 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConExion: Concept Extraction with Large Language Models
Apr 22, 2025
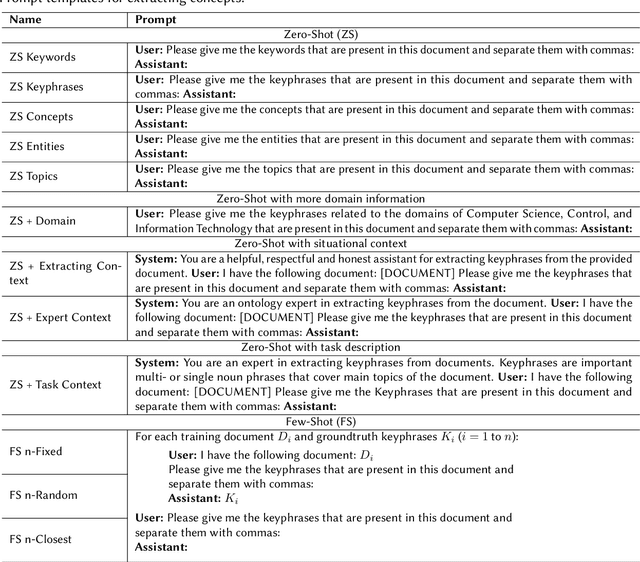
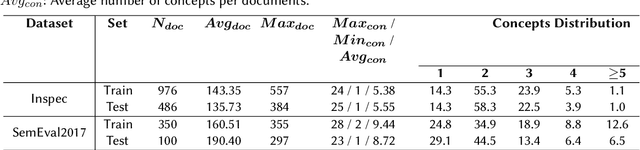
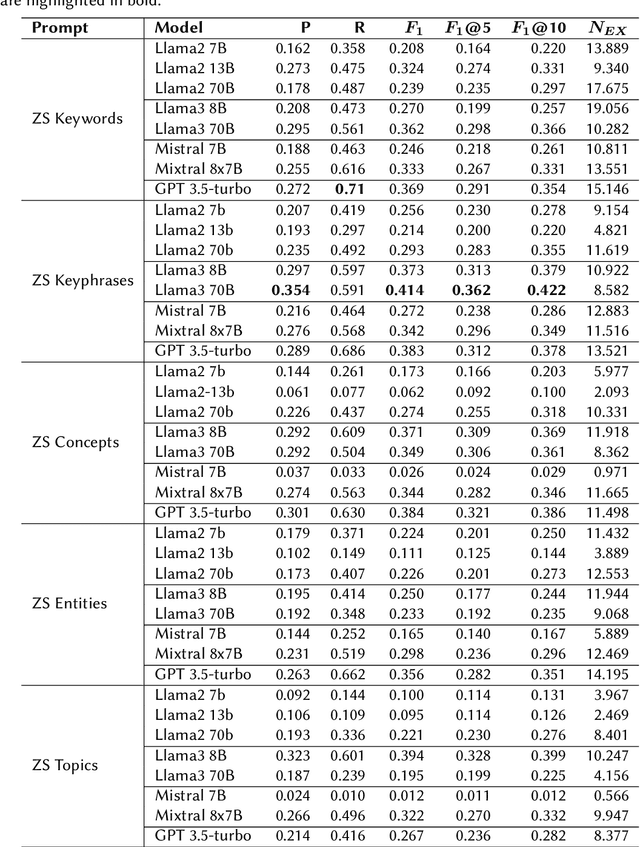
In this paper, an approach for concept extraction from documents using pre-trained large language models (LLMs) is presented. Compared with conventional methods that extract keyphrases summarizing the important information discussed in a document, our approach tackles a more challenging task of extracting all present concepts related to the specific domain, not just the important ones. Through comprehensive evaluations of two widely used benchmark datasets, we demonstrate that our method improves the F1 score compared to state-of-the-art techniques. Additionally, we explore the potential of using prompts within these models for unsupervised concept extraction. The extracted concepts are intended to support domain coverage evaluation of ontologies and facilitate ontology learning, highlighting the effectiveness of LLMs in concept extraction tasks. Our source code and datasets are publicly available at https://github.com/ISE-FIZKarlsruhe/concept_extraction.
