 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOver-the-Air Adversarial Attack Detection: from Datasets to Defenses
Sep 11, 2025



Automatic Speaker Verification (ASV) systems can be used for voice-enabled applications for identity verification. However, recent studies have exposed these systems' vulnerabilities to both over-the-line (OTL) and over-the-air (OTA) adversarial attacks. Although various detection methods have been proposed to counter these threats, they have not been thoroughly tested due to the lack of a comprehensive data set. To address this gap, we developed the AdvSV 2.0 dataset, which contains 628k samples with a total duration of 800 hours. This dataset incorporates classical adversarial attack algorithms, ASV systems, and encompasses both OTL and OTA scenarios. Furthermore, we introduce a novel adversarial attack method based on a Neural Replay Simulator (NRS), which enhances the potency of adversarial OTA attacks, thereby presenting a greater threat to ASV systems. To defend against these attacks, we propose CODA-OCC, a contrastive learning approach within the one-class classification framework. Experimental results show that CODA-OCC achieves an EER of 11.2% and an AUC of 0.95 on the AdvSV 2.0 dataset, outperforming several state-of-the-art detection methods.
Enhanced Prediction of CAR T-Cell Cytotoxicity with Quantum-Kernel Methods
Jul 30, 2025Chimeric antigen receptor (CAR) T-cells are T-cells engineered to recognize and kill specific tumor cells. Through their extracellular domains, CAR T-cells bind tumor cell antigens which triggers CAR T activation and proliferation. These processes are regulated by co-stimulatory domains present in the intracellular region of the CAR T-cell. Through integrating novel signaling components into the co-stimulatory domains, it is possible to modify CAR T-cell phenotype. Identifying and experimentally testing new CAR constructs based on libraries of co-stimulatory domains is nontrivial given the vast combinatorial space defined by such libraries. This leads to a highly data constrained, poorly explored combinatorial problem, where the experiments undersample all possible combinations. We propose a quantum approach using a Projected Quantum Kernel (PQK) to address this challenge. PQK operates by embedding classical data into a high dimensional Hilbert space and employs a kernel method to measure sample similarity. Using 61 qubits on a gate-based quantum computer, we demonstrate the largest PQK application to date and an enhancement in the classification performance over purely classical machine learning methods for CAR T cytotoxicity prediction. Importantly, we show improved learning for specific signaling domains and domain positions, particularly where there was lower information highlighting the potential for quantum computing in data-constrained problems.
ACE: Concept Editing in Diffusion Models without Performance Degradation
Mar 11, 2025



Diffusion-based text-to-image models have demonstrated remarkable capabilities in generating realistic images, but they raise societal and ethical concerns, such as the creation of unsafe content. While concept editing is proposed to address these issues, they often struggle to balance the removal of unsafe concept with maintaining the model's general genera-tive capabilities. In this work, we propose ACE, a new editing method that enhances concept editing in diffusion models. ACE introduces a novel cross null-space projection approach to precisely erase unsafe concept while maintaining the model's ability to generate high-quality, semantically consistent images. Extensive experiments demonstrate that ACE significantly outperforms the advancing baselines,improving semantic consistency by 24.56% and image generation quality by 34.82% on average with only 1% of the time cost. These results highlight the practical utility of concept editing by mitigating its potential risks, paving the way for broader applications in the field. Code is avaliable at https://github.com/littlelittlenine/ACE-zero.git
Integrating Weather Station Data and Radar for Precipitation Nowcasting: SmaAt-fUsion and SmaAt-Krige-GNet
Feb 22, 2025



In recent years, data-driven, deep learning-based approaches for precipitation nowcasting have attracted significant attention, showing promising results. However, many existing models fail to fully exploit the extensive atmospheric information available, relying primarily on precipitation data alone. This study introduces two novel deep learning architectures, SmaAt-fUsion and SmaAt-Krige-GNet, specifically designed to enhance precipitation nowcasting by integrating multi-variable weather station data with radar datasets. By leveraging additional meteorological information, these models improve representation learning in the latent space, resulting in enhanced nowcasting performance. The SmaAt-fUsion model extends the SmaAt-UNet framework by incorporating weather station data through a convolutional layer, integrating it into the bottleneck of the network. Conversely, the SmaAt-Krige-GNet model combines precipitation maps with weather station data processed using Kriging, a geo-statistical interpolation method, to generate variable-specific maps. These maps are then utilized in a dual-encoder architecture based on SmaAt-GNet, allowing multi-level data integration. Experimental evaluations were conducted using four years (2016--2019) of weather station and precipitation radar data from the Netherlands. Results demonstrate that SmaAt-Krige-GNet outperforms the standard SmaAt-UNet, which relies solely on precipitation radar data, in low precipitation scenarios, while SmaAt-fUsion surpasses SmaAt-UNet in both low and high precipitation scenarios. This highlights the potential of incorporating discrete weather station data to enhance the performance of deep learning-based weather nowcasting models.
SpMis: An Investigation of Synthetic Spoken Misinformation Detection
Sep 17, 2024



