 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Are What You Train: Effects of Data Composition on Training Context-aware Machine Translation Models
Sep 17, 2025

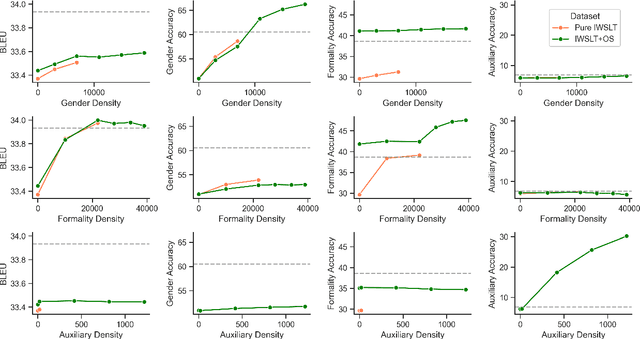

Achieving human-level translations requires leveraging context to ensure coherence and handle complex phenomena like pronoun disambiguation. Sparsity of contextually rich examples in the standard training data has been hypothesized as the reason for the difficulty of context utilization. In this work, we systematically validate this claim in both single- and multilingual settings by constructing training datasets with a controlled proportions of contextually relevant examples. We demonstrate a strong association between training data sparsity and model performance confirming sparsity as a key bottleneck. Importantly, we reveal that improvements in one contextual phenomenon do no generalize to others. While we observe some cross-lingual transfer, it is not significantly higher between languages within the same sub-family. Finally, we propose and empirically evaluate two training strategies designed to leverage the available data. These strategies improve context utilization, resulting in accuracy gains of up to 6 and 8 percentage points on the ctxPro evaluation in single- and multilingual settings respectively.
Analyzing the Attention Heads for Pronoun Disambiguation in Context-aware Machine Translation Models
Dec 15, 2024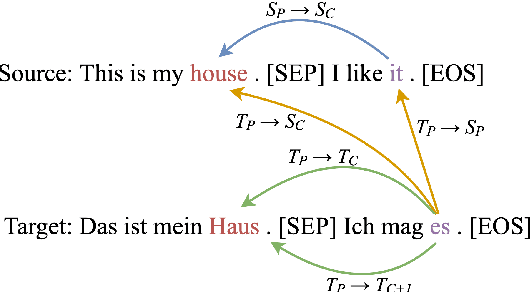



In this paper, we investigate the role of attention heads in Context-aware Machine Translation models for pronoun disambiguation in the English-to-German and English-to-French language directions. We analyze their influence by both observing and modifying the attention scores corresponding to the plausible relations that could impact a pronoun prediction. Our findings reveal that while some heads do attend the relations of interest, not all of them influence the models' ability to disambiguate pronouns. We show that certain heads are underutilized by the models, suggesting that model performance could be improved if only the heads would attend one of the relations more strongly. Furthermore, we fine-tune the most promising heads and observe the increase in pronoun disambiguation accuracy of up to 5 percentage points which demonstrates that the improvements in performance can be solidified into the models' parameters.
Sequence Shortening for Context-Aware Machine Translation
Feb 02, 2024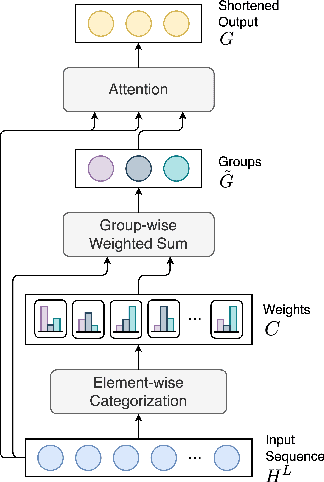



