 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmaAT-QMix-UNet: A Parameter-Efficient Vector-Quantized UNet for Precipitation Nowcasting
Mar 23, 2026Weather forecasting supports critical socioeconomic activities and complements environmental protection, yet operational Numerical Weather Prediction (NWP) systems remain computationally intensive, thus being inefficient for certain applications. Meanwhile, recent advances in deep data-driven models have demonstrated promising results in nowcasting tasks. This paper presents SmaAT-QMix-UNet, an enhanced variant of SmaAT-UNet that introduces two key innovations: a vector quantization (VQ) bottleneck at the encoder-decoder bridge, and mixed kernel depth-wise convolutions (MixConv) replacing selected encoder and decoder blocks. These enhancements both reduce the model's size and improve its nowcasting performance. We train and evaluate SmaAT-QMix-UNet on a Dutch radar precipitation dataset (2016-2019), predicting precipitation 30 minutes ahead. Three configurations are benchmarked: using only VQ, only MixConv, and the full SmaAT-QMix-UNet. Grad-CAM saliency maps highlight the regions influencing each nowcast, while a UMAP embedding of the codewords illustrates how the VQ layer clusters encoder outputs. The source code for SmaAT-QMix-UNet is publicly available on GitHub \footnote{\href{https://github.com/nstavr04/MasterThesisSnellius}{https://github.com/nstavr04/MasterThesisSnellius}}.
MAD-SmaAt-GNet: A Multimodal Advection-Guided Neural Network for Precipitation Nowcasting
Mar 03, 2026Precipitation nowcasting (short-term forecasting) is still often performed using numerical solvers for physical equations, which are computationally expensive and make limited use of the large volumes of available weather data. Deep learning models have shown strong potential for precipitation nowcasting, offering both accuracy and computational efficiency. Among these models, convolutional neural networks (CNNs) are particularly effective for image-to-image prediction tasks. The SmaAt-UNet is a lightweight CNN based architecture that has demonstrated strong performance for precipitation nowcasting. This paper introduces the Multimodal Advection-Guided Small Attention GNet (MAD-SmaAt-GNet), which extends the core SmaAt-UNet by (i) incorporating an additional encoder to learn from multiple weather variables and (ii) integrating a physics-based advection component to ensure physically