In recent years, speech generation technology has advanced rapidly, fueled by generative models and large-scale training techniques. While these developments have enabled the production of high-quality synthetic speech, they have also raised concerns about the misuse of this technology, particularly for generating synthetic misinformation. Current research primarily focuses on distinguishing machine-generated speech from human-produced speech, but the more urgent challenge is detecting misinformation within spoken content. This task requires a thorough analysis of factors such as speaker identity, topic, and synthesis. To address this need, we conduct an initial investigation into synthetic spoken misinformation detection by introducing an open-source dataset, SpMis. SpMis includes speech synthesized from over 1,000 speakers across five common topics, utilizing state-of-the-art text-to-speech systems. Although our results show promising detection capabilities, they also reveal substantial challenges for practical implementation, underscoring the importance of ongoing research in this critical area.
ADBM: Adversarial diffusion bridge model for reliable adversarial purification
Aug 01, 2024



Recently Diffusion-based Purification (DiffPure) has been recognized as an effective defense method against adversarial examples. However, we find DiffPure which directly employs the original pre-trained diffusion models for adversarial purification, to be suboptimal. This is due to an inherent trade-off between noise purification performance and data recovery quality. Additionally, the reliability of existing evaluations for DiffPure is questionable, as they rely on weak adaptive attacks. In this work, we propose a novel Adversarial Diffusion Bridge Model, termed ADBM. ADBM directly constructs a reverse bridge from the diffused adversarial data back to its original clean examples, enhancing the purification capabilities of the original diffusion models. Through theoretical analysis and experimental validation across various scenarios, ADBM has proven to be a superior and robust defense mechanism, offering significant promise for practical applications.
Mitigating Hallucinations in Large Language Models via Self-Refinement-Enhanced Knowledge Retrieval
May 10, 2024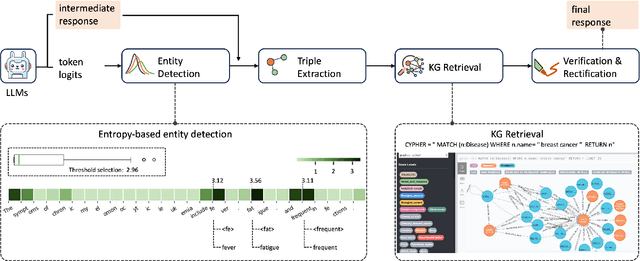
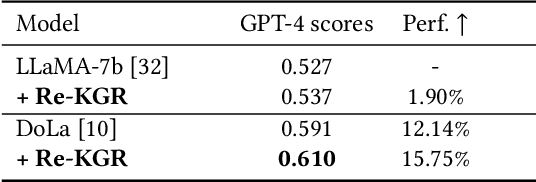
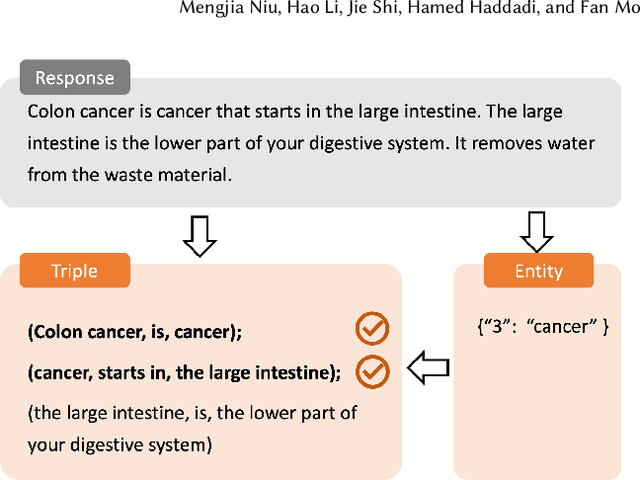

