 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntity Type Prediction Leveraging Graph Walks and Entity Descriptions
Jul 29, 2022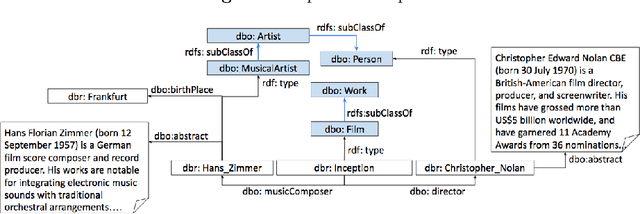
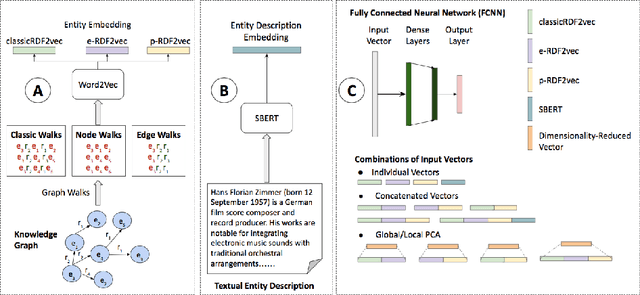
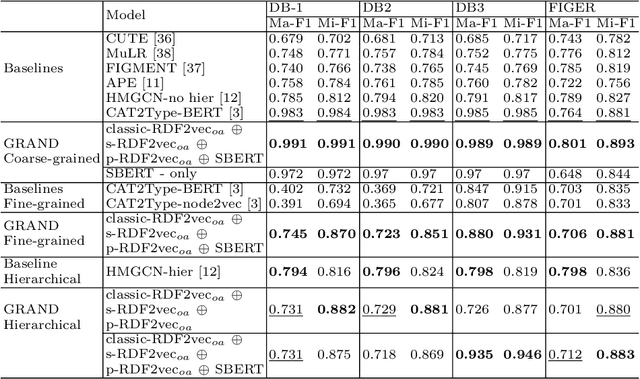
The entity type information in Knowledge Graphs (KGs) such as DBpedia, Freebase, etc. is often incomplete due to automated generation or human curation. Entity typing is the task of assigning or inferring the semantic type of an entity in a KG. This paper presents \textit{GRAND}, a novel approach for entity typing leveraging different graph walk strategies in RDF2vec together with textual entity descriptions. RDF2vec first generates graph walks and then uses a language model to obtain embeddings for each node in the graph. This study shows that the walk generation strategy and the embedding model have a significant effect on the performance of the entity typing task. The proposed approach outperforms the baseline approaches on the benchmark datasets DBpedia and FIGER for entity typing in KGs for both fine-grained and coarse-grained classes. The results show that the combination of order-aware RDF2vec variants together with the contextual embeddings of the textual entity descriptions achieve the best results.
The DLCC Node Classification Benchmark for Analyzing Knowledge Graph Embeddings
Jul 13, 2022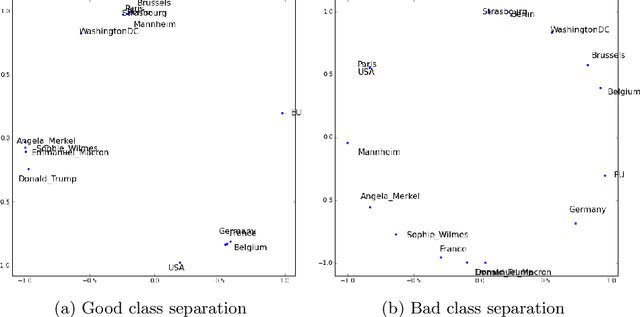
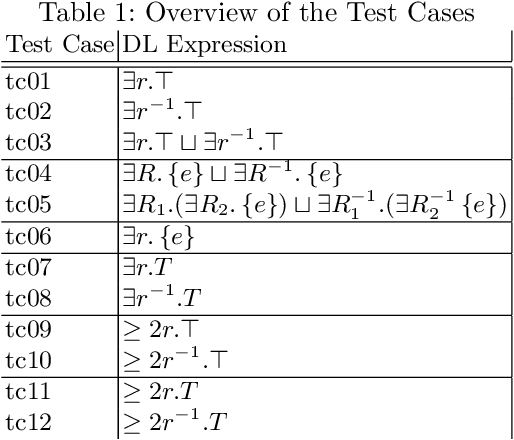
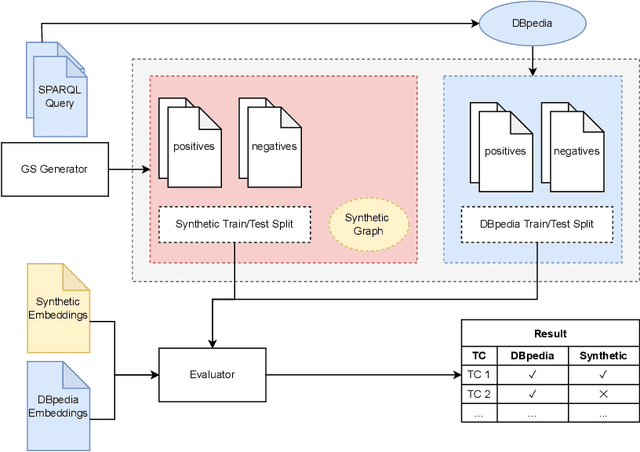

Knowledge graph embedding is a representation learning technique that projects entities and relations in a knowledge graph to continuous vector spaces. Embeddings have gained a lot of uptake and have been heavily used in link prediction and other downstream prediction tasks. Most approaches are evaluated on a single task or a single group of tasks to determine their overall performance. The evaluation is then assessed in terms of how well the embedding approach performs on the task at hand. Still, it is