 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInFact: Informativeness Alignment for Improved LLM Factuality
May 26, 2025Factual completeness is a general term that captures how detailed and informative a factually correct text is. For instance, the factual sentence ``Barack Obama was born in the United States'' is factually correct, though less informative than the factual sentence ``Barack Obama was born in Honolulu, Hawaii, United States''. Despite the known fact that LLMs tend to hallucinate and generate factually incorrect text, they might also tend to choose to generate factual text that is indeed factually correct and yet less informative than other, more informative choices. In this work, we tackle this problem by proposing an informativeness alignment mechanism. This mechanism takes advantage of recent factual benchmarks to propose an informativeness alignment objective. This objective prioritizes answers that are both correct and informative. A key finding of our work is that when training a model to maximize this objective or optimize its preference, we can improve not just informativeness but also factuality.
MultiHal: Multilingual Dataset for Knowledge-Graph Grounded Evaluation of LLM Hallucinations
May 20, 2025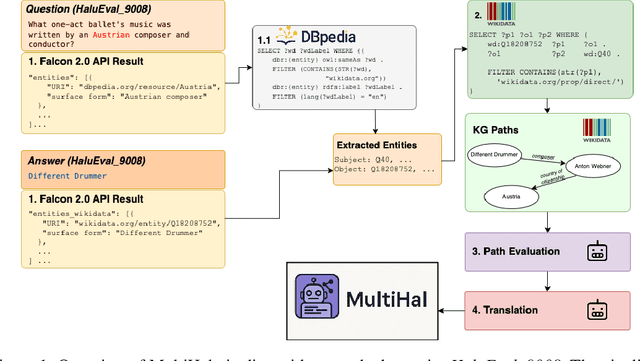
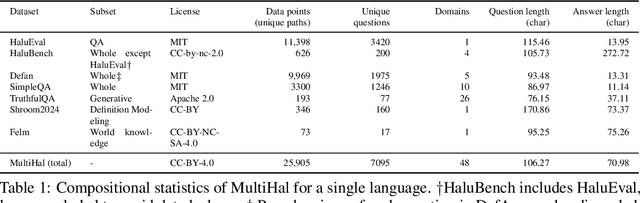

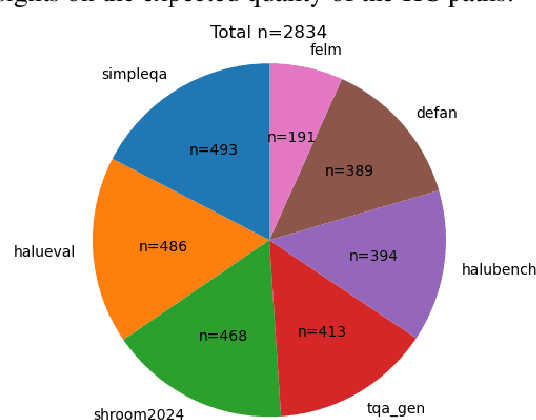
Large Language Models (LLMs) have inherent limitations of faithfulness and factuality, commonly referred to as hallucinations. Several benchmarks have been developed that provide a test bed for factuality evaluation within the context of English-centric datasets, while relying on supplementary informative context like web links or text passages but ignoring the available structured factual resources. To this end, Knowledge Graphs (KGs) have been identified as a useful aid for hallucination mitigation, as they provide a structured way to represent the facts about entities and their relations with minimal linguistic overhead. We bridge the lack of KG paths and multilinguality for factual language modeling within the existing hallucination evaluation benchmarks and propose a KG-based multilingual, multihop benchmark called \textbf{MultiHal} framed for generative text evaluation. As part of our data collection pipeline, we mined 140k KG-paths from open-domain KGs, from which we pruned noisy KG-paths, curating a high-quality subset of 25.9k. Our baseline evaluation shows an absolute scale increase by approximately 0.12 to 0.36 points for the semantic similarity score in KG-RAG over vanilla QA across multiple languages and multiple models, demonstrating the potential of KG integration. We anticipate MultiHal will foster future research towards several graph-based hallucination mitigation and fact-checking tasks.