consistent predictions. We show that each extension individually improves rainfall forecasts and that their combination yields further gains. MAD-SmaAt-GNet reduces the mean squared error (MSE) by 8.9% compared with the baseline SmaAt-UNet for four-step precipitation forecasting up to four hours ahead. Additionally, experiments indicate that multimodal inputs are particularly beneficial for short lead times, while the advection-based component enhances performance across both short and long forecasting horizons.
AnySleep: a channel-agnostic deep learning system for high-resolution sleep staging in multi-center cohorts
Dec 16, 2025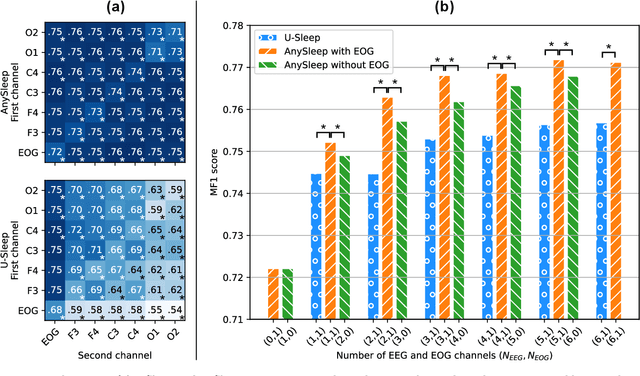
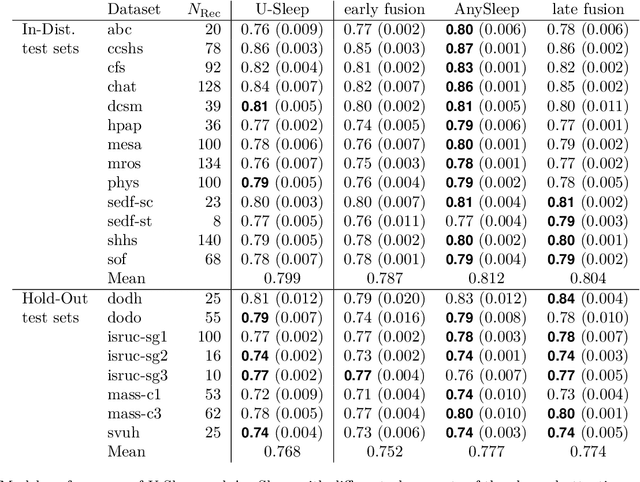
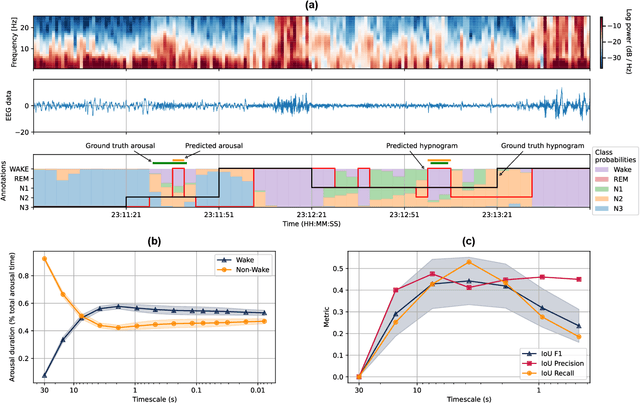
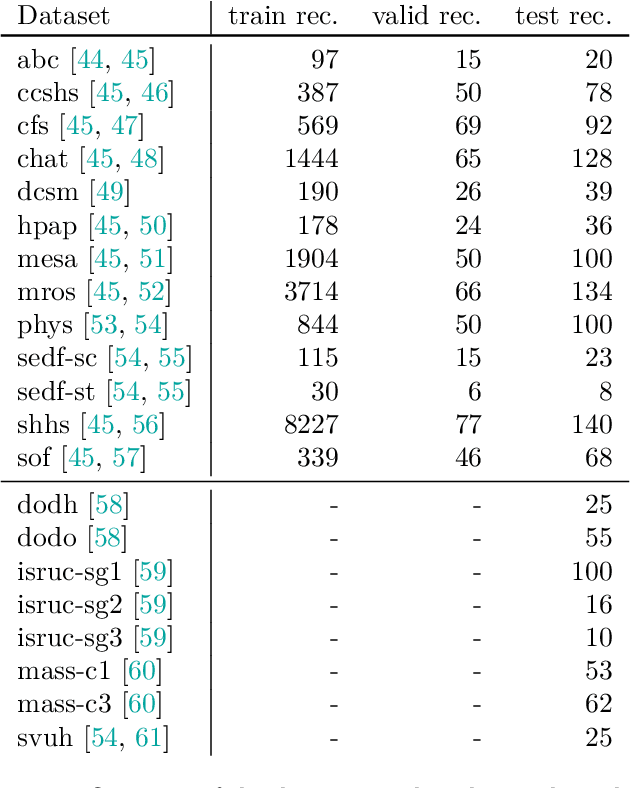
Sleep is essential for good health throughout our lives, yet studying its dynamics requires manual sleep staging, a labor-intensive step in sleep research and clinical care. Across centers, polysomnography (PSG) recordings are traditionally scored in 30-s epochs for pragmatic, not physiological, reasons and can vary considerably in electrode count, montage, and subject characteristics. These constraints present challenges in conducting harmonized multi-center sleep studies and discovering novel, robust biomarkers on shorter timescales. Here, we present AnySleep, a deep neural network model that uses any electroencephalography (EEG) or electrooculography (EOG) data to score sleep at adjustable temporal resolutions. We trained and validated the model on over 19,000 overnight recordings from 21 datasets collected across multiple clinics, spanning nearly 200,000 hours of EEG and EOG data, to promote robust generalization across sites. The model attains state-of-the-art performance and surpasses or equals established baselines at 30-s epochs. Performance improves as more channels are provided, yet remains strong when EOG is absent or when only EOG or single EEG derivations (frontal, central, or occipital) are available. On sub-30-s timescales, the model captures short wake intrusions consistent with arousals and improves prediction of physiological characteristics (age, sex) and pathophysiological conditions (sleep apnea), relative to standard 30-s scoring. We make the model publicly available to facilitate large-scale studies with heterogeneous electrode setups and to accelerate the discovery of novel biomarkers in sleep.
