 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Wolf in Sheep's Clothing: Targeted Routing Hijacking in Federated RAG
May 27, 2026Federated Retrieval-Augmented Generation (FedRAG) is attractive for privacy-sensitive applications because raw data remain local. As a result, routing must rely on client-provided semantic profiles, creating a new opportunity for manipulation. We introduce Routing Hijacking, a routing-stage attack in which a malicious client forges its profile to attract target queries despite having irrelevant underlying data. We show that this vulnerability is severe. Across three representative FedRAG routing architectures, Routing Hijacking consistently misroutes target queries and leads to downstream disruptions and failures, including missing evidence, poisoning, incorrect answers, and hallucinations. In a high-stakes MedQA-USMLE case study, we further show that poisoned retrieved evidence can mislead models across scales, leading to incorrect answers, hallucinations, and sycophantic failures. Existing defenses do not close this gap: encrypted routing preserves the exploited ranking, and Byzantine-robust Federated Learning (FL) rules transfer poorly to heterogeneous routing profiles. To address this gap, we propose a trust-aware post-routing framework that reweights clients using returned-evidence feedback, including retrieval relevance, profile consistency, and cross-client agreement; online experiments show that it suppresses persistent hijacking over recurring queries and transfers to a learned neural router. Our findings establish routing integrity as a new security challenge in FedRAG and highlight the need for stronger defenses for secure federated retrieval.
SOMP: Scalable Gradient Inversion for Large Language Models via Subspace-Guided Orthogonal Matching Pursuit
Mar 17, 2026Gradient inversion attacks reveal that private training text can be reconstructed from shared gradients, posing a privacy risk to large language models (LLMs). While prior methods perform well in small-batch settings, scaling to larger batch sizes and longer sequences remains challenging due to severe signal mixing, high computational cost, and degraded fidelity. We present SOMP (Subspace-Guided Orthogonal Matching Pursuit), a scalable gradient inversion framework that casts text recovery from aggregated gradients as a sparse signal recovery problem. Our key insight is that aggregated transformer gradients retain exploitable head-wise geometric structure together with sample-level sparsity. SOMP leverages these properties to progressively narrow the search space and disentangle mixed signals without exhaustive search. Experiments across multiple LLM families, model scales, and five languages show that SOMP consistently outperforms prior methods in the aggregated-gradient regime.For long sequences at batch size B=16, SOMP achieves substantially higher reconstruction fidelity than strong baselines, while remaining computationally competitive. Even under extreme aggregation (up to B=128), SOMP still recovers meaningful text, suggesting that privacy leakage can persist in regimes where prior attacks become much less effective.
Characterizing Memorization in Diffusion Language Models: Generalized Extraction and Sampling Effects
Mar 02, 2026Autoregressive language models (ARMs) have been shown to memorize and occasionally reproduce training data verbatim, raising concerns about privacy and copyright liability. Diffusion language models (DLMs) have recently emerged as a competitive alternative, yet their memorization behavior remains largely unexplored due to fundamental differences in generation dynamics. To address this gap, we present a systematic theoretical and empirical characterization of memorization in DLMs. We propose a generalized probabilistic extraction framework that unifies prefix-conditioned decoding and diffusion-based generation under arbitrary masking patterns and stochastic sampling trajectories. Theorem 4.3 establishes a monotonic relationship between sampling resolution and memorization: increasing resolution strictly increases the probability of exact training data extraction, implying that autoregressive decoding corresponds to a limiting case of diffusion-based generation by setting the sampling resolution maximal. Extensive experiments across model scales and sampling strategies validate our theoretical predictions. Under aligned prefix-conditioned evaluations, we further demonstrate that DLMs exhibit substantially lower memorization-based leakage of personally identifiable information (PII) compared to ARMs.
APEX: Probing Neural Networks via Activation Perturbation
Feb 03, 2026Prior work on probing neural networks primarily relies on input-space analysis or parameter perturbation, both of which face fundamental limitations in accessing structural information encoded in intermediate representations. We introduce Activation Perturbation for EXploration (APEX), an inference-time probing paradigm that perturbs hidden activations while keeping both inputs and model parameters fixed. We theoretically show that activation perturbation induces a principled transition from sample-dependent to model-dependent behavior by suppressing input-specific signals and amplifying representation-level structure, and further establish that input perturbation corresponds to a constrained special case of this framework. Through representative case studies, we demonstrate the practical advantages of APEX. In the small-noise regime, APEX provides a lightweight and efficient measure of sample regularity that aligns with established metrics, while also distinguishing structured from randomly labeled models and revealing semantically coherent prediction transitions. In the large-noise regime, APEX exposes training-induced model-level biases, including a pronounced concentration of predictions on the target class in backdoored models. Overall, our results show that APEX offers an effective perspective for exploring, and understanding neural networks beyond what is accessible from input space alone.