Scaling Reasoning can Improve Factuality in Large Language Models
May 16, 2025Recent studies on large language model (LLM) reasoning capabilities have demonstrated promising improvements in model performance by leveraging a lengthy thinking process and additional computational resources during inference, primarily in tasks involving mathematical reasoning (Muennighoff et al., 2025). However, it remains uncertain if longer reasoning chains inherently enhance factual accuracy, particularly beyond mathematical contexts. In this work, we thoroughly examine LLM reasoning within complex open-domain question-answering (QA) scenarios. We initially distill reasoning traces from advanced, large-scale reasoning models (QwQ-32B and DeepSeek-R1-671B), then fine-tune a variety of models ranging from smaller, instruction-tuned variants to larger architectures based on Qwen2.5. To enrich reasoning traces, we introduce factual information from knowledge graphs in the form of paths into our reasoning traces. Our experimental setup includes four baseline approaches and six different instruction-tuned models evaluated across a benchmark of six datasets, encompassing over 22.6K questions. Overall, we carry out 168 experimental runs and analyze approximately 1.7 million reasoning traces. Our findings indicate that, within a single run, smaller reasoning models achieve noticeable improvements in factual accuracy compared to their original instruction-tuned counterparts. Moreover, our analysis demonstrates that adding test-time compute and token budgets factual accuracy consistently improves by 2-8%, further confirming the effectiveness of test-time scaling for enhancing performance and consequently improving reasoning accuracy in open-domain QA tasks. We release all the experimental artifacts for further research.
Knowledge Graphs, Large Language Models, and Hallucinations: An NLP Perspective
Nov 21, 2024
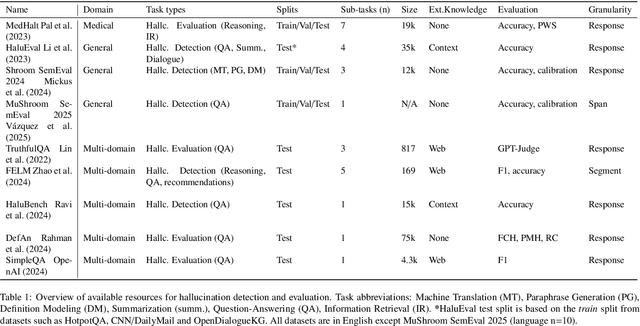
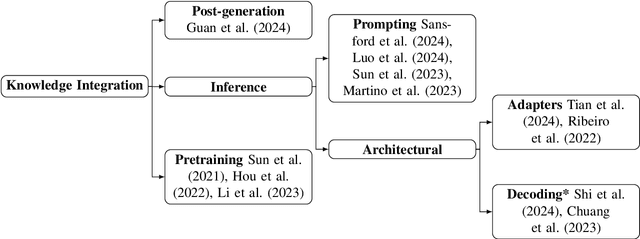
Large Language Models (LLMs) have revolutionized Natural Language Processing (NLP) based applications including automated text generation, question answering, chatbots, and others. However, they face a significant challenge: hallucinations, where models produce plausible-sounding but factually incorrect responses. This undermines trust and limits the applicability of LLMs in different domains. Knowledge Graphs (KGs), on the other hand, provide a structured collection of interconnected facts represented as entities (nodes) and their relationships (edges). In recent research, KGs have been leveraged to provide context that can fill gaps in an LLM understanding of certain topics offering a promising approach to mitigate hallucinations in LLMs, enhancing their reliability and accuracy while benefiting from their wide applicability. Nonetheless, it is still a very active area of research with various unresolved open problems. In this paper, we discuss these open challenges covering state-of-the-art datasets and benchmarks as well as methods for knowledge integration and evaluating hallucinations. In our discussion, we consider the current use of KGs in LLM systems and identify future directions within each of these challenges.