From Sleep Staging to Spindle Detection: Evaluating End-to-End Automated Sleep Analysis
May 08, 2025Automation of sleep analysis, including both macrostructural (sleep stages) and microstructural (e.g., sleep spindles) elements, promises to enable large-scale sleep studies and to reduce variance due to inter-rater incongruencies. While individual steps, such as sleep staging and spindle detection, have been studied separately, the feasibility of automating multi-step sleep analysis remains unclear. Here, we evaluate whether a fully automated analysis using state-of-the-art machine learning models for sleep staging (RobustSleepNet) and subsequent spindle detection (SUMOv2) can replicate findings from an expert-based study of bipolar disorder. The automated analysis qualitatively reproduced key findings from the expert-based study, including significant differences in fast spindle densities between bipolar patients and healthy controls, accomplishing in minutes what previously took months to complete manually. While the results of the automated analysis differed quantitatively from the expert-based study, possibly due to biases between expert raters or between raters and the models, the models individually performed at or above inter-rater agreement for both sleep staging and spindle detection. Our results demonstrate that fully automated approaches have the potential to facilitate large-scale sleep research. We are providing public access to the tools used in our automated analysis by sharing our code and introducing SomnoBot, a privacy-preserving sleep analysis platform.
SSA-UNet: Advanced Precipitation Nowcasting via Channel Shuffling
Apr 25, 2025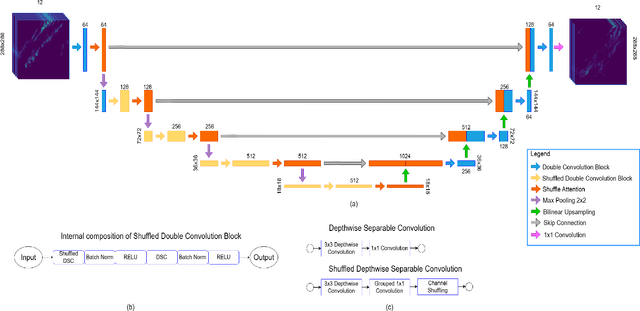
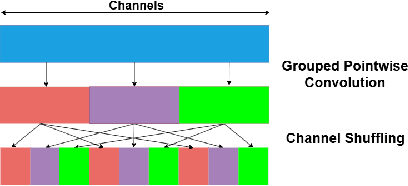
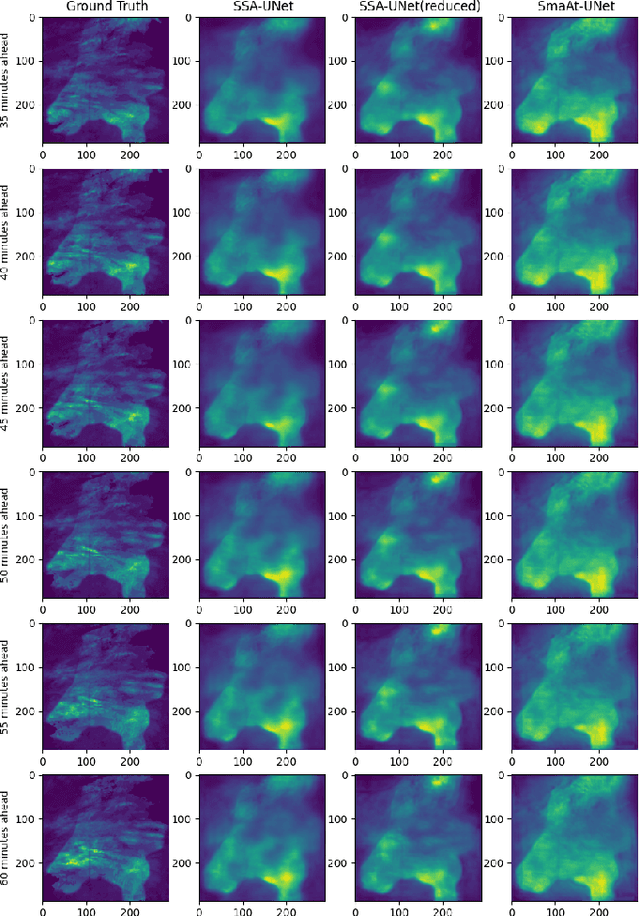
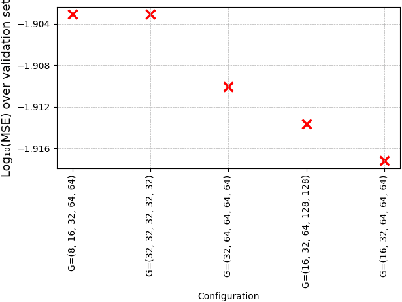
Weather forecasting is essential for facilitating diverse socio-economic activity and environmental conservation initiatives. Deep learning techniques are increasingly being explored as complementary approaches to Numerical Weather Prediction (NWP) models, offering potential benefits such as reduced complexity and enhanced adaptability in specific applications. This work presents a novel design, Small Shuffled Attention UNet (SSA-UNet), which enhances SmaAt-UNet's architecture by including a shuffle channeling mechanism to optimize performance and diminish complexity. To assess its efficacy, this architecture and its reduced variant are examined and trained on two datasets: a Dutch precipitation dataset from 2016 to 