hardly evaluated (and often not even deeply understood) what information the embedding approaches are actually learning to represent. To fill this gap, we present the DLCC (Description Logic Class Constructors) benchmark, a resource to analyze embedding approaches in terms of which kinds of classes they can represent. Two gold standards are presented, one based on the real-world knowledge graph DBpedia and one synthetic gold standard. In addition, an evaluation framework is provided that implements an experiment protocol so that researchers can directly use the gold standard. To demonstrate the use of DLCC, we compare multiple embedding approaches using the gold standards. We find that many DL constructors on DBpedia are actually learned by recognizing different correlated patterns than those defined in the gold standard and that specific DL constructors, such as cardinality constraints, are particularly hard to be learned for most embedding approaches.
KERMIT - A Transformer-Based Approach for Knowledge Graph Matching
Apr 29, 2022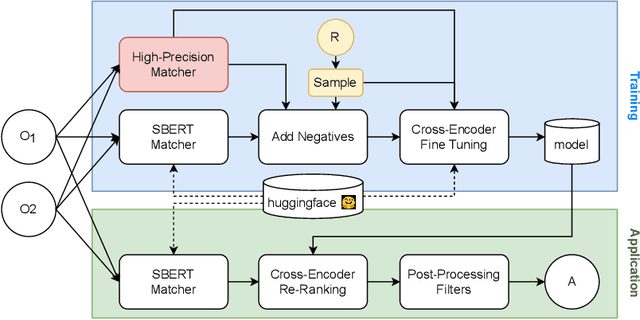
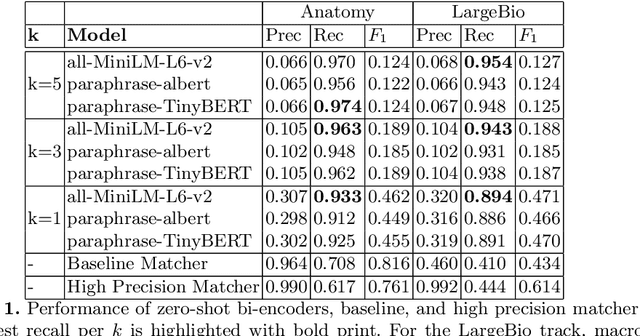

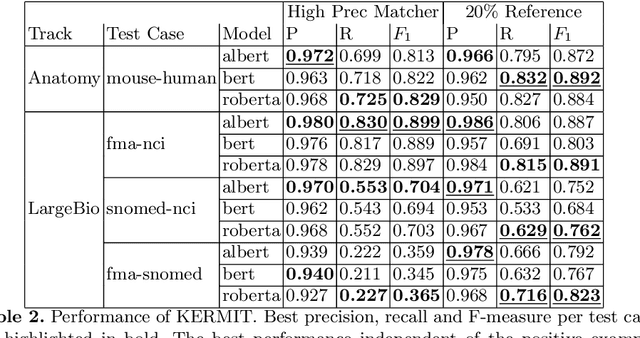
One of the strongest signals for automated matching of knowledge graphs and ontologies are textual concept descriptions. With the rise of transformer-based language models, text comparison based on meaning (rather than lexical features) is available to researchers. However, performing pairwise comparisons of all textual descriptions of concepts in two knowledge graphs is expensive and scales quadratically (or even worse if concepts have more than one description). To overcome this problem, we follow a two-step approach: we first generate matching candidates using a pre-trained sentence transformer (so called bi-encoder). In a second step, we use fine-tuned transformer cross-encoders to generate the best candidates. We evaluate our approach on multiple datasets and show that it is feasible and produces competitive results.