Large Language Models are Easily Confused: A Quantitative Metric, Security Implications and Typological Analysis
Oct 17, 2024
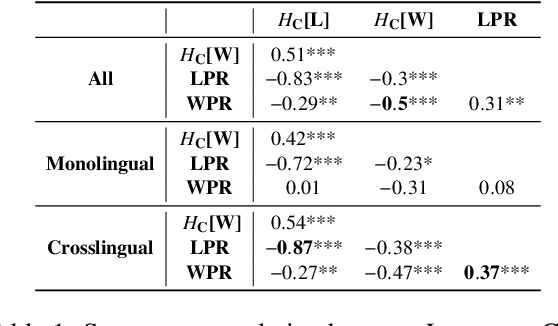

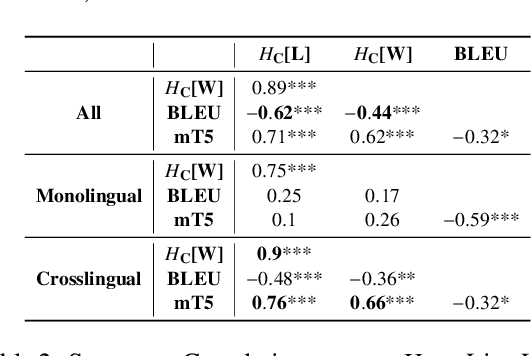
Language Confusion is a phenomenon where Large Language Models (LLMs) generate text that is neither in the desired language, nor in a contextually appropriate language. This phenomenon presents a critical challenge in text generation by LLMs, often appearing as erratic and unpredictable behavior. We hypothesize that there are linguistic regularities to this inherent vulnerability in LLMs and shed light on patterns of language confusion across LLMs. We introduce a novel metric, Language Confusion Entropy, designed to directly measure and quantify this confusion, based on language distributions informed by linguistic typology and lexical variation. Comprehensive comparisons with the Language Confusion Benchmark (Marchisio et al., 2024) confirm the effectiveness of our metric, revealing patterns of language confusion across LLMs. We further link language confusion to LLM security, and find patterns in the case of multilingual embedding inversion attacks. Our analysis demonstrates that linguistic typology offers theoretically grounded interpretation, and valuable insights into leveraging language similarities as a prior for LLM alignment and security.
Against All Odds: Overcoming Typology, Script, and Language Confusion in Multilingual Embedding Inversion Attacks
Aug 21, 2024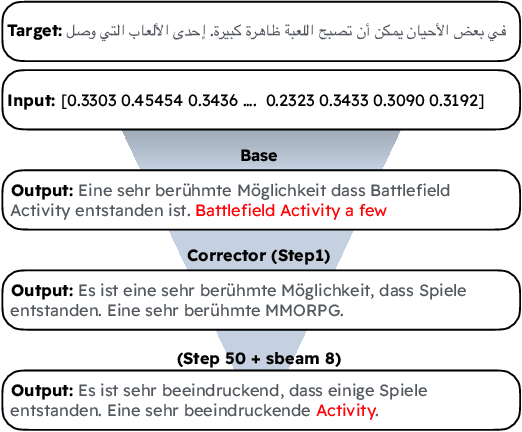
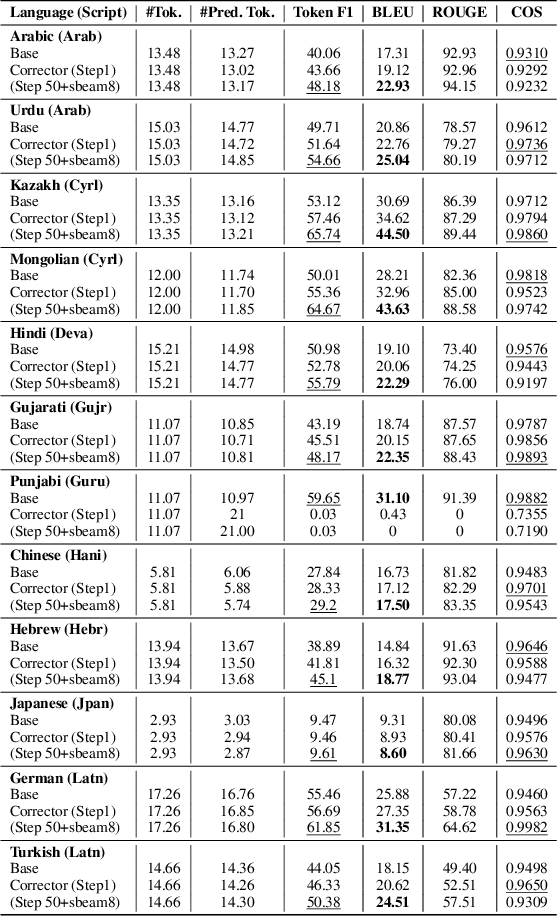

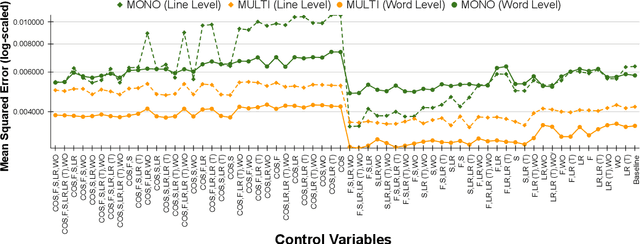
Large Language Models (LLMs) are susceptible to malicious influence by cyber attackers through intrusions such as adversarial, backdoor, and embedding inversion attacks. In response, the burgeoning field of LLM Security aims to study and defend against such threats. Thus far, the majority of works in this area have focused on monolingual English models, however, emerging research suggests that multilingual LLMs may be more vulnerable to various attacks than their monolingual counterparts. While previous work has investigated embedding inversion over a small subset of European languages, it is challenging to extrapolate these findings to languages from different linguistic families and with differing scripts. To this end, we explore the security of multilingual LLMs in the context of embedding inversion attacks and investigate cross-lingual and cross-script inversion across 20 languages, spanning over 8 language families and 12 scripts. Our findings indicate that languages written in Arabic script and Cyrillic script are particularly vulnerable to embedding inversion, as are languages within the Indo-Aryan language family. We further observe that inversion models tend to suffer from language confusion, sometimes greatly reducing the efficacy of an attack. Accordingly, we systematically explore this bottleneck for inversion models, uncovering predictable patterns which could be leveraged by attackers. Ultimately, this study aims to further the field's understanding of the outstanding security vulnerabilities facing multilingual LLMs and raise awareness for the languages most at risk of negative impact from these attacks.