Semantic Leakage from Image Embeddings
Jan 30, 2026Image embeddings are generally assumed to pose limited privacy risk. We challenge this assumption by formalizing semantic leakage as the ability to recover semantic structures from compressed image embeddings. Surprisingly, we show that semantic leakage does not require exact reconstruction of the original image. Preserving local semantic neighborhoods under embedding alignment is sufficient to expose the intrinsic vulnerability of image embeddings. Crucially, this preserved neighborhood structure allows semantic information to propagate through a sequence of lossy mappings. Based on this conjecture, we propose Semantic Leakage from Image Embeddings (SLImE), a lightweight inference framework that reveals semantic information from standalone compressed image embeddings, incorporating a locally trained semantic retriever with off-the-shelf models, without training task-specific decoders. We thoroughly validate each step of the framework empirically, from aligned embeddings to retrieved tags, symbolic representations, and grammatical and coherent descriptions. We evaluate SLImE across a range of open and closed embedding models, including GEMINI, COHERE, NOMIC, and CLIP, and demonstrate consistent recovery of semantic information across diverse inference tasks. Our results reveal a fundamental vulnerability in image embeddings, whereby the preservation of semantic neighborhoods under alignment enables semantic leakage, highlighting challenges for privacy preservation.1
When Is Distributed Nonlinear Aggregation Private? Optimality and Information-Theoretical Bounds
Jan 19, 2026Nonlinear aggregation is central to modern distributed systems, yet its privacy behavior is far less understood than that of linear aggregation. Unlike linear aggregation where mature mechanisms can often suppress information leakage, nonlinear operators impose inherent structural limits on what privacy guarantees are theoretically achievable when the aggregate must be computed exactly. This paper develops a unified information-theoretic framework to characterize privacy leakage in distributed nonlinear aggregation under a joint adversary that combines passive (honest-but-curious) corruption and eavesdropping over communication channels. We cover two broad classes of nonlinear aggregates: order-based operators (maximum/minimum and top-$K$) and robust aggregation (median/quantiles and trimmed mean). We first derive fundamental lower bounds on leakage that hold without sacrificing accuracy, thereby identifying the minimum unavoidable information revealed by the computation and the transcript. We then propose simple yet effective privacy-preserving distributed algorithms, and show that with appropriate randomized initialization and parameter choices, our proposed approaches can attach the derived optimal bounds for the considered operators. Extensive experiments validate the tightness of the bounds and demonstrate that network topology and key algorithmic parameters (including the stepsize) govern the observed leakage in line with the theoretical analysis, yielding actionable guidelines for privacy-preserving nonlinear aggregation.
Do LLMs Really Memorize Personally Identifiable Information? Revisiting PII Leakage with a Cue-Controlled Memorization Framework
Jan 07, 2026Large Language Models (LLMs) have been reported to "leak" Personally Identifiable Information (PII), with successful PII reconstruction often interpreted as evidence of memorization. We propose a principled revision of memorization evaluation for LLMs, arguing that PII leakage should be evaluated under low lexical cue conditions, where target PII cannot be reconstructed through prompt-induced generalization or pattern completion. We formalize Cue-Resistant Memorization (CRM) as a cue-controlled evaluation framework and a necessary condition for valid memorization evaluation, explicitly conditioning on prompt-target overlap cues. Using CRM, we conduct a large-scale multilingual re-evaluation of PII leakage across 32 languages and multiple memorization paradigms. Revisiting reconstruction-based settings, including verbatim prefix-suffix completion and associative reconstruction, we find that their apparent effectiveness is driven primarily by direct surface-form cues rather than by true memorization. When such cues are controlled for, reconstruction success diminishes substantially. We further examine cue-free generation and membership inference, both of which exhibit extremely low true positive rates. Overall, our results suggest that previously reported PII leakage is better explained by cue-driven behavior than by genuine memorization, highlighting the importance of cue-controlled evaluation for reliably quantifying privacy-relevant memorization in LLMs.
Breaking Privacy in Federated Clustering: Perfect Input Reconstruction via Temporal Correlations
Nov 10, 2025

Federated clustering allows multiple parties to discover patterns in distributed data without sharing raw samples. To reduce overhead, many protocols disclose intermediate centroids during training. While often treated as harmless for efficiency, whether such disclosure compromises privacy remains an open question. Prior analyses modeled the problem as a so-called Hidden Subset Sum Problem (HSSP) and argued that centroid release may be safe, since classical HSSP attacks fail to recover inputs. We revisit this question and uncover a new leakage mechanism: temporal regularities in $k$-means iterations create exploitable structure that enables perfect input reconstruction. Building on this insight, we propose Trajectory-Aware Reconstruction (TAR), an attack that combines temporal assignment information with algebraic analysis to recover exact original inputs. Our findings provide the first rigorous evidence, supported by a practical attack, that centroid disclosure in federated clustering significantly compromises privacy, exposing a fundamental tension between privacy and efficiency.