Ontology Matching Through Absolute Orientation of Embedding Spaces
Apr 08, 2022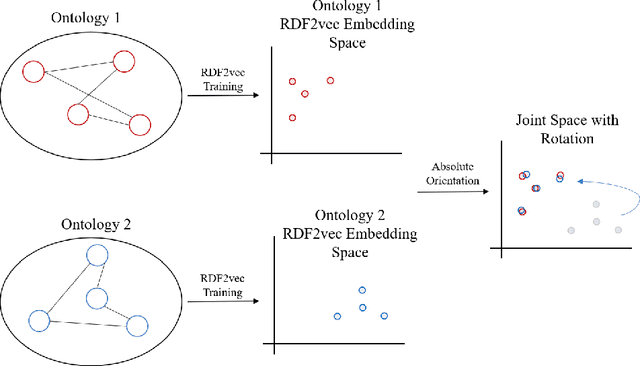
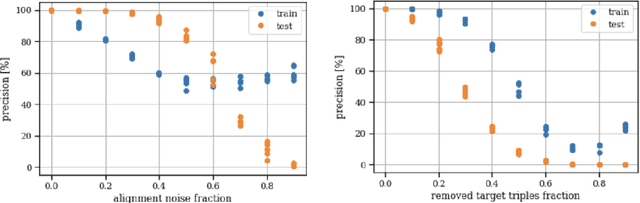
Ontology matching is a core task when creating interoperable and linked open datasets. In this paper, we explore a novel structure-based mapping approach which is based on knowledge graph embeddings: The ontologies to be matched are embedded, and an approach known as absolute orientation is used to align the two embedding spaces. Next to the approach, the paper presents a first, preliminary evaluation using synthetic and real-world datasets. We find in experiments with synthetic data, that the approach works very well on similarly structured graphs; it handles alignment noise better than size and structural differences in the ontologies.
Walk this Way! Entity Walks and Property Walks for RDF2vec
Apr 05, 2022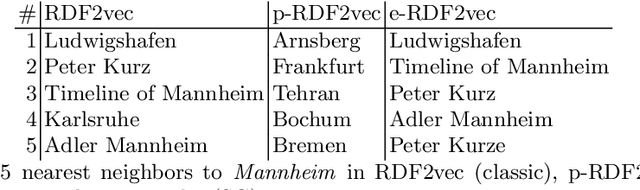

RDF2vec is a knowledge graph embedding mechanism which first extracts sequences from knowledge graphs by performing random walks, then feeds those into the word embedding algorithm word2vec for computing vector representations for entities. In this poster, we introduce two new flavors of walk extraction coined e-walks and p-walks, which put an emphasis on the structure or the neighborhood of an entity respectively, and thereby allow for creating embeddings which focus on similarity or relatedness. By combining the walk strategies with order-aware and classic RDF2vec, as well as CBOW and skip-gram word2vec embeddings, we conduct a preliminary evaluation with a total of 12 RDF2vec variants.