Large Language Models and Knowledge Graphs: Opportunities and Challenges
Aug 11, 2023Large Language Models (LLMs) have taken Knowledge Representation -- and the world -- by storm. This inflection point marks a shift from explicit knowledge representation to a renewed focus on the hybrid representation of both explicit knowledge and parametric knowledge. In this position paper, we will discuss some of the common debate points within the community on LLMs (parametric knowledge) and Knowledge Graphs (explicit knowledge) and speculate on opportunities and visions that the renewed focus brings, as well as related research topics and challenges.
Entity Type Prediction Leveraging Graph Walks and Entity Descriptions
Jul 29, 2022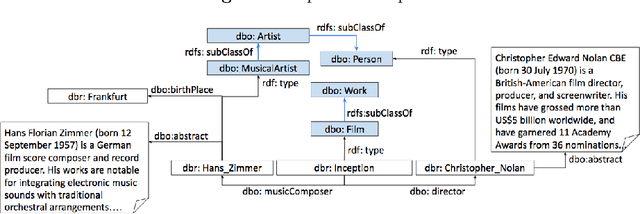
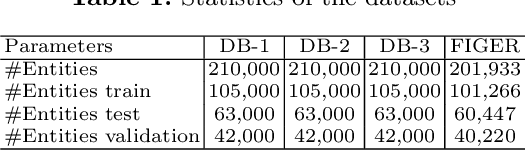
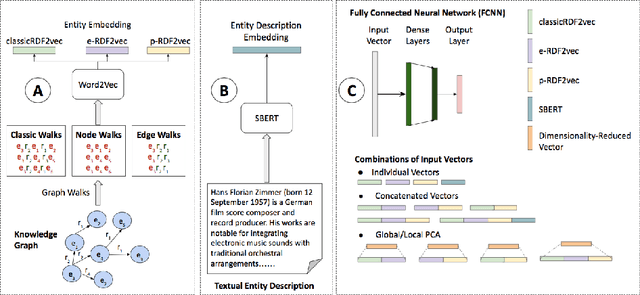
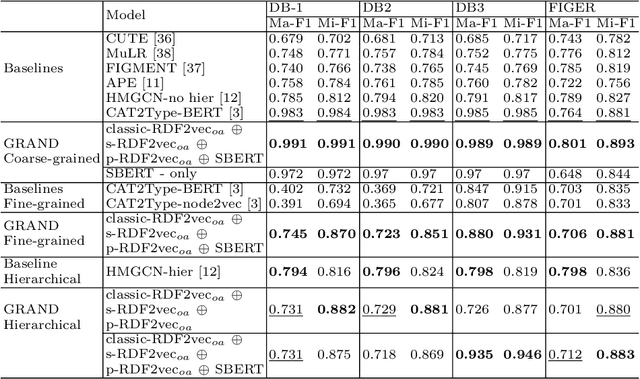
The entity type information in Knowledge Graphs (KGs) such as DBpedia, Freebase, etc. is often incomplete due to automated generation or human curation. Entity typing is the task of assigning or inferring the semantic type of an entity in a KG. This paper presents \textit{GRAND}, a novel approach for entity typing leveraging different graph walk strategies in RDF2vec together with textual entity descriptions. RDF2vec first generates graph walks and then uses a language model to obtain embeddings for each node in the graph. This study shows that the walk generation strategy and the embedding model have a significant effect on the performance of the entity typing task. The proposed approach outperforms the baseline approaches on the benchmark datasets DBpedia and FIGER for entity typing in KGs for both fine-grained and coarse-grained classes. The results show that the combination of order-aware RDF2vec variants together with the contextual embeddings of the textual entity descriptions achieve the best results.