2019, and a French cloud cover dataset containing radar images from 2017 to 2018. Three output configurations of the proposed architecture are evaluated, yielding outputs of 1, 6, and 12 precipitation maps, respectively. To better understand how this model operates and produces its predictions, a gradient-based approach called Grad-CAM is used to analyze the outputs generated. The analysis of heatmaps generated by Grad-CAM facilitated the identification of regions within the input maps that the model considers most informative for generating its predictions. The implementation of SSA-UNet can be found on our Github\footnote{\href{https://github.com/MarcoTurzi/SSA-UNet}{https://github.com/MarcoTurzi/SSA-UNet}}
Integrating Weather Station Data and Radar for Precipitation Nowcasting: SmaAt-fUsion and SmaAt-Krige-GNet
Feb 22, 2025



In recent years, data-driven, deep learning-based approaches for precipitation nowcasting have attracted significant attention, showing promising results. However, many existing models fail to fully exploit the extensive atmospheric information available, relying primarily on precipitation data alone. This study introduces two novel deep learning architectures, SmaAt-fUsion and SmaAt-Krige-GNet, specifically designed to enhance precipitation nowcasting by integrating multi-variable weather station data with radar datasets. By leveraging additional meteorological information, these models improve representation learning in the latent space, resulting in enhanced nowcasting performance. The SmaAt-fUsion model extends the SmaAt-UNet framework by incorporating weather station data through a convolutional layer, integrating it into the bottleneck of the network. Conversely, the SmaAt-Krige-GNet model combines precipitation maps with weather station data processed using Kriging, a geo-statistical interpolation method, to generate variable-specific maps. These maps are then utilized in a dual-encoder architecture based on SmaAt-GNet, allowing multi-level data integration. Experimental evaluations were conducted using four years (2016--2019) of weather station and precipitation radar data from the Netherlands. Results demonstrate that SmaAt-Krige-GNet outperforms the standard SmaAt-UNet, which relies solely on precipitation radar data, in low precipitation scenarios, while SmaAt-fUsion surpasses SmaAt-UNet in both low and high precipitation scenarios. This highlights the potential of incorporating discrete weather station data to enhance the performance of deep learning-based weather nowcasting models.