Matching with Transformers in MELT
Sep 15, 2021
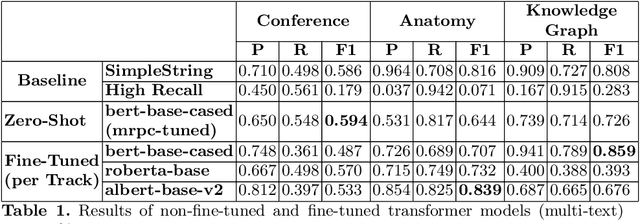
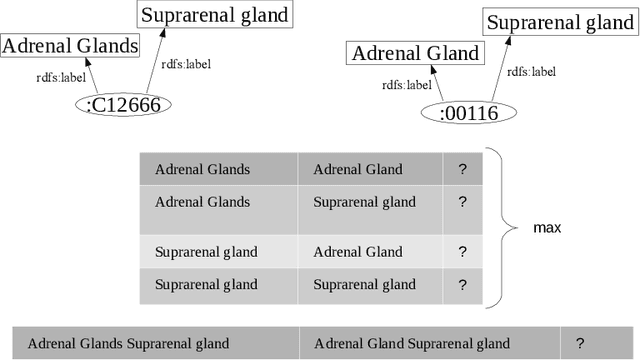
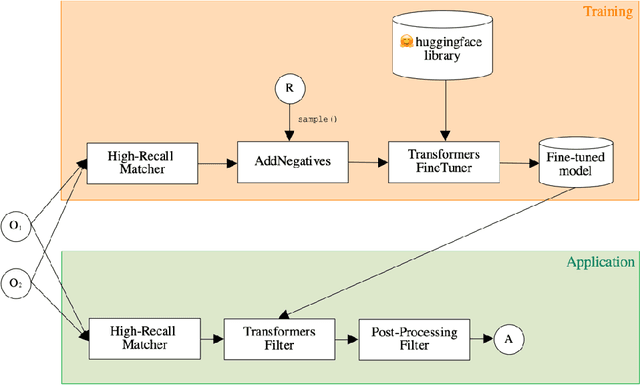
One of the strongest signals for automated matching of ontologies and knowledge graphs are the textual descriptions of the concepts. The methods that are typically applied (such as character- or token-based comparisons) are relatively simple, and therefore do not capture the actual meaning of the texts. With the rise of transformer-based language models, text comparison based on meaning (rather than lexical features) is possible. In this paper, we model the ontology matching task as classification problem and present approaches based on transformer models. We further provide an easy to use implementation in the MELT framework which is suited for ontology and knowledge graph matching. We show that a transformer-based filter helps to choose the correct correspondences given a high-recall alignment and already achieves a good result with simple alignment post-processing methods.
Putting RDF2vec in Order
Aug 11, 2021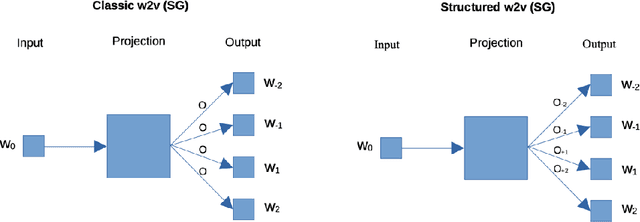
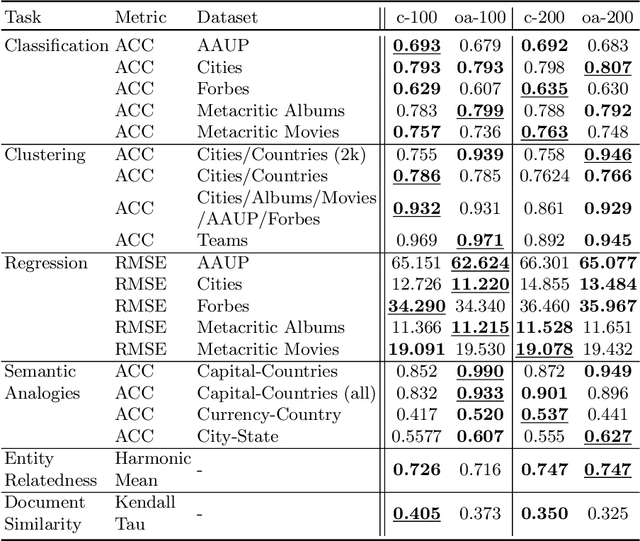

The RDF2vec method for creating node embeddings on knowledge graphs is based on word2vec, which, in turn, is agnostic towards the position of context words. In this paper, we argue that this might be a shortcoming when training RDF2vec, and show that using a word2vec variant which respects order yields considerable performance gains especially on tasks where entities of different classes are involved.
