 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models as Artificial Learners: Investigating Crosslinguistic Influence
Jan 29, 2026Despite the centrality of crosslinguistic influence (CLI) to bilingualism research, human studies often yield conflicting results due to inherent experimental variance. We address these inconsistencies by using language models (LMs) as controlled statistical learners to systematically simulate CLI and isolate its underlying drivers. Specifically, we study the effect of varying the L1 language dominance and the L2 language proficiency, which we manipulate by controlling the L2 age of exposure -- defined as the training step at which the L2 is introduced. Furthermore, we investigate the impact of pretraining on L1 languages with varying syntactic distance from the L2. Using cross-linguistic priming, we analyze how activating L1 structures impacts L2 processing. Our results align with evidence from psycholinguistic studies, confirming that language dominance and proficiency are strong predictors of CLI. We further find that while priming of grammatical structures is bidirectional, the priming of ungrammatical structures is sensitive to language dominance. Finally, we provide mechanistic evidence of CLI in LMs, demonstrating that the L1 is co-activated during L2 processing and directly influences the neural circuitry recruited for the L2. More broadly, our work demonstrates that LMs can serve as a computational framework to inform theories of human CLI.
You Are What You Train: Effects of Data Composition on Training Context-aware Machine Translation Models
Sep 17, 2025Achieving human-level translations requires leveraging context to ensure coherence and handle complex phenomena like pronoun disambiguation. Sparsity of contextually rich examples in the standard training data has been hypothesized as the reason for the difficulty of context utilization. In this work, we systematically validate this claim in both single- and multilingual settings by constructing training datasets with a controlled proportions of contextually relevant examples. We demonstrate a strong association between training data sparsity and model performance confirming sparsity as a key bottleneck. Importantly, we reveal that improvements in one contextual phenomenon do no generalize to others. While we observe some cross-lingual transfer, it is not significantly higher between languages within the same sub-family. Finally, we propose and empirically evaluate two training strategies designed to leverage the available data. These strategies improve context utilization, resulting in accuracy gains of up to 6 and 8 percentage points on the ctxPro evaluation in single- and multilingual settings respectively.
A Representation Level Analysis of NMT Model Robustness to Grammatical Errors
May 27, 2025Understanding robustness is essential for building reliable NLP systems. Unfortunately, in the context of machine translation, previous work mainly focused on documenting robustness failures or improving robustness. In contrast, we study robustness from a model representation perspective by looking at internal model representations of ungrammatical inputs and how they evolve through model layers. For this purpose, we perform Grammatical Error Detection (GED) probing and representational similarity analysis. Our findings indicate that the encoder first detects the grammatical error, then corrects it by moving its representation toward the correct form. To understand what contributes to this process, we turn to the attention mechanism where we identify what we term Robustness Heads. We find that Robustness Heads attend to interpretable linguistic units when responding to grammatical errors, and that when we fine-tune models for robustness, they tend to rely more on Robustness Heads for updating the ungrammatical word representation.
Analyzing the Attention Heads for Pronoun Disambiguation in Context-aware Machine Translation Models
Dec 15, 2024In this paper, we investigate the role of attention heads in Context-aware Machine Translation models for pronoun disambiguation in the English-to-German and English-to-French language directions. We analyze their influence by both observing and modifying the attention scores corresponding to the plausible relations that could impact a pronoun prediction. Our findings reveal that while some heads do attend the relations of interest, not all of them influence the models' ability to disambiguate pronouns. We show that certain heads are underutilized by the models, suggesting that model performance could be improved if only the heads would attend one of the relations more strongly. Furthermore, we fine-tune the most promising heads and observe the increase in pronoun disambiguation accuracy of up to 5 percentage points which demonstrates that the improvements in performance can be solidified into the models' parameters.
Fixed and Adaptive Simultaneous Machine Translation Strategies Using Adapters
Jul 18, 2024



Simultaneous machine translation aims at solving the task of real-time translation by starting to translate before consuming the full input, which poses challenges in terms of balancing quality and latency of the translation. The wait-$k$ policy offers a solution by starting to translate after consuming $k$ words, where the choice of the number $k$ directly affects the latency and quality. In applications where we seek to keep the choice over latency and quality at inference, the wait-$k$ policy obliges us to train more than one model. In this paper, we address the challenge of building one model that can fulfil multiple latency levels and we achieve this by introducing lightweight adapter modules into the decoder. The adapters are trained to be specialized for different wait-$k$ values and compared to other techniques they offer more flexibility to allow for reaping the benefits of parameter sharing and minimizing interference. Additionally, we show that by combining with an adaptive strategy, we can further improve the results. Experiments on two language directions show that our method outperforms or competes with other strong baselines on most latency values.