Context-aware Machine Translation aims to improve translations of sentences by incorporating surrounding sentences as context. Towards this task, two main architectures have been applied, namely single-encoder (based on concatenation) and multi-encoder models. In this study, we show that a special case of multi-encoder architecture, where the latent representation of the source sentence is cached and reused as the context in the next step, achieves higher accuracy on the contrastive datasets (where the models have to rank the correct translation among the provided sentences) and comparable BLEU and COMET scores as the single- and multi-encoder approaches. Furthermore, we investigate the application of Sequence Shortening to the cached representations. We test three pooling-based shortening techniques and introduce two novel methods - Latent Grouping and Latent Selecting, where the network learns to group tokens or selects the tokens to be cached as context. Our experiments show that the two methods achieve competitive BLEU and COMET scores and accuracies on the contrastive datasets to the other tested methods while potentially allowing for higher interpretability and reducing the growth of memory requirements with increased context size.
TENT: Tensorized Encoder Transformer for Temperature Forecasting
Jun 28, 2021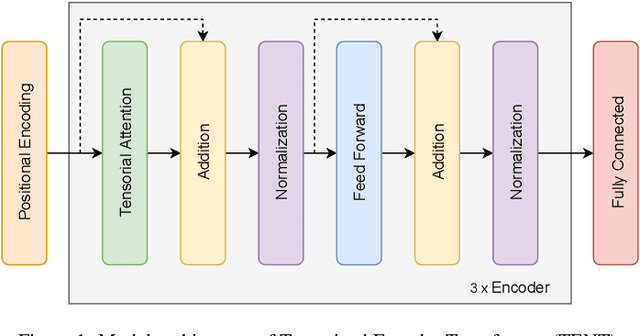
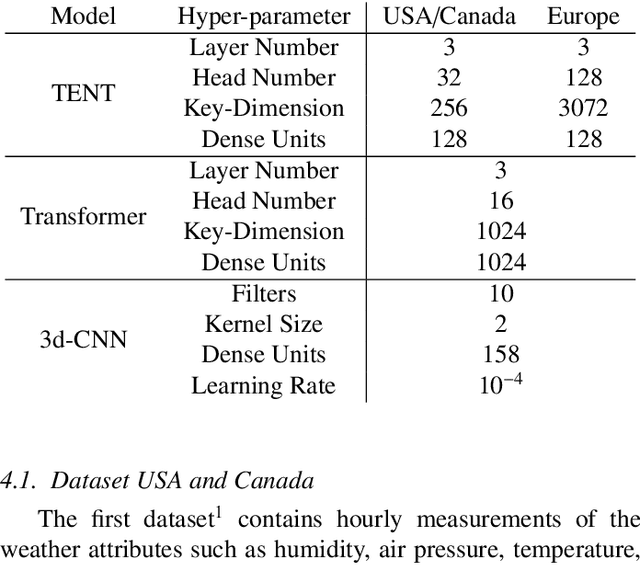

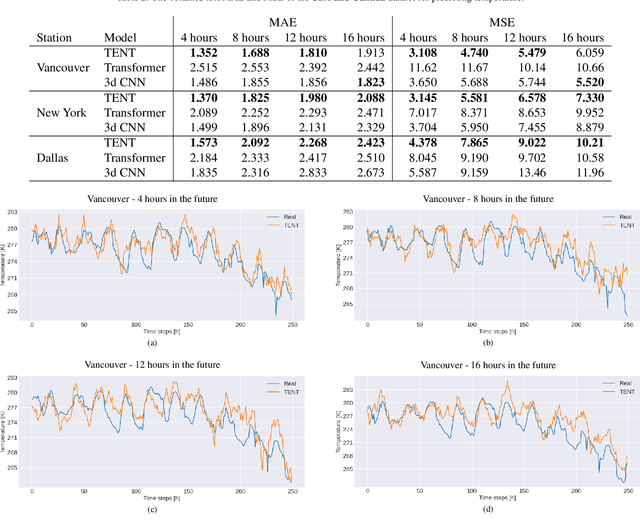
Reliable weather forecasting is of great importance in science, business and society. The best performing data-driven models for weather prediction tasks rely on recurrent or convolutional neural networks, where some of which incorporate attention mechanisms. In this work, we introduce a new model based on the Transformer architecture for weather forecasting. The proposed Tensorial Encoder Transformer (TENT) model is equipped with tensorial attention and thus it exploits the spatiotemporal structure of weather data by processing it in multidimensional tensorial format. We show that compared to the encoder part of the original transformer and 3D convolutional neural networks, the proposed TENT model can better model the underlying complex pattern of weather data for the studied temperature prediction task. Experiments on two real-life weather datasets are performed. The datasets consist of historical measurements from USA, Canada and European cities. The first dataset contains hourly measurements of weather attributes for 30 cities in USA and Canada from October 2012 to November 2017. The second dataset contains daily measurements of weather attributes of 18 cities across Europe from May 2005 to April 2020. We use attention scores calculated from our attention mechanism to shed light on the decision-making process of our model and have insight knowledge on the most important cities for the task.