Background Knowledge in Schema Matching: Strategy vs. Data
Jun 29, 2021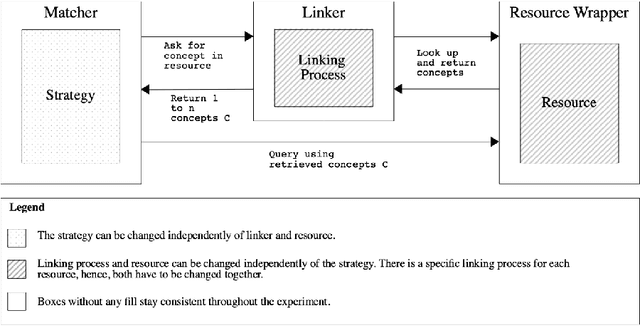
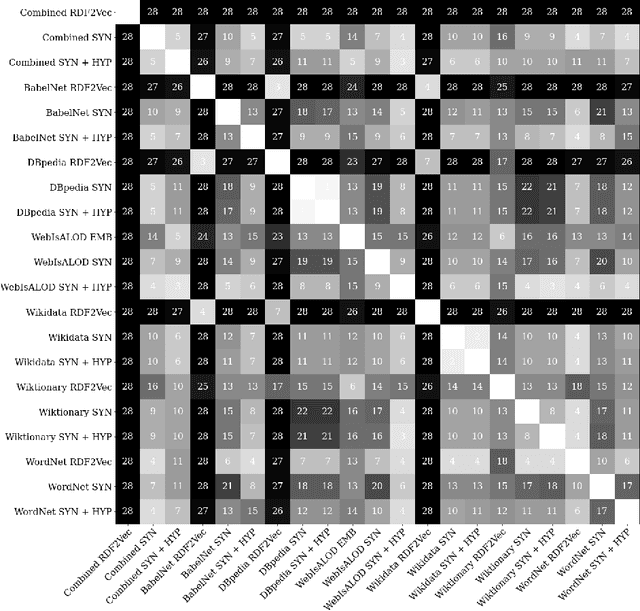
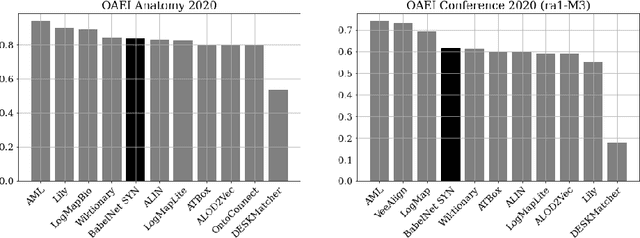
The use of external background knowledge can be beneficial for the task of matching schemas or ontologies automatically. In this paper, we exploit six general-purpose knowledge graphs as sources of background knowledge for the matching task. The background sources are evaluated by applying three different exploitation strategies. We find that explicit strategies still outperform latent ones and that the choice of the strategy has a greater impact on the final alignment than the actual background dataset on which the strategy is applied. While we could not identify a universally superior resource, BabelNet achieved consistently good results. Our best matcher configuration with BabelNet performs very competitively when compared to other matching systems even though no dataset-specific optimizations were made.
FinMatcher at FinSim-2: Hypernym Detection in the Financial Services Domain using Knowledge Graphs
Mar 02, 2021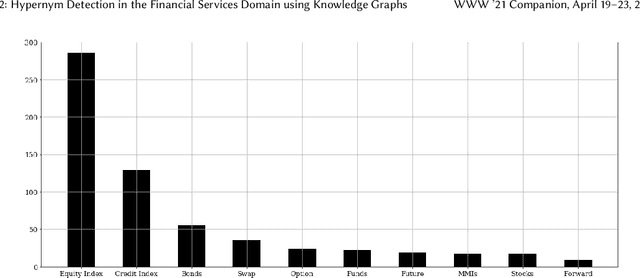
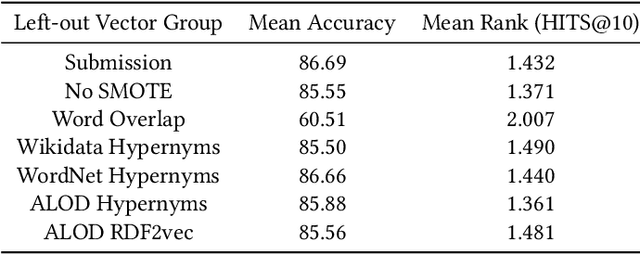
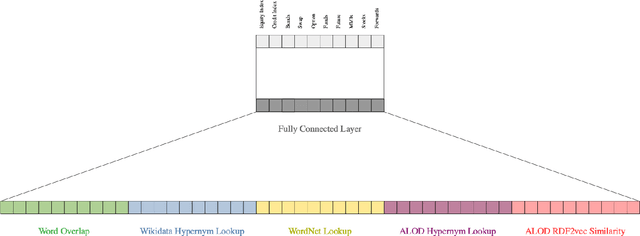
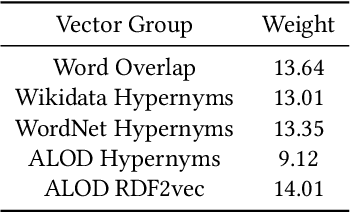
This paper presents the FinMatcher system and its results for the FinSim 2021 shared task which is co-located with the Workshop on Financial Technology on the Web (FinWeb) in conjunction with The Web Conference. The FinSim-2 shared task consists of a set of concept labels from the financial services domain. The goal is to find the most relevant top-level concept from a given set of concepts. The FinMatcher system exploits three publicly available knowledge graphs, namely WordNet, Wikidata, and WebIsALOD. The graphs are used to generate explicit features as well as latent features which are fed into a neural classifier to predict the closest hypernym.
