 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Promotes Robustness in Theory of Mind Tasks
Jan 23, 2026Large language models (LLMs) have recently shown strong performance on Theory of Mind (ToM) tests, prompting debate about the nature and true performance of the underlying capabilities. At the same time, reasoning-oriented LLMs trained via reinforcement learning with verifiable rewards (RLVR) have achieved notable improvements across a range of benchmarks. This paper examines the behavior of such reasoning models in ToM tasks, using novel adaptations of machine psychological experiments and results from established benchmarks. We observe that reasoning models consistently exhibit increased robustness to prompt variations and task perturbations. Our analysis indicates that the observed gains are more plausibly attributed to increased robustness in finding the correct solution, rather than to fundamentally new forms of ToM reasoning. We discuss the implications of this interpretation for evaluating social-cognitive behavior in LLMs.
Mirror Mode in Fire Emblem: Beating Players at their own Game with Imitation and Reinforcement Learning
Dec 10, 2025Enemy strategies in turn-based games should be surprising and unpredictable. This study introduces Mirror Mode, a new game mode where the enemy AI mimics the personal strategy of a player to challenge them to keep changing their gameplay. A simplified version of the Nintendo strategy video game Fire Emblem Heroes has been built in Unity, with a Standard Mode and a Mirror Mode. Our first set of experiments find a suitable model for the task to imitate player demonstrations, using Reinforcement Learning and Imitation Learning: combining Generative Adversarial Imitation Learning, Behavioral Cloning, and Proximal Policy Optimization. The second set of experiments evaluates the constructed model with player tests, where models are trained on demonstrations provided by participants. The gameplay of the participants indicates good imitation in defensive behavior, but not in offensive strategies. Participant's surveys indicated that they recognized their own retreating tactics, and resulted in an overall higher player-satisfaction for Mirror Mode. Refining the model further may improve imitation quality and increase player's satisfaction, especially when players face their own strategies. The full code and survey results are stored at: https://github.com/YannaSmid/MirrorMode
Agentic Large Language Models, a survey
Mar 29, 2025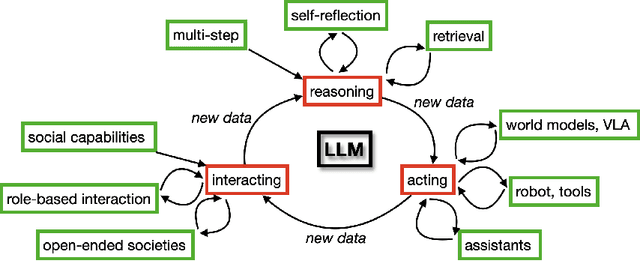

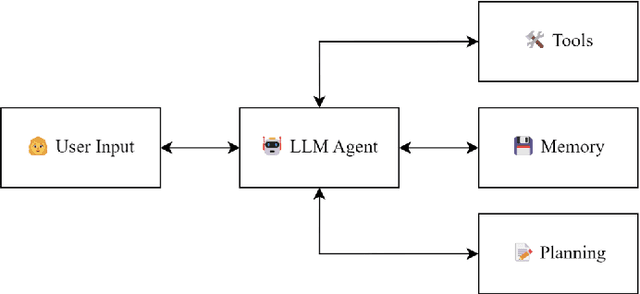
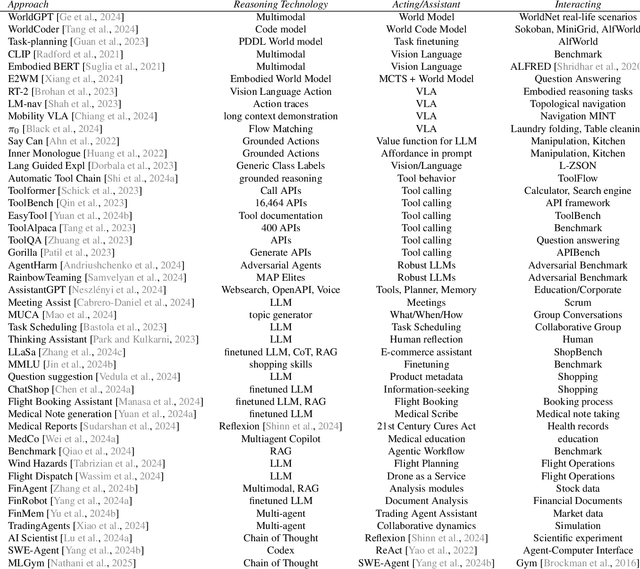
There is great interest in agentic LLMs, large language models that act as agents. We review the growing body of work in this area and provide a research agenda. Agentic LLMs are LLMs that (1) reason, (2) act, and (3) interact. We organize the literature according to these three categories. The research in the first category focuses on reasoning, reflection, and retrieval, aiming to improve decision making; the second category focuses on action models, robots, and tools, aiming for