 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIxcellent Vibes at GermEval 2025 Shared Task on Candy Speech Detection: Improving Model Performance by Span-Level Training
Sep 09, 2025Positive, supportive online communication in social media (candy speech) has the potential to foster civility, yet automated detection of such language remains underexplored, limiting systematic analysis of its impact. We investigate how candy speech can be reliably detected in a 46k-comment German YouTube corpus by monolingual and multilingual language models, including GBERT, Qwen3 Embedding, and XLM-RoBERTa. We find that a multilingual XLM-RoBERTa-Large model trained to detect candy speech at the span level outperforms other approaches, ranking first in both binary positive F1: 0.8906) and categorized span-based detection (strict F1: 0.6307) subtasks at the GermEval 2025 Shared Task on Candy Speech Detection. We speculate that span-based training, multilingual capabilities, and emoji-aware tokenizers improved detection performance. Our results demonstrate the effectiveness of multilingual models in identifying positive, supportive language.
Detecting Sexism in German Online Newspaper Comments with Open-Source Text Embeddings (Team GDA, GermEval2024 Shared Task 1: GerMS-Detect, Subtasks 1 and 2, Closed Track)
Sep 16, 2024Sexism in online media comments is a pervasive challenge that often manifests subtly, complicating moderation efforts as interpretations of what constitutes sexism can vary among individuals. We study monolingual and multilingual open-source text embeddings to reliably detect sexism and misogyny in German-language online comments from an Austrian newspaper. We observed classifiers trained on text embeddings to mimic closely the individual judgements of human annotators. Our method showed robust performance in the GermEval 2024 GerMS-Detect Subtask 1 challenge, achieving an average macro F1 score of 0.597 (4th place, as reported on Codabench). It also accurately predicted the distribution of human annotations in GerMS-Detect Subtask 2, with an average Jensen-Shannon distance of 0.301 (2nd place). The computational efficiency of our approach suggests potential for scalable applications across various languages and linguistic contexts.
Speaker attribution in German parliamentary debates with QLoRA-adapted large language models
Sep 18, 2023



The growing body of political texts opens up new opportunities for rich insights into political dynamics and ideologies but also increases the workload for manual analysis. Automated speaker attribution, which detects who said what to whom in a speech event and is closely related to semantic role labeling, is an important processing step for computational text analysis. We study the potential of the large language model family Llama 2 to automate speaker attribution in German parliamentary debates from 2017-2021. We fine-tune Llama 2 with QLoRA, an efficient training strategy, and observe our approach to achieve competitive performance in the GermEval 2023 Shared Task On Speaker Attribution in German News Articles and Parliamentary Debates. Our results shed light on the capabilities of large language models in automating speaker attribution, revealing a promising avenue for computational analysis of political discourse and the development of semantic role labeling systems.
Automatic Readability Assessment of German Sentences with Transformer Ensembles
Sep 09, 2022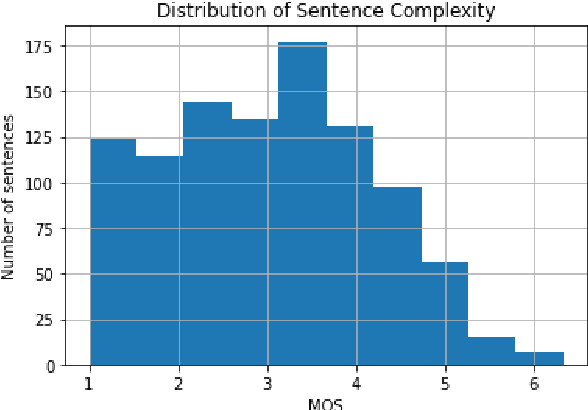

Reliable methods for automatic readability assessment have the potential to impact a variety of fields, ranging from machine translation to self-informed learning. Recently, large language models for the German language (such as GBERT and GPT-2-Wechsel) have become available, allowing to develop Deep Learning based approaches that promise to further improve automatic readability assessment. In this contribution, we studied the ability of ensembles of fine-tuned GBERT and GPT-2-Wechsel models to reliably predict the readability of German sentences. We combined these models with linguistic features and investigated the dependence of prediction performance on ensemble size and composition. Mixed ensembles of GBERT and GPT-2-Wechsel performed better than ensembles of the same size consisting of only GBERT or GPT-2-Wechsel models. Our models were evaluated in the GermEval 2022 Shared Task on Text Complexity Assessment on data of German sentences. On out-of-sample data, our best ensemble achieved a root mean squared error of 0.435.
* 6 pages, 3 figures
FHAC at GermEval 2021: Identifying German toxic, engaging, and fact-claiming comments with ensemble learning
Sep 07, 2021
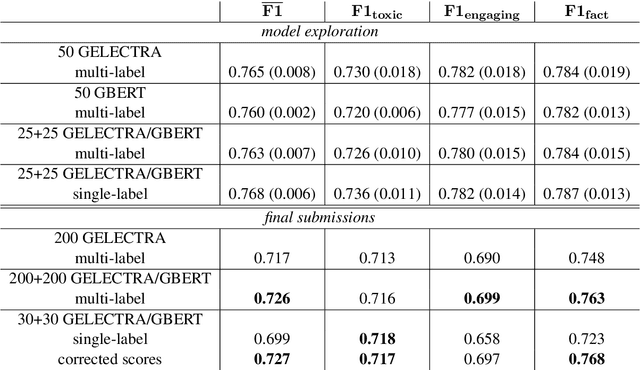

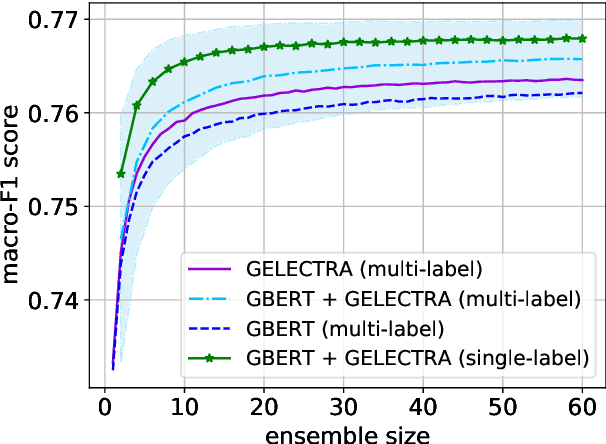
The availability of language representations learned by large pretrained neural network models (such as BERT and ELECTRA) has led to improvements in many downstream Natural Language Processing tasks in recent years. Pretrained models usually differ in pretraining objectives, architectures, and datasets they are trained on which can affect downstream performance. In this contribution, we fine-tuned German BERT and German ELECTRA models to identify toxic (subtask 1), engaging (subtask 2), and fact-claiming comments (subtask 3) in Facebook data provided by the GermEval 2021 competition. We created ensembles of these models and investigated whether and how classification performance depends on the number of ensemble members and their composition. On out-of-sample data, our best ensemble achieved a macro-F1 score of 0.73 (for all subtasks), and F1 scores of 0.72, 0.70, and 0.76 for subtasks 1, 2, and 3, respectively.
* 7 pages, 2 figures