 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnySleep: a channel-agnostic deep learning system for high-resolution sleep staging in multi-center cohorts
Dec 16, 2025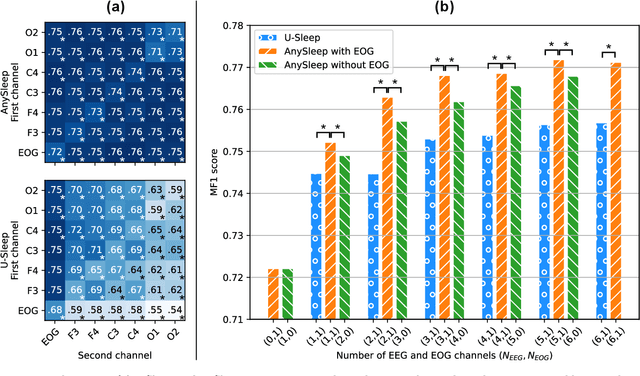
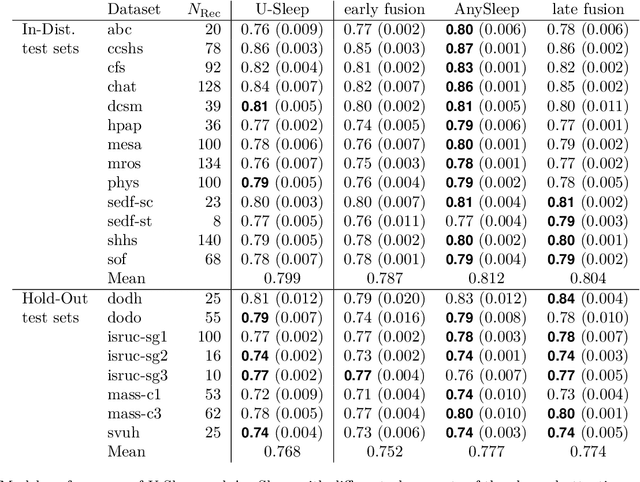
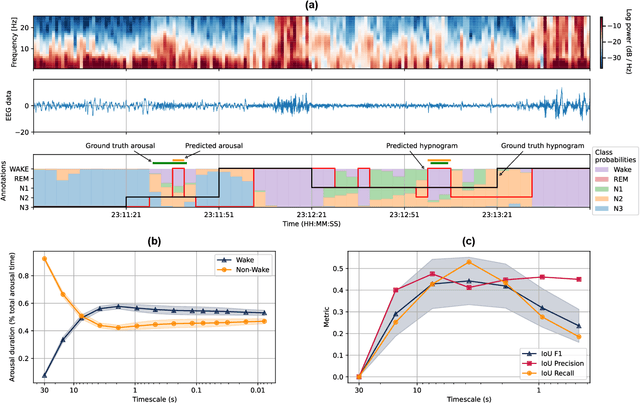
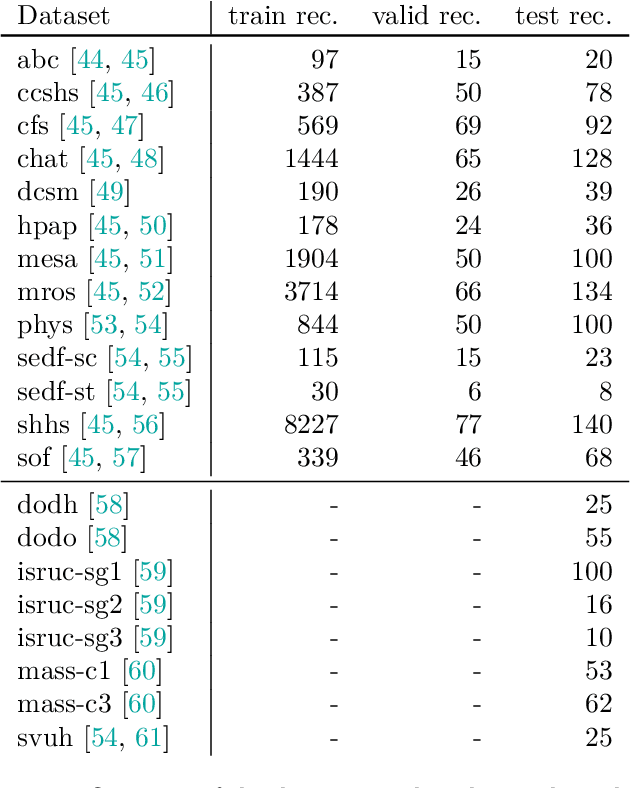
Sleep is essential for good health throughout our lives, yet studying its dynamics requires manual sleep staging, a labor-intensive step in sleep research and clinical care. Across centers, polysomnography (PSG) recordings are traditionally scored in 30-s epochs for pragmatic, not physiological, reasons and can vary considerably in electrode count, montage, and subject characteristics. These constraints present challenges in conducting harmonized multi-center sleep studies and discovering novel, robust biomarkers on shorter timescales. Here, we present AnySleep, a deep neural network model that uses any electroencephalography (EEG) or electrooculography (EOG) data to score sleep at adjustable temporal resolutions. We trained and validated the model on over 19,000 overnight recordings from 21 datasets collected across multiple clinics, spanning nearly 200,000 hours of EEG and EOG data, to promote robust generalization across sites. The model attains state-of-the-art performance and surpasses or equals established baselines at 30-s epochs. Performance improves as more channels are provided, yet remains strong when EOG is absent or when only EOG or single EEG derivations (frontal, central, or occipital) are available. On sub-30-s timescales, the model captures short wake intrusions consistent with arousals and improves prediction of physiological characteristics (age, sex) and pathophysiological conditions (sleep apnea), relative to standard 30-s scoring. We make the model publicly available to facilitate large-scale studies with heterogeneous electrode setups and to accelerate the discovery of novel biomarkers in sleep.
AIxcellent Vibes at GermEval 2025 Shared Task on Candy Speech Detection: Improving Model Performance by Span-Level Training
Sep 09, 2025Positive, supportive online communication in social media (candy speech) has the potential to foster civility, yet automated detection of such language remains underexplored, limiting systematic analysis of its impact. We investigate how candy speech can be reliably detected in a 46k-comment German YouTube corpus by monolingual and multilingual language models, including GBERT, Qwen3 Embedding, and XLM-RoBERTa. We find that a multilingual XLM-RoBERTa-Large model trained to detect candy speech at the span level outperforms other approaches, ranking first in both binary positive F1: 0.8906) and categorized span-based detection (strict F1: 0.6307) subtasks at the GermEval 2025 Shared Task on Candy Speech Detection. We speculate that span-based training, multilingual capabilities, and emoji-aware tokenizers improved detection performance. Our results demonstrate the effectiveness of multilingual models in identifying positive, supportive language.