agents that act as useful assistants; the third category focuses on multi-agent systems, aiming for collaborative task solving and simulating interaction to study emergent social behavior. We find that works mutually benefit from results in other categories: retrieval enables tool use, reflection improves multi-agent collaboration, and reasoning benefits all categories. We discuss applications of agentic LLMs and provide an agenda for further research. Important applications are in medical diagnosis, logistics and financial market analysis. Meanwhile, self-reflective agents playing roles and interacting with one another augment the process of scientific research itself. Further, agentic LLMs may provide a solution for the problem of LLMs running out of training data: inference-time behavior generates new training states, such that LLMs can keep learning without needing ever larger datasets. We note that there is risk associated with LLM assistants taking action in the real world, while agentic LLMs are also likely to benefit society.
The Impacts of AI Avatar Appearance and Disclosure on User Motivation
Jul 31, 2024


This study examines the influence of perceived AI features on user motivation in virtual interactions. AI avatars, being disclosed as being an AI, or embodying specific genders, could be used in user-AI interactions. Leveraging insights from AI and avatar research, we explore how AI disclosure and gender affect user motivation. We conducted a game-based experiment involving over 72,500 participants who solved search problems alone or with an AI companion. Different groups experienced varying AI appearances and disclosures. We measured play intensity. Results revealed that the presence of another avatar led to less intense play compared to solo play. Disclosure of the avatar as AI heightened effort intensity compared to non-disclosed AI companions. Additionally, a masculine AI appearance reduced effort intensity.
ChatGPT as a commenter to the news: can LLMs generate human-like opinions?
Dec 21, 2023ChatGPT, GPT-3.5, and other large language models (LLMs) have drawn significant attention since their release, and the abilities of these models have been investigated for a wide variety of tasks. In this research we investigate to what extent GPT-3.5 can generate human-like comments on Dutch news articles. We define human likeness as `not distinguishable from human comments', approximated by the difficulty of automatic classification between human and GPT comments. We analyze human likeness across multiple prompting techniques. In particular, we utilize zero-shot, few-shot and context prompts, for two generated personas. We found that our fine-tuned BERT models can easily distinguish human-written comments from GPT-3.5 generated comments, with none of the used prompting methods performing noticeably better. We further analyzed that human comments consistently showed higher lexical diversity than GPT-generated comments. This indicates that although generative LLMs can generate fluent text, their capability to create human-like opinionated comments is still limited.
