 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelevance feedback strategies for recall-oriented neural information retrieval
Nov 25, 2023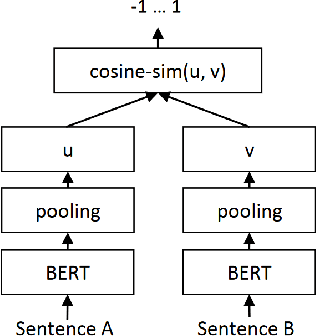
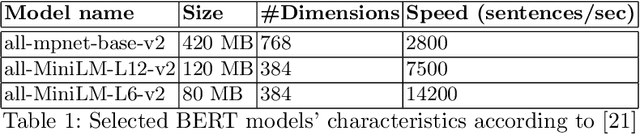
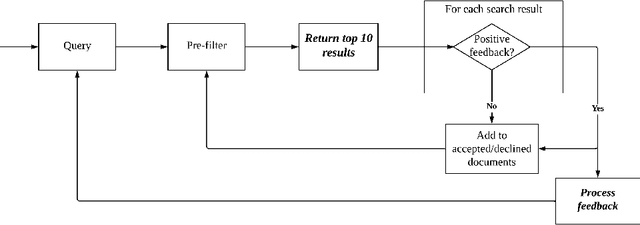
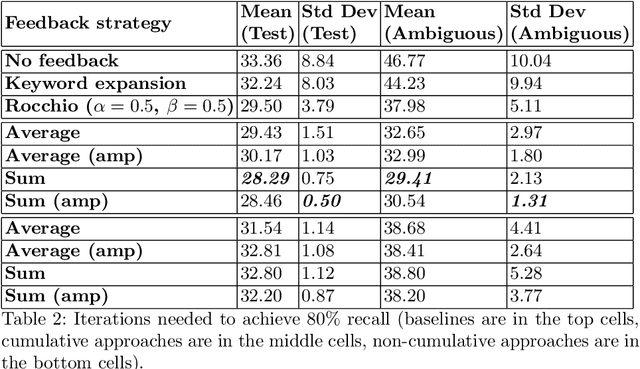
In a number of information retrieval applications (e.g., patent search, literature review, due diligence, etc.), preventing false negatives is more important than preventing false positives. However, approaches designed to reduce review effort (like "technology assisted review") can create false negatives, since they are often based on active learning systems that exclude documents automatically based on user feedback. Therefore, this research proposes a more recall-oriented approach to reducing review effort. More specifically, through iteratively re-ranking the relevance rankings based on user feedback, which is also referred to as relevance feedback. In our proposed method, the relevance rankings are produced by a BERT-based dense-vector search and the relevance feedback is based on cumulatively summing the queried and selected embeddings. Our results show that this method can reduce review effort between 17.85% and 59.04%, compared to a baseline approach (of no feedback), given a fixed recall target
Distinguishing Commercial from Editorial Content in News
Nov 06, 2021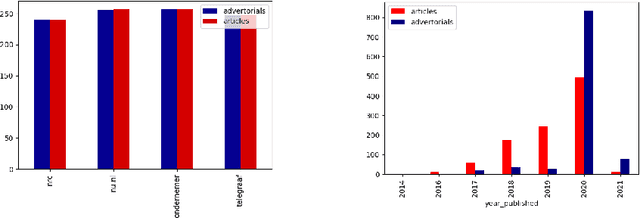
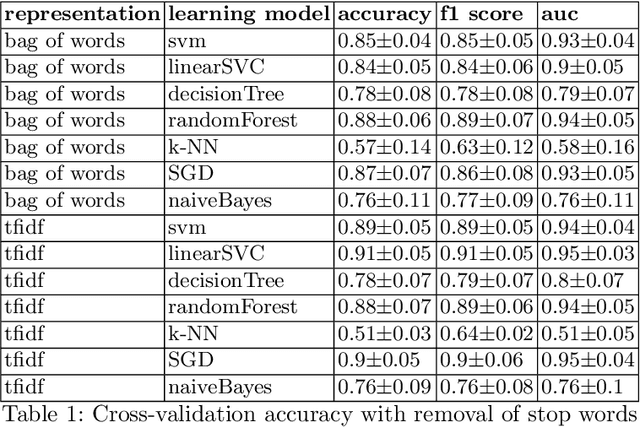
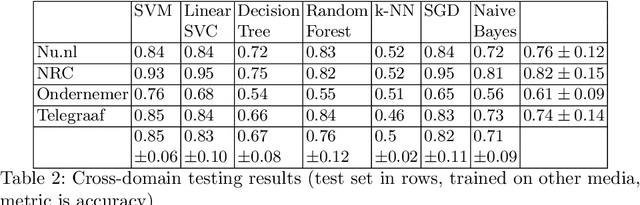
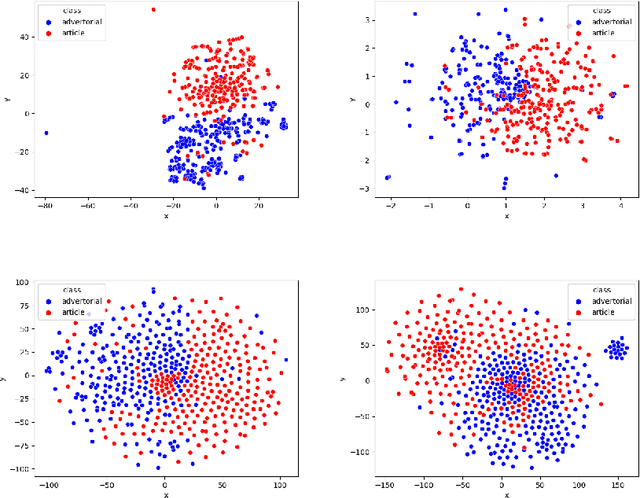
How can we distinguish commercial from editorial content in news, or more specifically, differentiate between advertorials and regular news articles? An advertorial is a commercial message written and formatted as an article, making it harder for readers to recognize these as advertising, despite the use of disclaimers. In our research we aim to differentiate the two using a machine learning model, and a lexicon derived from it. This was accomplished by scraping 1.000 articles and 1.000 advertorials from four different Dutch news sources and classifying these based on textual features. With this setup our most successful machine learning model had an accuracy of just over $90\%$. To generate additional insights into differences between news and advertorial language, we also analyzed model coefficients and explored the corpus through co-occurrence networks and t-SNE graphs.