LAGO: Few-shot Crosslingual Embedding Inversion Attacks via Language Similarity-Aware Graph Optimization
May 21, 2025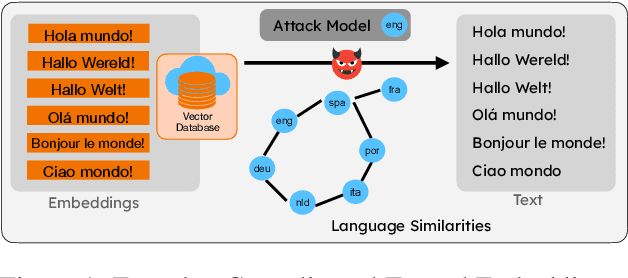
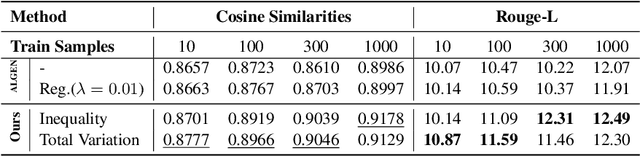
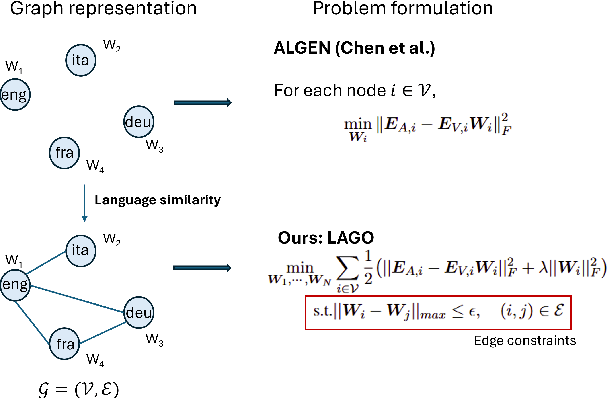
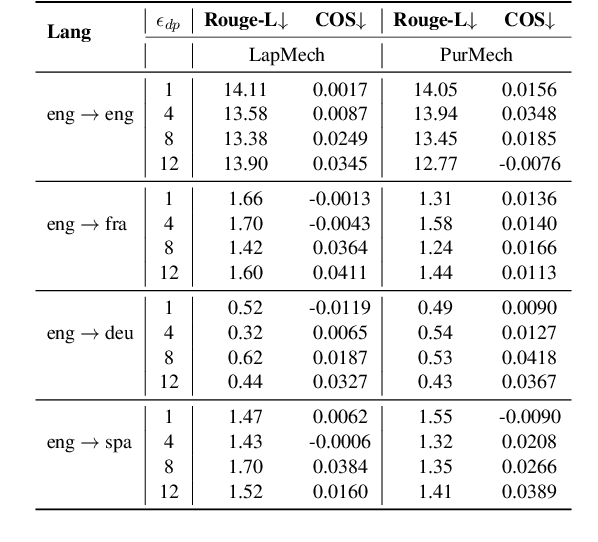
We propose LAGO - Language Similarity-Aware Graph Optimization - a novel approach for few-shot cross-lingual embedding inversion attacks, addressing critical privacy vulnerabilities in multilingual NLP systems. Unlike prior work in embedding inversion attacks that treat languages independently, LAGO explicitly models linguistic relationships through a graph-based constrained distributed optimization framework. By integrating syntactic and lexical similarity as edge constraints, our method enables collaborative parameter learning across related languages. Theoretically, we show this formulation generalizes prior approaches, such as ALGEN, which emerges as a special case when similarity constraints are relaxed. Our framework uniquely combines Frobenius-norm regularization with linear inequality or total variation constraints, ensuring robust alignment of cross-lingual embedding spaces even with extremely limited data (as few as 10 samples per language). Extensive experiments across multiple languages and embedding models demonstrate that LAGO substantially improves the transferability of attacks with 10-20% increase in Rouge-L score over baselines. This work establishes language similarity as a critical factor in inversion attack transferability, urging renewed focus on language-aware privacy-preserving multilingual embeddings.
Shared Path: Unraveling Memorization in Multilingual LLMs through Language Similarities
May 21, 2025We present the first comprehensive study of Memorization in Multilingual Large Language Models (MLLMs), analyzing 95 languages using models across diverse model scales, architectures, and memorization definitions. As MLLMs are increasingly deployed, understanding their memorization behavior has become critical. Yet prior work has focused primarily on monolingual models, leaving multilingual memorization underexplored, despite the inherently long-tailed nature of training corpora. We find that the prevailing assumption, that memorization is highly correlated with training data availability, fails to fully explain memorization patterns in MLLMs. We hypothesize that treating languages in isolation - ignoring their similarities - obscures the true patterns of memorization. To address this, we propose a novel graph-based correlation metric that incorporates language similarity to analyze cross-lingual memorization. Our analysis reveals that among similar languages, those with fewer training tokens tend to exhibit higher memorization, a trend that only emerges when cross-lingual relationships are explicitly modeled. These findings underscore the importance of a language-aware perspective in evaluating and mitigating memorization vulnerabilities in MLLMs. This also constitutes empirical evidence that language similarity both explains Memorization in MLLMs and underpins Cross-lingual Transferability, with broad implications for multilingual NLP.