OAEI Machine Learning Dataset for Online Model Generation
Apr 29, 2024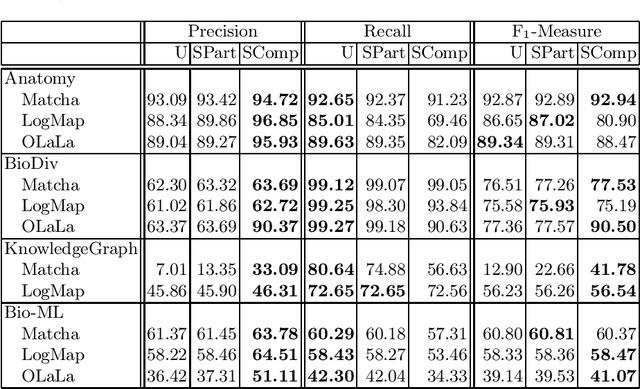
Ontology and knowledge graph matching systems are evaluated annually by the Ontology Alignment Evaluation Initiative (OAEI). More and more systems use machine learning-based approaches, including large language models. The training and validation datasets are usually determined by the system developer and often a subset of the reference alignments are used. This sampling is against the OAEI rules and makes a fair comparison impossible. Furthermore, those models are trained offline (a trained and optimized model is packaged into the matcher) and therefore the systems are specifically trained for those tasks. In this paper, we introduce a dataset that contains training, validation, and test sets for most of the OAEI tracks. Thus, online model learning (the systems must adapt to the given input alignment without human intervention) is made possible to enable a fair comparison for ML-based systems. We showcase the usefulness of the dataset by fine-tuning the confidence thresholds of popular systems.
OLaLa: Ontology Matching with Large Language Models
Nov 07, 2023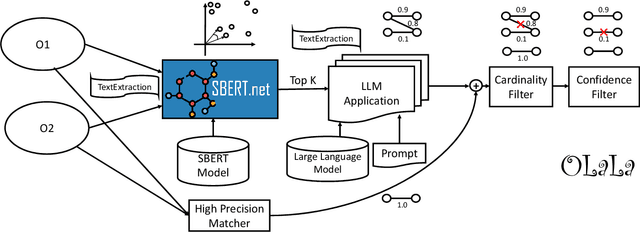
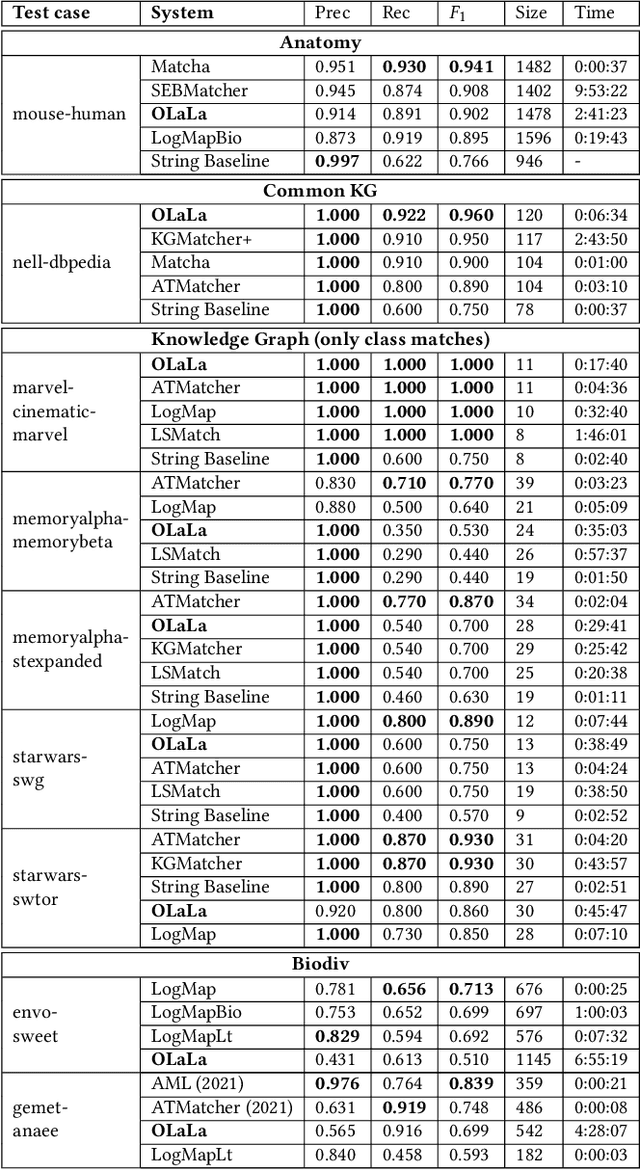
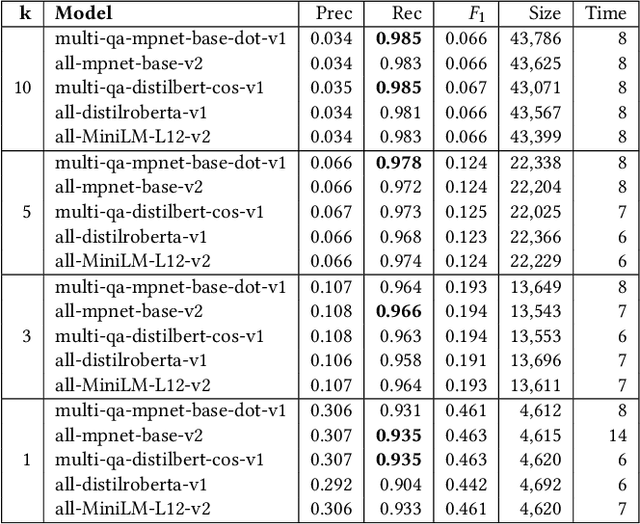
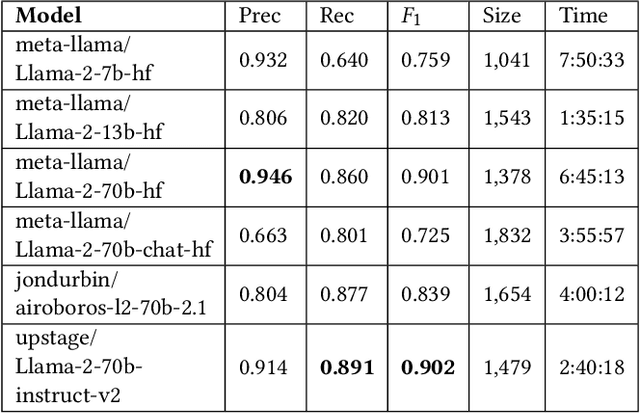
Ontology (and more generally: Knowledge Graph) Matching is a challenging task where information in natural language is one of the most important signals to process. With the rise of Large Language Models, it is possible to incorporate this knowledge in a better way into the matching pipeline. A number of decisions still need to be taken, e.g., how to generate a prompt that is useful to the model, how information in the KG can be formulated in prompts, which Large Language Model to choose, how to provide existing correspondences to the model, how to generate candidates, etc. In this paper, we present a prototype that explores these questions by applying zero-shot