Sequence Shortening for Context-Aware Machine Translation
Feb 02, 2024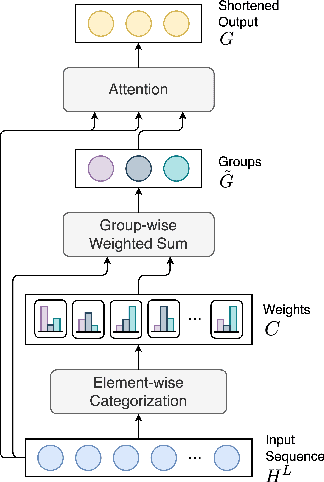



Context-aware Machine Translation aims to improve translations of sentences by incorporating surrounding sentences as context. Towards this task, two main architectures have been applied, namely single-encoder (based on concatenation) and multi-encoder models. In this study, we show that a special case of multi-encoder architecture, where the latent representation of the source sentence is cached and reused as the context in the next step, achieves higher accuracy on the contrastive datasets (where the models have to rank the correct translation among the provided sentences) and comparable BLEU and COMET scores as the single- and multi-encoder approaches. Furthermore, we investigate the application of Sequence Shortening to the cached representations. We test three pooling-based shortening techniques and introduce two novel methods - Latent Grouping and Latent Selecting, where the network learns to group tokens or selects the tokens to be cached as context. Our experiments show that the two methods achieve competitive BLEU and COMET scores and accuracies on the contrastive datasets to the other tested methods while potentially allowing for higher interpretability and reducing the growth of memory requirements with increased context size.
Relevance feedback strategies for recall-oriented neural information retrieval
Nov 25, 2023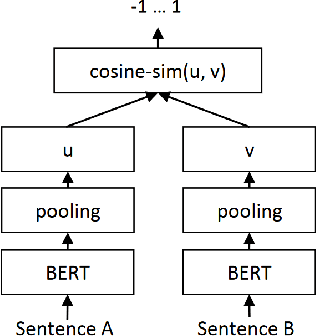
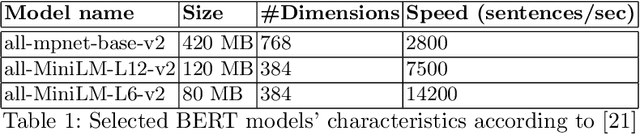
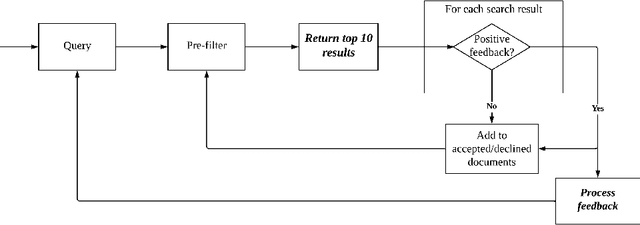
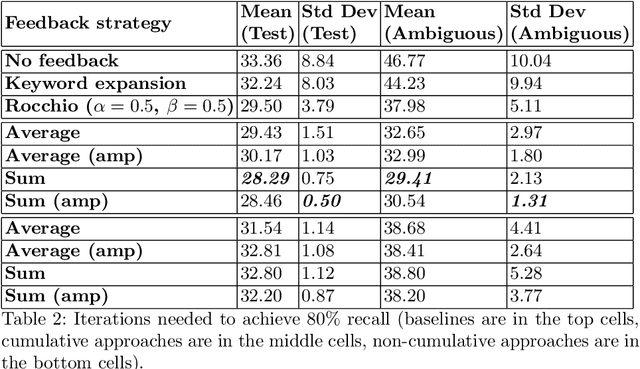
In a number of information retrieval applications (e.g., patent search, literature review, due diligence, etc.), preventing false negatives is more important than preventing false positives. However, approaches designed to reduce review effort (like "technology assisted review") can create false negatives, since they are often based on active learning systems that exclude documents automatically based on user feedback. Therefore, this research proposes a more recall-oriented approach to reducing review effort. More specifically, through iteratively re-ranking the relevance rankings based on user feedback, which is also referred to as relevance feedback. In our proposed method, the relevance rankings are produced by a BERT-based dense-vector search and the relevance feedback is based on cumulatively summing the queried and selected embeddings. Our results show that this method can reduce review effort between 17.85% and 59.04%, compared to a baseline approach (of no feedback), given a fixed recall target