Relevance feedback strategies for recall-oriented neural information retrieval
Nov 25, 2023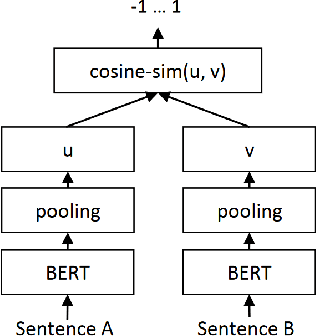
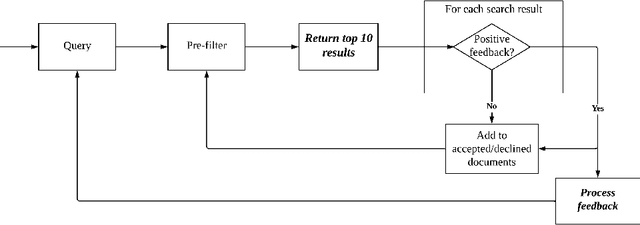
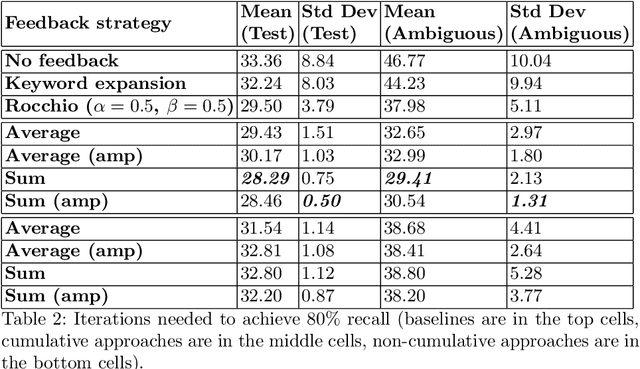
In a number of information retrieval applications (e.g., patent search, literature review, due diligence, etc.), preventing false negatives is more important than preventing false positives. However, approaches designed to reduce review effort (like "technology assisted review") can create false negatives, since they are often based on active learning systems that exclude documents automatically based on user feedback. Therefore, this research proposes a more recall-oriented approach to reducing review effort. More specifically, through iteratively re-ranking the relevance rankings based on user feedback, which is also referred to as relevance feedback. In our proposed method, the relevance rankings are produced by a BERT-based dense-vector search and the relevance feedback is based on cumulatively summing the queried and selected embeddings. Our results show that this method can reduce review effort between 17.85% and 59.04%, compared to a baseline approach (of no feedback), given a fixed recall target
Theory of Mind in Large Language Models: Examining Performance of 11 State-of-the-Art models vs. Children Aged 7-10 on Advanced Tests
Oct 31, 2023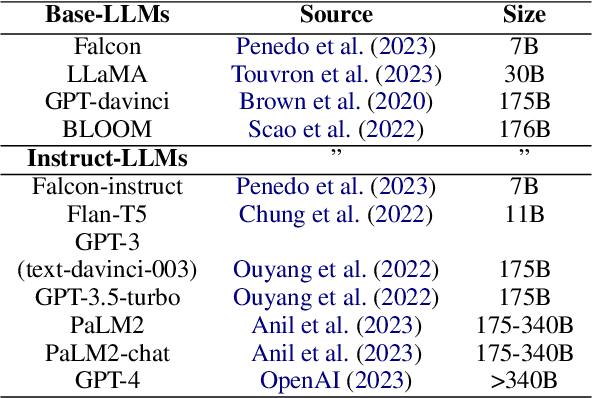

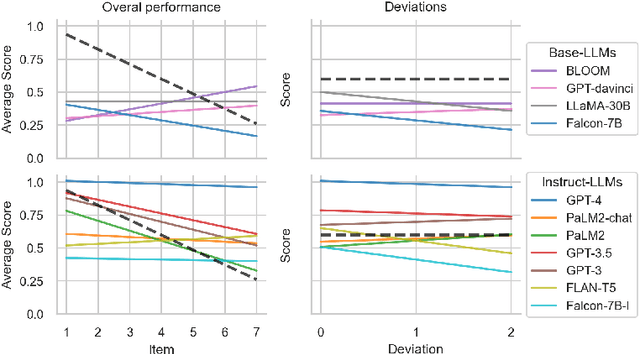

To what degree should we ascribe cognitive capacities to Large Language Models (LLMs), such as the ability to reason about intentions and beliefs known as Theory of Mind (ToM)? Here we add to this emerging debate by (i) testing 11 base- and instruction-tuned LLMs on capabilities relevant to ToM beyond the dominant false-belief paradigm, including non-literal language usage and recursive intentionality; (ii) using newly rewritten versions of standardized tests to gauge LLMs' robustness; (iii) prompting and scoring for open besides closed questions; and (iv) benchmarking LLM performance against that of children aged 7-10 on the same tasks. We find that instruction-tuned LLMs from the GPT family outperform other models, and often also children. Base-LLMs are mostly unable to solve ToM tasks, even with specialized prompting. We suggest that the interlinked evolution and development of language and ToM may help explain what instruction-tuning adds: rewarding cooperative communication that takes into account interlocutor and context. We conclude by arguing for a nuanced perspective on ToM in LLMs.