Knowledge Graphs Evolution and Preservation -- A Technical Report from ISWS 2019
Dec 22, 2020

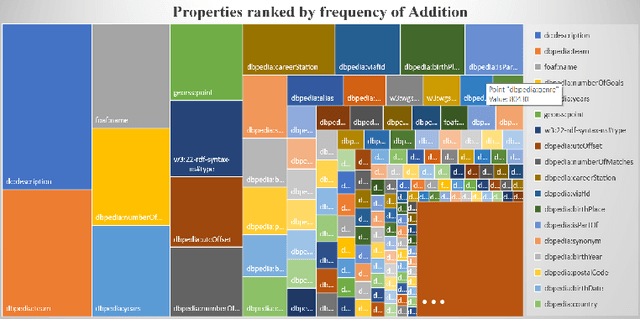
One of the grand challenges discussed during the Dagstuhl Seminar "Knowledge Graphs: New Directions for Knowledge Representation on the Semantic Web" and described in its report is that of a: "Public FAIR Knowledge Graph of Everything: We increasingly see the creation of knowledge graphs that capture information about the entirety of a class of entities. [...] This grand challenge extends this further by asking if we can create a knowledge graph of "everything" ranging from common sense concepts to location based entities. This knowledge graph should be "open to the public" in a FAIR manner democratizing this mass amount of knowledge." Although linked open data (LOD) is one knowledge graph, it is the closest realisation (and probably the only one) to a public FAIR Knowledge Graph (KG) of everything. Surely, LOD provides a unique testbed for experimenting and evaluating research hypotheses on open and FAIR KG. One of the most neglected FAIR issues about KGs is their ongoing evolution and long term preservation. We want to investigate this problem, that is to understand what preserving and supporting the evolution of KGs means and how these problems can be addressed. Clearly, the problem can be approached from different perspectives and may require the development of different approaches, including new theories, ontologies, metrics, strategies, procedures, etc. This document reports a collaborative effort performed by 9 teams of students, each guided by a senior researcher as their mentor, attending the International Semantic Web Research School (ISWS 2019). Each team provides a different perspective to the problem of knowledge graph evolution substantiated by a set of research questions as the main subject of their investigation. In addition, they provide their working definition for KG preservation and evolution.
Entity Type Prediction in Knowledge Graphs using Embeddings
May 06, 2020
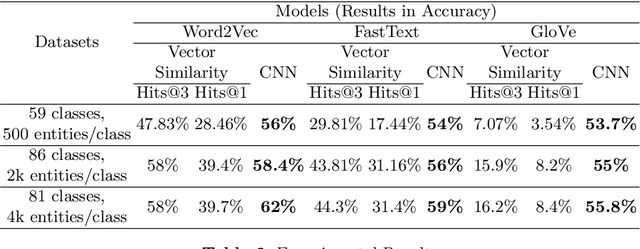
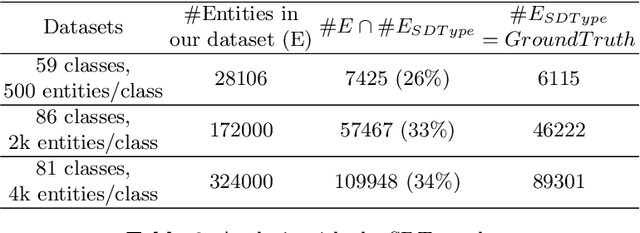
Open Knowledge Graphs (such as DBpedia, Wikidata, YAGO) have been recognized as the backbone of diverse applications in the field of data mining and information retrieval. Hence, the completeness and correctness of the Knowledge Graphs (KGs) are vital. Most of these KGs are mostly created either via an automated information extraction from Wikipedia snapshots or information accumulation provided by the users or using heuristics. However, it has been observed that the type information of these KGs is often noisy, incomplete, and incorrect. To deal with this problem a multi-label classification approach is proposed in this work for entity typing using KG embeddings. We compare our approach with the current state-of-the-art type prediction method and report on experiments with the KGs.