Knowledge Graphs Evolution and Preservation -- A Technical Report from ISWS 2019
Dec 22, 2020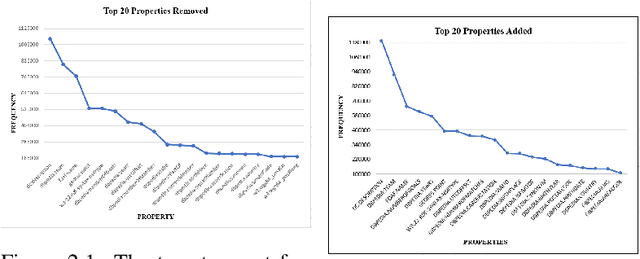
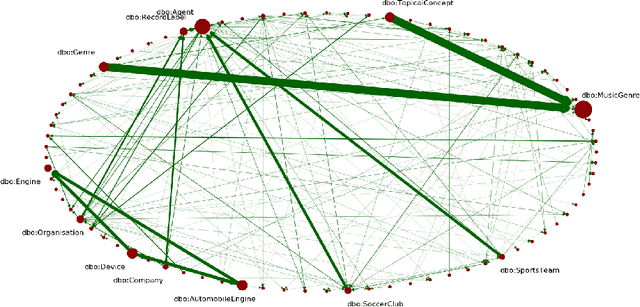

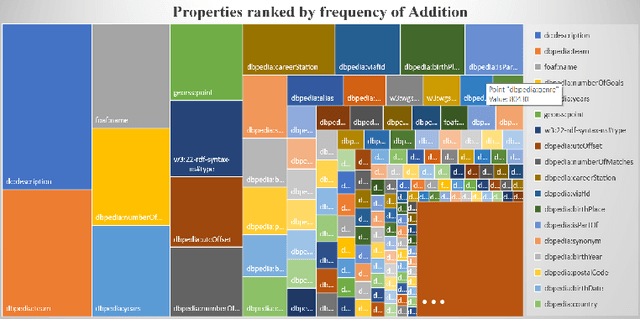
One of the grand challenges discussed during the Dagstuhl Seminar "Knowledge Graphs: New Directions for Knowledge Representation on the Semantic Web" and described in its report is that of a: "Public FAIR Knowledge Graph of Everything: We increasingly see the creation of knowledge graphs that capture information about the entirety of a class of entities. [...] This grand challenge extends this further by asking if we can create a knowledge graph of "everything" ranging from common sense concepts to location based entities. This knowledge graph should be "open to the public" in a FAIR manner democratizing this mass amount of knowledge." Although linked open data (LOD) is one knowledge graph, it is the closest realisation (and probably the only one) to a public FAIR Knowledge Graph (KG) of everything. Surely, LOD provides a unique testbed for experimenting and evaluating research hypotheses on open and FAIR KG. One of the most neglected FAIR issues about KGs is their ongoing evolution and long term preservation. We want to investigate this problem, that is to understand what preserving and supporting the evolution of KGs means and how these problems can be addressed. Clearly, the problem can be approached from different perspectives and may require the development of different approaches, including new theories, ontologies, metrics, strategies, procedures, etc. This document reports a collaborative effort performed by 9 teams of students, each guided by a senior researcher as their mentor, attending the International Semantic Web Research School (ISWS 2019). Each team provides a different perspective to the problem of knowledge graph evolution substantiated by a set of research questions as the main subject of their investigation. In addition, they provide their working definition for KG preservation and evolution.