The COVMis-Stance dataset: Stance Detection on Twitter for COVID-19 Misinformation
Apr 05, 2022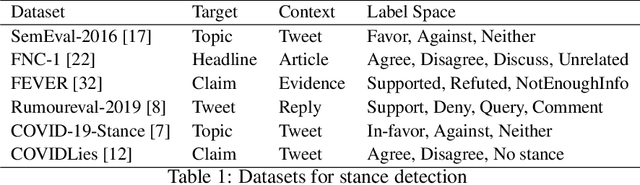
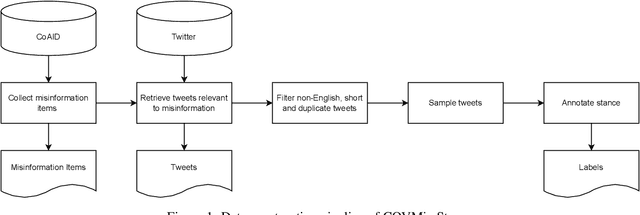

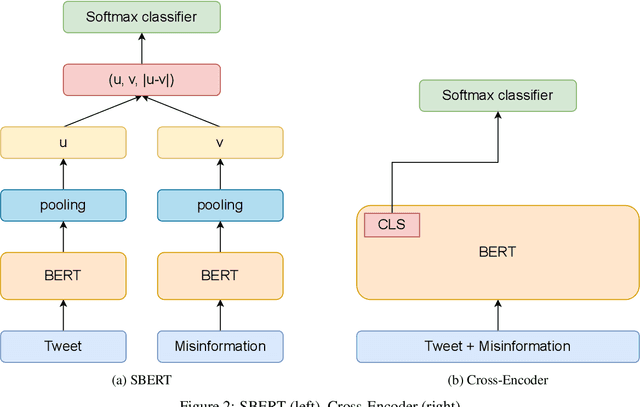
During the COVID-19 pandemic, large amounts of COVID-19 misinformation are spreading on social media. We are interested in the stance of Twitter users towards COVID-19 misinformation. However, due to the relative recent nature of the pandemic, only a few stance detection datasets fit our task. We have constructed a new stance dataset consisting of 2631 tweets annotated with the stance towards COVID-19 misinformation. In contexts with limited labeled data, we fine-tune our models by leveraging the MNLI dataset and two existing stance detection datasets (RumourEval and COVIDLies), and evaluate the model performance on our dataset. Our experimental results show that the model performs the best when fine-tuned sequentially on the MNLI dataset and the combination of the undersampled RumourEval and COVIDLies datasets. Our code and dataset are publicly available at https://github.com/yanfangh/covid-rumor-stance