From Sleep Staging to Spindle Detection: Evaluating End-to-End Automated Sleep Analysis
May 08, 2025Automation of sleep analysis, including both macrostructural (sleep stages) and microstructural (e.g., sleep spindles) elements, promises to enable large-scale sleep studies and to reduce variance due to inter-rater incongruencies. While individual steps, such as sleep staging and spindle detection, have been studied separately, the feasibility of automating multi-step sleep analysis remains unclear. Here, we evaluate whether a fully automated analysis using state-of-the-art machine learning models for sleep staging (RobustSleepNet) and subsequent spindle detection (SUMOv2) can replicate findings from an expert-based study of bipolar disorder. The automated analysis qualitatively reproduced key findings from the expert-based study, including significant differences in fast spindle densities between bipolar patients and healthy controls, accomplishing in minutes what previously took months to complete manually. While the results of the automated analysis differed quantitatively from the expert-based study, possibly due to biases between expert raters or between raters and the models, the models individually performed at or above inter-rater agreement for both sleep staging and spindle detection. Our results demonstrate that fully automated approaches have the potential to facilitate large-scale sleep research. We are providing public access to the tools used in our automated analysis by sharing our code and introducing SomnoBot, a privacy-preserving sleep analysis platform.
Detecting Sexism in German Online Newspaper Comments with Open-Source Text Embeddings (Team GDA, GermEval2024 Shared Task 1: GerMS-Detect, Subtasks 1 and 2, Closed Track)
Sep 16, 2024Sexism in online media comments is a pervasive challenge that often manifests subtly, complicating moderation efforts as interpretations of what constitutes sexism can vary among individuals. We study monolingual and multilingual open-source text embeddings to reliably detect sexism and misogyny in German-language online comments from an Austrian newspaper. We observed classifiers trained on text embeddings to mimic closely the individual judgements of human annotators. Our method showed robust performance in the GermEval 2024 GerMS-Detect Subtask 1 challenge, achieving an average macro F1 score of 0.597 (4th place, as reported on Codabench). It also accurately predicted the distribution of human annotations in GerMS-Detect Subtask 2, with an average Jensen-Shannon distance of 0.301 (2nd place). The computational efficiency of our approach suggests potential for scalable applications across various languages and linguistic contexts.