Self-supervised Spatial-Temporal Learner for Precipitation Nowcasting
Dec 20, 2024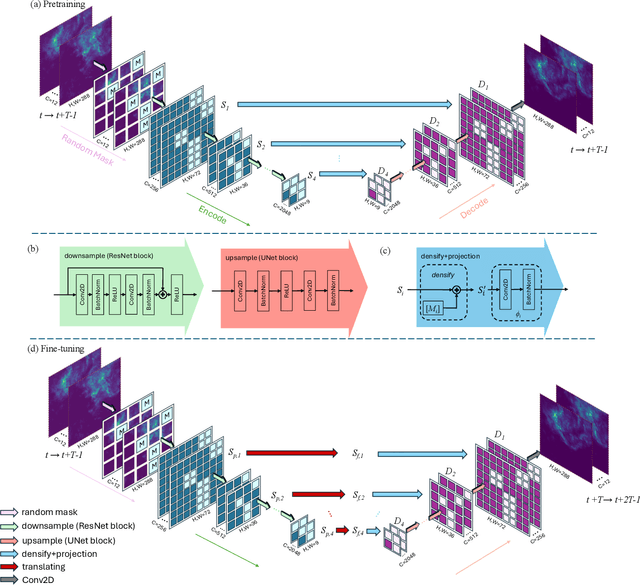
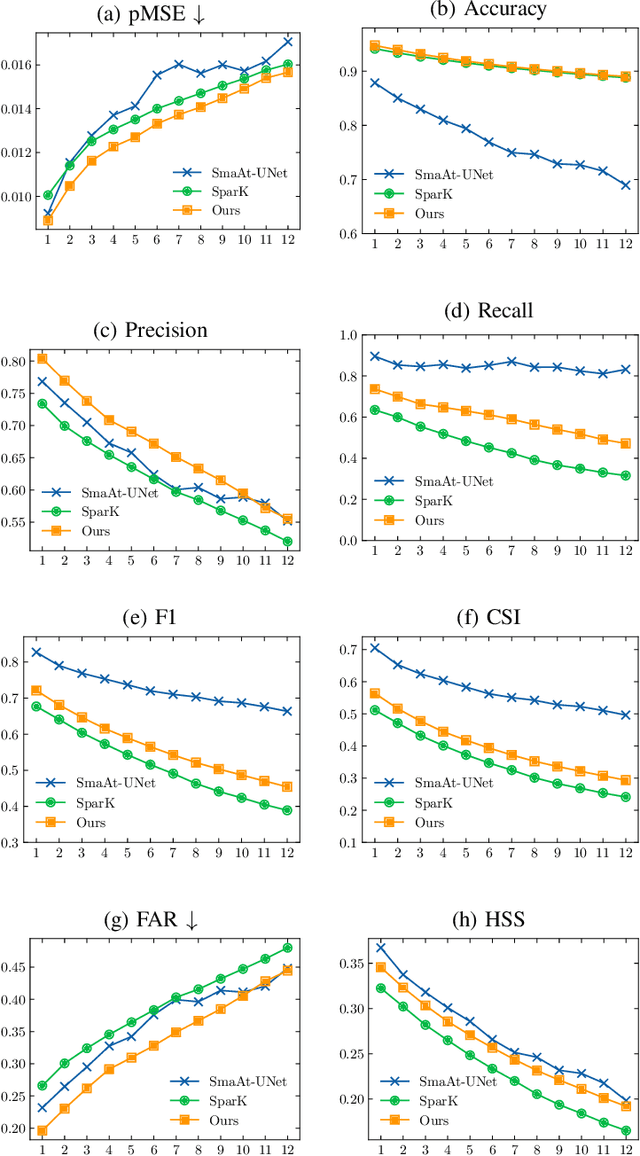
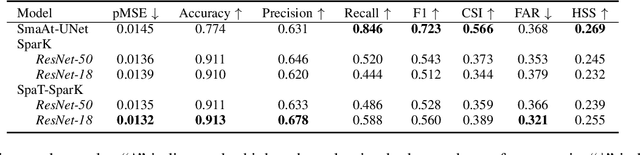

Nowcasting, the short-term prediction of weather, is essential for making timely and weather-dependent decisions. Specifically, precipitation nowcasting aims to predict precipitation at a local level within a 6-hour time frame. This task can be framed as a spatial-temporal sequence forecasting problem, where deep learning methods have been particularly effective. However, despite advancements in self-supervised learning, most successful methods for nowcasting remain fully supervised. Self-supervised learning is advantageous for pretraining models to learn representations without requiring extensive labeled data. In this work, we leverage the benefits of self-supervised learning and integrate it with spatial-temporal learning to develop a novel model, SpaT-SparK. SpaT-SparK comprises a CNN-based encoder-decoder structure pretrained with a masked image modeling (MIM) task and a translation network that captures temporal relationships among past and future precipitation maps in downstream tasks. We conducted experiments on the NL-50 dataset to evaluate the performance of SpaT-SparK. The results demonstrate that SpaT-SparK outperforms existing baseline supervised models, such as SmaAt-UNet, providing more accurate nowcasting predictions.