Distinguishing Commercial from Editorial Content in News
Nov 06, 2021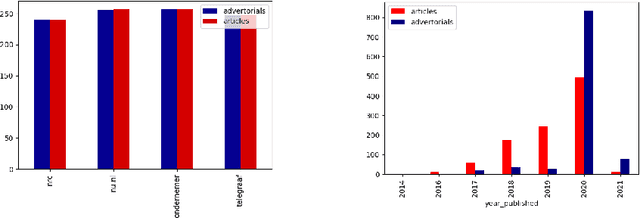
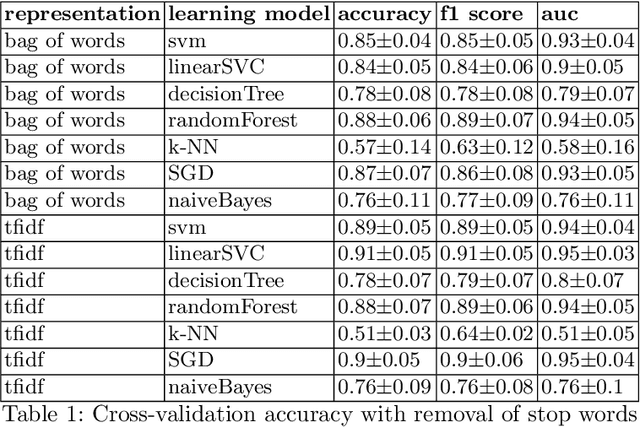
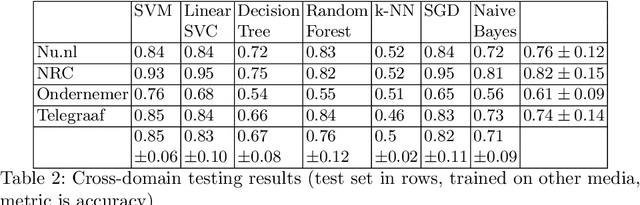
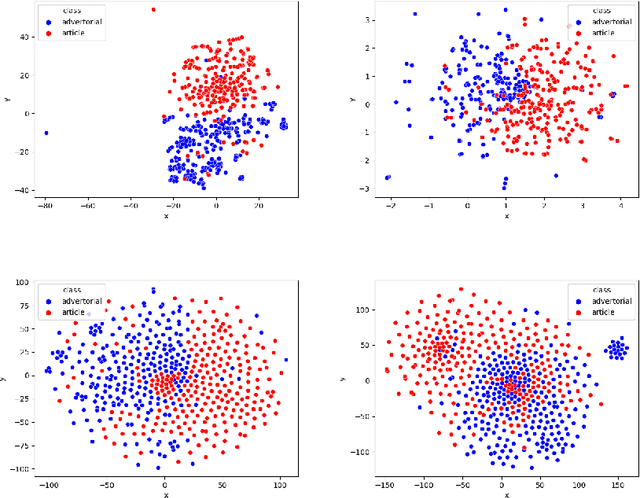
How can we distinguish commercial from editorial content in news, or more specifically, differentiate between advertorials and regular news articles? An advertorial is a commercial message written and formatted as an article, making it harder for readers to recognize these as advertising, despite the use of disclaimers. In our research we aim to differentiate the two using a machine learning model, and a lexicon derived from it. This was accomplished by scraping 1.000 articles and 1.000 advertorials from four different Dutch news sources and classifying these based on textual features. With this setup our most successful machine learning model had an accuracy of just over $90\%$. To generate additional insights into differences between news and advertorial language, we also analyzed model coefficients and explored the corpus through co-occurrence networks and t-SNE graphs.