Data-Efficient Sleep Staging with Synthetic Time Series Pretraining
Mar 13, 2024Analyzing electroencephalographic (EEG) time series can be challenging, especially with deep neural networks, due to the large variability among human subjects and often small datasets. To address these challenges, various strategies, such as self-supervised learning, have been suggested, but they typically rely on extensive empirical datasets. Inspired by recent advances in computer vision, we propose a pretraining task termed "frequency pretraining" to pretrain a neural network for sleep staging by predicting the frequency content of randomly generated synthetic time series. Our experiments demonstrate that our method surpasses fully supervised learning in scenarios with limited data and few subjects, and matches its performance in regimes with many subjects. Furthermore, our results underline the relevance of frequency information for sleep stage scoring, while also demonstrating that deep neural networks utilize information beyond frequencies to enhance sleep staging performance, which is consistent with previous research. We anticipate that our approach will be advantageous across a broad spectrum of applications where EEG data is limited or derived from a small number of subjects, including the domain of brain-computer interfaces.
Speaker attribution in German parliamentary debates with QLoRA-adapted large language models
Sep 18, 2023



The growing body of political texts opens up new opportunities for rich insights into political dynamics and ideologies but also increases the workload for manual analysis. Automated speaker attribution, which detects who said what to whom in a speech event and is closely related to semantic role labeling, is an important processing step for computational text analysis. We study the potential of the large language model family Llama 2 to automate speaker attribution in German parliamentary debates from 2017-2021. We fine-tune Llama 2 with QLoRA, an efficient training strategy, and observe our approach to achieve competitive performance in the GermEval 2023 Shared Task On Speaker Attribution in German News Articles and Parliamentary Debates. Our results shed light on the capabilities of large language models in automating speaker attribution, revealing a promising avenue for computational analysis of political discourse and the development of semantic role labeling systems.
Automatic Readability Assessment of German Sentences with Transformer Ensembles
Sep 09, 2022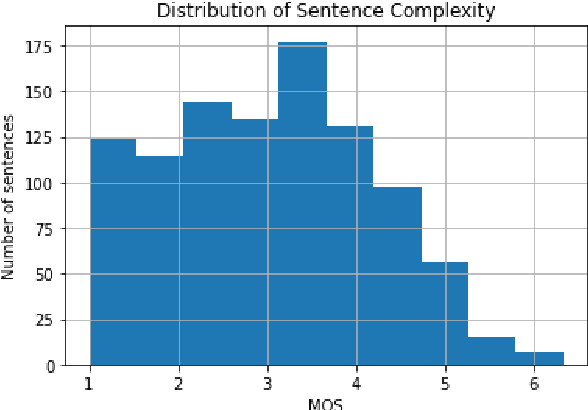

Reliable methods for automatic readability assessment have the potential to impact a variety of fields, ranging from machine translation to self-informed learning. Recently, large language models for the German language (such as GBERT and GPT-2-Wechsel) have become available, allowing to develop Deep Learning based approaches that promise to further improve automatic readability assessment. In this contribution, we studied the ability of ensembles of fine-tuned GBERT and GPT-2-Wechsel models to reliably predict the readability of German sentences. We combined these models with linguistic features and investigated the dependence of prediction performance on ensemble size and composition. Mixed ensembles of GBERT and GPT-2-Wechsel performed better than ensembles of the same size consisting of only GBERT or GPT-2-Wechsel models. Our models were evaluated in the GermEval 2022 Shared Task on Text Complexity Assessment on data of German sentences. On out-of-sample data, our best ensemble achieved a root mean squared error of 0.435.