Data-Efficient Sleep Staging with Synthetic Time Series Pretraining
Mar 13, 2024Analyzing electroencephalographic (EEG) time series can be challenging, especially with deep neural networks, due to the large variability among human subjects and often small datasets. To address these challenges, various strategies, such as self-supervised learning, have been suggested, but they typically rely on extensive empirical datasets. Inspired by recent advances in computer vision, we propose a pretraining task termed "frequency pretraining" to pretrain a neural network for sleep staging by predicting the frequency content of randomly generated synthetic time series. Our experiments demonstrate that our method surpasses fully supervised learning in scenarios with limited data and few subjects, and matches its performance in regimes with many subjects. Furthermore, our results underline the relevance of frequency information for sleep stage scoring, while also demonstrating that deep neural networks utilize information beyond frequencies to enhance sleep staging performance, which is consistent with previous research. We anticipate that our approach will be advantageous across a broad spectrum of applications where EEG data is limited or derived from a small number of subjects, including the domain of brain-computer interfaces.
GA-SmaAt-GNet: Generative Adversarial Small Attention GNet for Extreme Precipitation Nowcasting
Jan 18, 2024In recent years, data-driven modeling approaches have gained considerable traction in various meteorological applications, particularly in the realm of weather forecasting. However, these approaches often encounter challenges when dealing with extreme weather conditions. In light of this, we propose GA-SmaAt-GNet, a novel generative adversarial architecture that makes use of two methodologies aimed at enhancing the performance of deep learning models for extreme precipitation nowcasting. Firstly, it uses a novel SmaAt-GNet built upon the successful SmaAt-UNet architecture as generator. This network incorporates precipitation masks (binarized precipitation maps) as an additional data source, leveraging valuable information for improved predictions. Additionally, GA-SmaAt-GNet utilizes an attention-augmented discriminator inspired by the well-established Pix2Pix architecture. Furthermore, we assess the performance of GA-SmaAt-GNet using real-life precipitation dataset from the Netherlands. Our experimental results reveal a notable improvement in both overall performance and for extreme precipitation events. Furthermore, we conduct uncertainty analysis on the proposed GA-SmaAt-GNet model as well as on the precipitation dataset, providing additional insights into the predictive capabilities of the model. Finally, we offer further insights into the predictions of our proposed model using Grad-CAM. This visual explanation technique generates activation heatmaps, illustrating areas of the input that are more activated for various parts of the network.