Large language models (LLMs) have demonstrated remarkable capabilities across various domains, although their susceptibility to hallucination poses significant challenges for their deployment in critical areas such as healthcare. To address this issue, retrieving relevant facts from knowledge graphs (KGs) is considered a promising method. Existing KG-augmented approaches tend to be resource-intensive, requiring multiple rounds of retrieval and verification for each factoid, which impedes their application in real-world scenarios. In this study, we propose Self-Refinement-Enhanced Knowledge Graph Retrieval (Re-KGR) to augment the factuality of LLMs' responses with less retrieval efforts in the medical field. Our approach leverages the attribution of next-token predictive probability distributions across different tokens, and various model layers to primarily identify tokens with a high potential for hallucination, reducing verification rounds by refining knowledge triples associated with these tokens. Moreover, we rectify inaccurate content using retrieved knowledge in the post-processing stage, which improves the truthfulness of generated responses. Experimental results on a medical dataset demonstrate that our approach can enhance the factual capability of LLMs across various foundational models as evidenced by the highest scores on truthfulness.
Enhancing Confidence Expression in Large Language Models Through Learning from Past Experience
Apr 16, 2024



Large Language Models (LLMs) have exhibited remarkable performance across various downstream tasks, but they may generate inaccurate or false information with a confident tone. One of the possible solutions is to empower the LLM confidence expression capability, in which the confidence expressed can be well-aligned with the true probability of the generated answer being correct. However, leveraging the intrinsic ability of LLMs or the signals from the output logits of answers proves challenging in accurately capturing the response uncertainty in LLMs. Therefore, drawing inspiration from cognitive diagnostics, we propose a method of Learning from Past experience (LePe) to enhance the capability for confidence expression. Specifically, we first identify three key problems: (1) How to capture the inherent confidence of the LLM? (2) How to teach the LLM to express confidence? (3) How to evaluate the confidence expression of the LLM? Then we devise three stages in LePe to deal with these problems. Besides, to accurately capture the confidence of an LLM when constructing the training data, we design a complete pipeline including question preparation and answer sampling. We also conduct experiments using the Llama family of LLMs to verify the effectiveness of our proposed method on four datasets.
Large Language Model Can Continue Evolving From Mistakes
Apr 11, 2024



Large Language Models (LLMs) demonstrate impressive performance in various downstream tasks. However, they may still generate incorrect responses in certain scenarios due to the knowledge deficiencies and the flawed pre-training data. Continual Learning (CL) is a commonly used method to address this issue. Traditional CL is task-oriented, using novel or factually accurate data to retrain LLMs from scratch. However, this method requires more task-related training data and incurs expensive training costs. To address this challenge, we propose the Continue Evolving from Mistakes (CEM) method, inspired by the 'summarize mistakes' learning skill, to achieve iterative refinement of LLMs. Specifically, the incorrect responses of LLMs indicate knowledge deficiencies related to the questions. Therefore, we collect corpora with these knowledge from multiple data sources and follow it up with iterative supplementary training for continuous, targeted knowledge updating and supplementation. Meanwhile, we developed two strategies to construct supplementary training sets to enhance the LLM's understanding of the corpus and prevent catastrophic forgetting. We conducted extensive experiments to validate the effectiveness of this CL method. In the best case, our method resulted in a 17.00\% improvement in the accuracy of the LLM.
Small Language Model Can Self-correct
Jan 14, 2024



Generative Language Models (LMs) such as ChatGPT have exhibited remarkable performance across various downstream tasks. Nevertheless, one of their most prominent drawbacks is generating inaccurate or false information with a confident tone. Previous studies have devised sophisticated pipelines and prompts to induce large LMs to exhibit the capability for self-correction. However, large LMs are explicitly prompted to verify and modify its answers separately rather than completing all steps spontaneously like humans. Moreover, these complex prompts are extremely challenging for small LMs to follow. In this paper, we introduce the \underline{I}ntrinsic \underline{S}elf-\underline{C}orrection (ISC) in generative language models, aiming to correct the initial output of LMs in a self-triggered manner, even for those small LMs with 6 billion parameters. Specifically, we devise a pipeline for constructing self-correction data and propose Partial Answer Masking (PAM), aiming to endow the model with the capability for intrinsic self-correction through fine-tuning. We conduct experiments using LMs with parameters sizes ranging from 6 billion to 13 billion in two tasks, including commonsense reasoning and factual knowledge reasoning. Our experiments demonstrate that the outputs generated using ISC outperform those generated without self-correction. We believe that the output quality of even small LMs can be further improved by empowering them with the ability to intrinsic self-correct.