and few-shot prompting with multiple open Large Language Models to different tasks of the Ontology Alignment Evaluation Initiative (OAEI). We show that with only a handful of examples and a well-designed prompt, it is possible to achieve results that are en par with supervised matching systems which use a much larger portion of the ground truth.
KGrEaT: A Framework to Evaluate Knowledge Graphs via Downstream Tasks
Aug 21, 2023

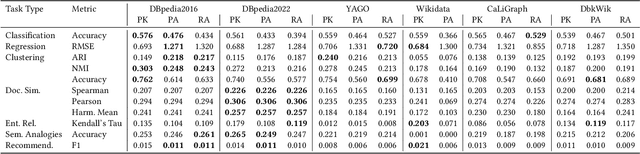
In recent years, countless research papers have addressed the topics of knowledge graph creation, extension, or completion in order to create knowledge graphs that are larger, more correct, or more diverse. This research is typically motivated by the argumentation that using such enhanced knowledge graphs to solve downstream tasks will improve performance. Nonetheless, this is hardly ever evaluated. Instead, the predominant evaluation metrics - aiming at correctness and completeness - are undoubtedly valuable but fail to capture the complete picture, i.e., how useful the created or enhanced knowledge graph actually is. Further, the accessibility of such a knowledge graph is rarely considered (e.g., whether it contains expressive labels, descriptions, and sufficient context information to link textual mentions to the entities of the knowledge graph). To better judge how well knowledge graphs perform on actual tasks, we present KGrEaT - a framework to estimate the quality of knowledge graphs via actual downstream tasks like classification, clustering, or recommendation. Instead of comparing different methods of processing knowledge graphs with respect to a single task, the purpose of KGrEaT is to compare various knowledge graphs as such by evaluating them on a fixed task setup. The framework takes a knowledge graph as input, automatically maps it to the datasets to be evaluated on, and computes performance metrics for the defined tasks. It is built in a modular way to be easily extendable with additional tasks and datasets.