GD-CAF: Graph Dual-stream Convolutional Attention Fusion for Precipitation Nowcasting
Jan 15, 2024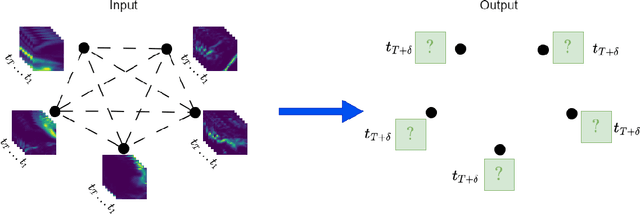
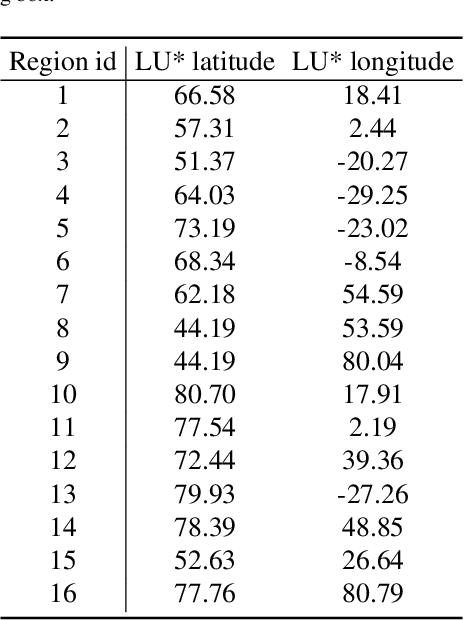
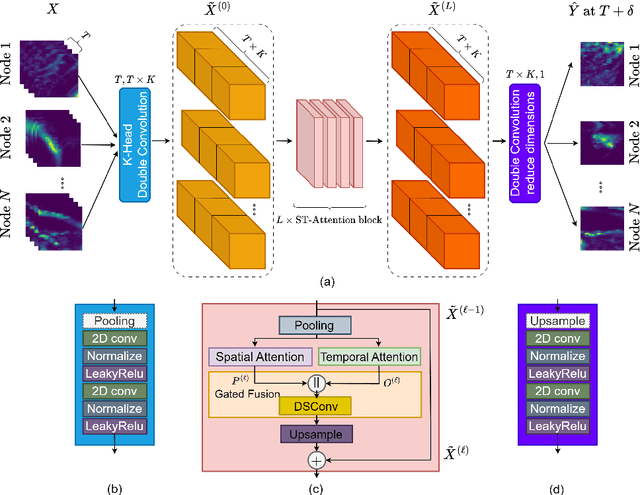
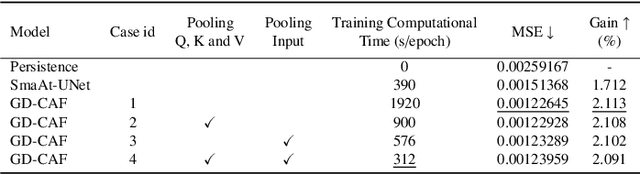
Accurate precipitation nowcasting is essential for various purposes, including flood prediction, disaster management, optimizing agricultural activities, managing transportation routes and renewable energy. While several studies have addressed this challenging task from a sequence-to-sequence perspective, most of them have focused on a single area without considering the existing correlation between multiple disjoint regions. In this paper, we formulate precipitation nowcasting as a spatiotemporal graph sequence nowcasting problem. In particular, we introduce Graph Dual-stream Convolutional Attention Fusion (GD-CAF), a novel approach designed to learn from historical spatiotemporal graph of precipitation maps and nowcast future time step ahead precipitation at different spatial locations. GD-CAF consists of spatio-temporal convolutional attention as well as gated fusion modules which are equipped with depthwise-separable convolutional operations. This enhancement enables the model to directly process the high-dimensional spatiotemporal graph of precipitation maps and exploits higher-order correlations between the data dimensions. We evaluate our model on seven years of precipitation maps across Europe and its neighboring areas collected from the ERA5 dataset, provided by Copernicus. The model receives a fully connected graph in which each node represents historical observations from a specific region on the map. Consequently, each node contains a 3D tensor with time, height, and width dimensions. Experimental results demonstrate that the proposed GD-CAF model outperforms the other examined models. Furthermore, the averaged seasonal spatial and temporal attention scores over the test set are visualized to provide additional insights about the strongest connections between different regions or time steps. These visualizations shed light on the decision-making process of our model.