 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKERMIT - A Transformer-Based Approach for Knowledge Graph Matching
Paper and Code
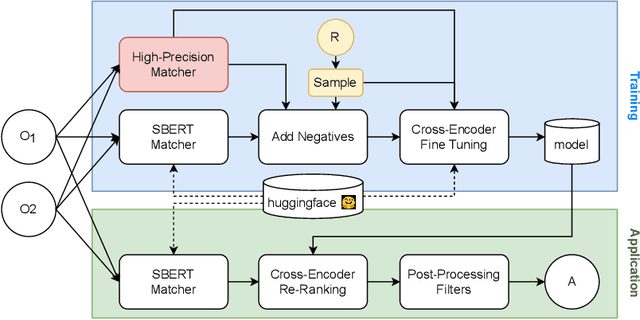
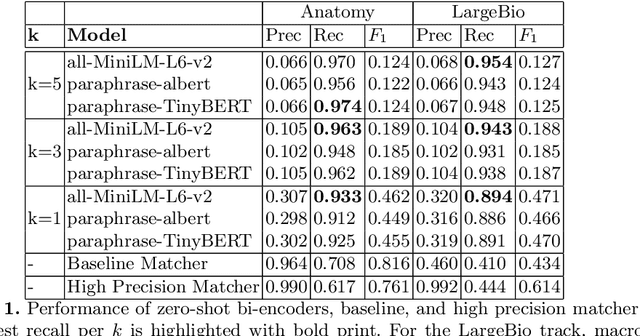

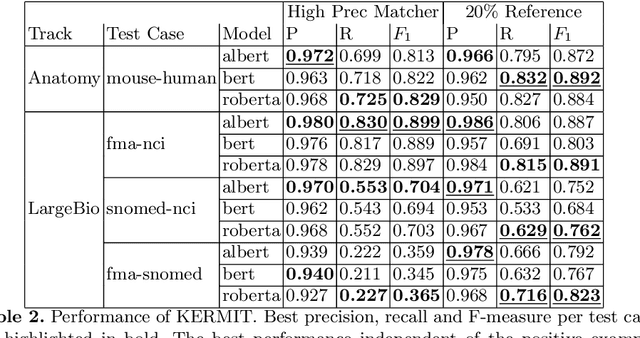
One of the strongest signals for automated matching of knowledge graphs and ontologies are textual concept descriptions. With the rise of transformer-based language models, text comparison based on meaning (rather than lexical features) is available to researchers. However, performing pairwise comparisons of all textual descriptions of concepts in two knowledge graphs is expensive and scales quadratically (or even worse if concepts have more than one description). To overcome this problem, we follow a two-step approach: we first generate matching candidates using a pre-trained sentence transformer (so called bi-encoder). In a second step, we use fine-tuned transformer cross-encoders to generate the best candidates. We evaluate our approach on multiple datasets and show that it is feasible and produces competitive results.