* 6 pages, 3 figures
FHAC at GermEval 2021: Identifying German toxic, engaging, and fact-claiming comments with ensemble learning
Sep 07, 2021
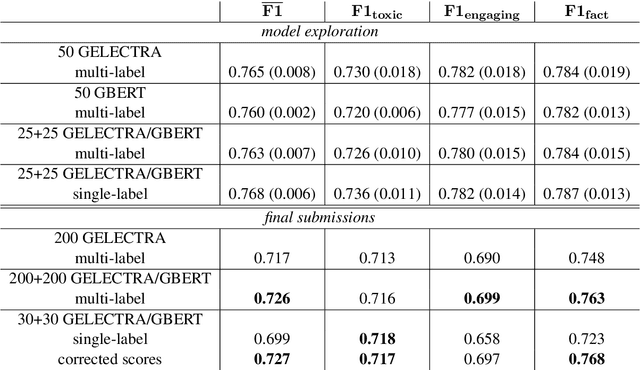

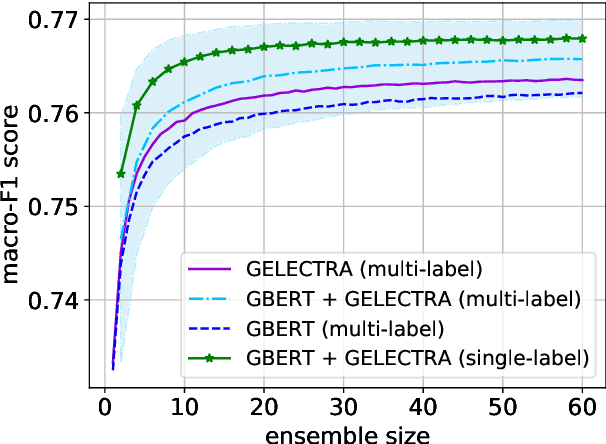
The availability of language representations learned by large pretrained neural network models (such as BERT and ELECTRA) has led to improvements in many downstream Natural Language Processing tasks in recent years. Pretrained models usually differ in pretraining objectives, architectures, and datasets they are trained on which can affect downstream performance. In this contribution, we fine-tuned German BERT and German ELECTRA models to identify toxic (subtask 1), engaging (subtask 2), and fact-claiming comments (subtask 3) in Facebook data provided by the GermEval 2021 competition. We created ensembles of these models and investigated whether and how classification performance depends on the number of ensemble members and their composition. On out-of-sample data, our best ensemble achieved a macro-F1 score of 0.73 (for all subtasks), and F1 scores of 0.72, 0.70, and 0.76 for subtasks 1, 2, and 3, respectively.
* 7 pages, 2 figures
Automated scoring of pre-REM sleep in mice with deep learning
May 05, 2021
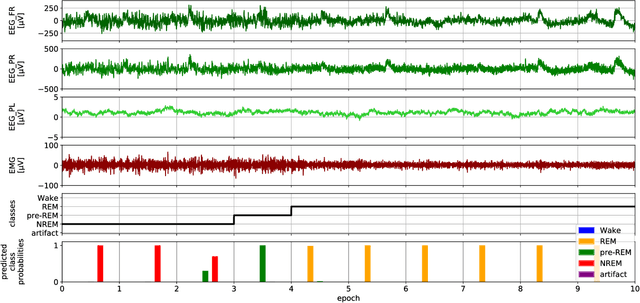

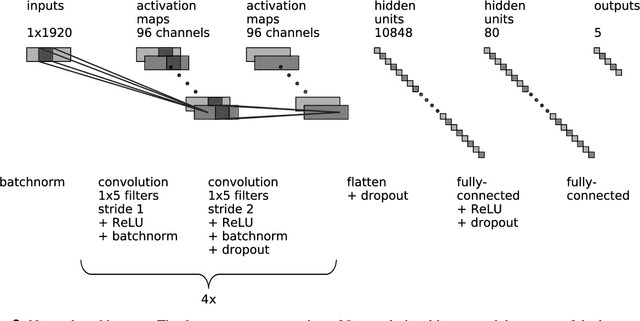
Reliable automation of the labor-intensive manual task of scoring animal sleep can facilitate the analysis of long-term sleep studies. In recent years, deep-learning-based systems, which learn optimal features from the data, increased scoring accuracies for the classical sleep stages of Wake, REM, and Non-REM. Meanwhile, it has been recognized that the statistics of transitional stages such as pre-REM, found between Non-REM and REM, may hold additional insight into the physiology of sleep and are now under vivid investigation. We propose a classification system based on a simple neural network architecture that scores the classical stages as well as pre-REM sleep in mice. When restricted to the classical stages, the optimized network showed state-of-the-art classification performance with an out-of-sample F1 score of 0.95. When unrestricted, the network showed lower F1 scores on pre-REM (0.5) compared to the classical stages. The result is comparable to previous attempts to score transitional stages in other species such as transition sleep in rats or N1 sleep in humans. Nevertheless, we observed that the sequence of predictions including pre-REM typically transitioned from Non-REM to REM reflecting sleep dynamics observed by human scorers. Our findings provide further evidence for the difficulty of scoring transitional sleep stages, likely because such stages of sleep are under-represented in typical data sets or show large inter-scorer variability. We further provide our source code and an online platform to run predictions with our trained network.