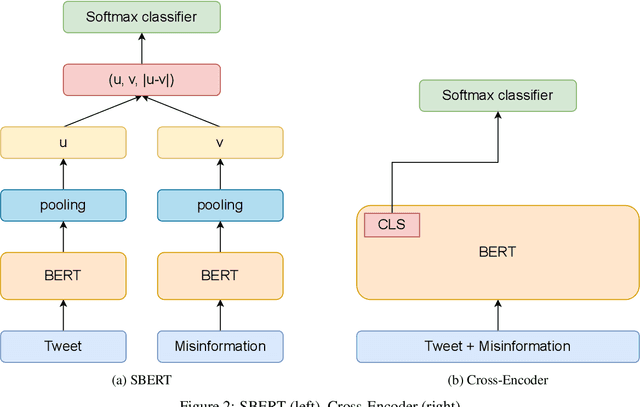
During the COVID-19 pandemic, large amounts of COVID-19 misinformation are spreading on social media. We are interested in the stance of Twitter users towards COVID-19 misinformation. However, due to the relative recent nature of the pandemic, only a few stance detection datasets fit our task. We have constructed a new stance dataset consisting of 2631 tweets annotated with the stance towards COVID-19 misinformation. In contexts with limited labeled data, we fine-tune our models by leveraging the MNLI dataset and two existing stance detection datasets (RumourEval and COVIDLies), and evaluate the model performance on our dataset. Our experimental results show that the model performs the best when fine-tuned sequentially on the MNLI dataset and the combination of the undersampled RumourEval and COVIDLies datasets. Our code and dataset are publicly available at https://github.com/yanfangh/covid-rumor-stance