Spot What Matters: Learning Context Using Graph Convolutional Networks for Weakly-Supervised Action Detection
Jul 28, 2021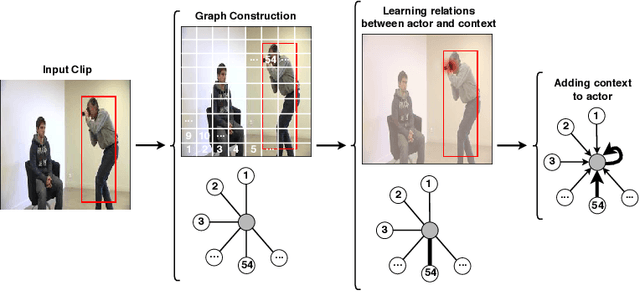
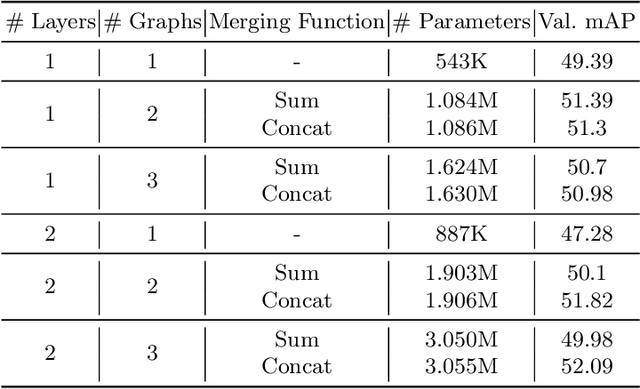
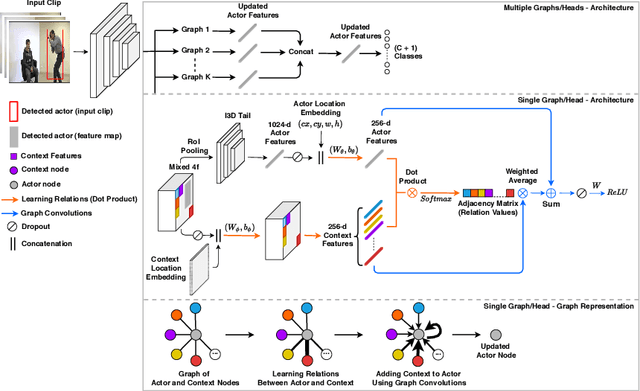
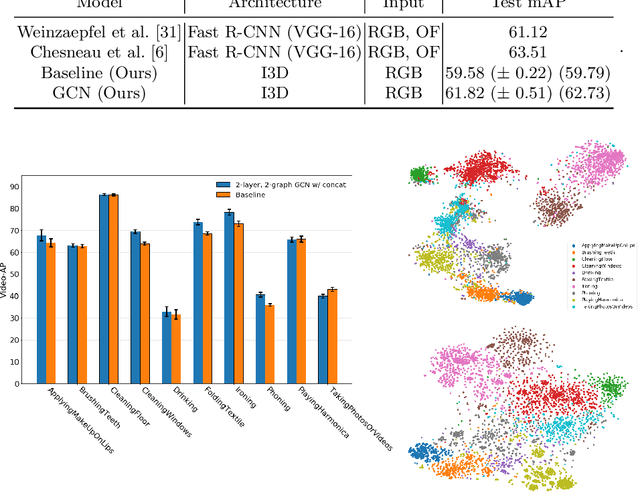
The dominant paradigm in spatiotemporal action detection is to classify actions using spatiotemporal features learned by 2D or 3D Convolutional Networks. We argue that several actions are characterized by their context, such as relevant objects and actors present in the video. To this end, we introduce an architecture based on self-attention and Graph Convolutional Networks in order to model contextual cues, such as actor-actor and actor-object interactions, to improve human action detection in video. We are interested in achieving this in a weakly-supervised setting, i.e. using as less annotations as possible in terms of action bounding boxes. Our model aids explainability by visualizing the learned context as an attention map, even for actions and objects unseen during training. We evaluate how well our model highlights the relevant context by introducing a quantitative metric based on recall of objects retrieved by attention maps. Our model relies on a 3D convolutional RGB stream, and does not require expensive optical flow computation. We evaluate our models on the DALY dataset, which consists of human-object interaction actions. Experimental results show that our contextualized approach outperforms a baseline action detection approach by more than 2 points in Video-mAP. Code is available at \url{https://github.com/micts/acgcn}
* Paper presented at the International Workshop on Deep Learning for Human-Centric Activity Understanding (DL-HAU2020), January 11, 2021