DBkWik++ -- Multi Source Matching of Knowledge Graphs
Oct 06, 2022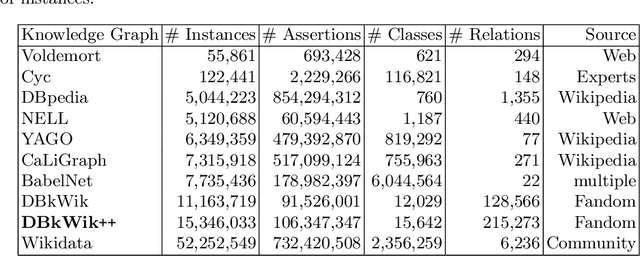
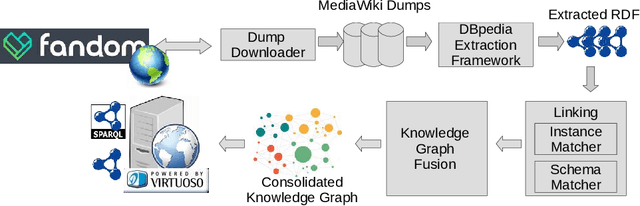
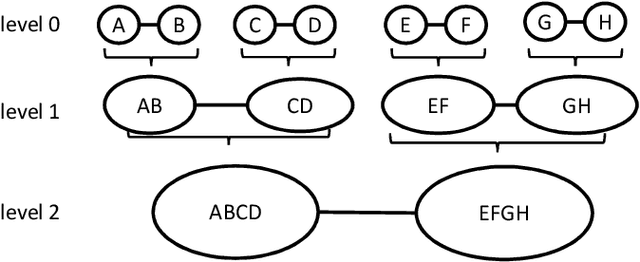
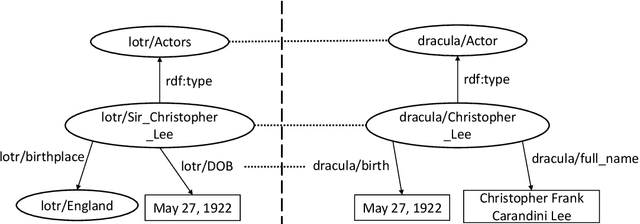
Large knowledge graphs like DBpedia and YAGO are always based on the same source, i.e., Wikipedia. But there are more wikis that contain information about long-tail entities such as wiki hosting platforms like Fandom. In this paper, we present the approach and analysis of DBkWik++, a fused Knowledge Graph from thousands of wikis. A modified version of the DBpedia framework is applied to each wiki which results in many isolated Knowledge Graphs. With an incremental merge based approach, we reuse one-to-one matching systems to solve the multi source KG matching task. Based on this alignment we create a consolidated knowledge graph with more than 15 million instances.
Gollum: A Gold Standard for Large Scale Multi Source Knowledge Graph Matching
Sep 16, 2022

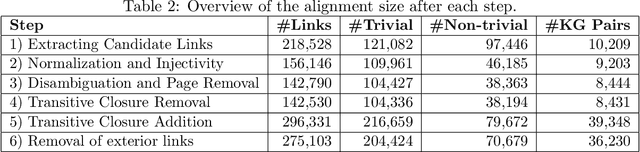
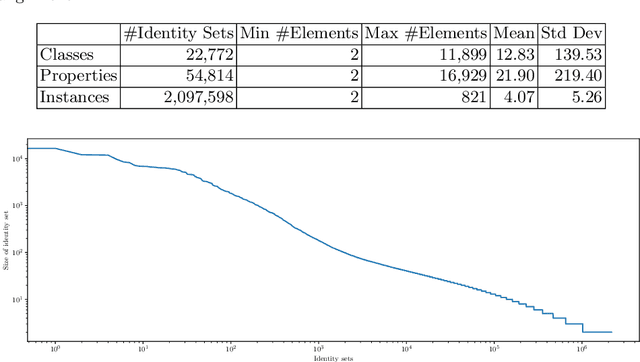
The number of Knowledge Graphs (KGs) generated with automatic and manual approaches is constantly growing. For an integrated view and usage, an alignment between these KGs is necessary on the schema as well as instance level. While there are approaches that try to tackle this multi source knowledge graph matching problem, large gold standards are missing to evaluate their effectiveness and scalability. We close this gap by presenting Gollum -- a gold standard for large-scale multi source knowledge graph matching with over 275,000 correspondences between 4,149 different KGs. They originate from knowledge graphs derived by applying the DBpedia extraction framework to a large wiki farm. Three variations of the gold standard are made available: (1) a version with all correspondences for evaluating unsupervised matching approaches, and two versions for evaluating supervised matching: (2) one where each KG is contained both in the train and test set, and (3) one where each KG is exclusively contained in the train or the test set.
KERMIT - A Transformer-Based Approach for Knowledge Graph Matching
Apr 29, 2022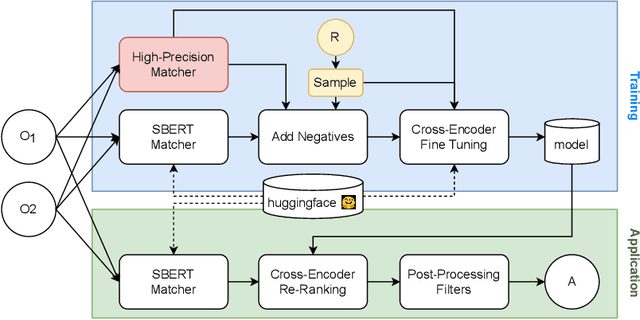
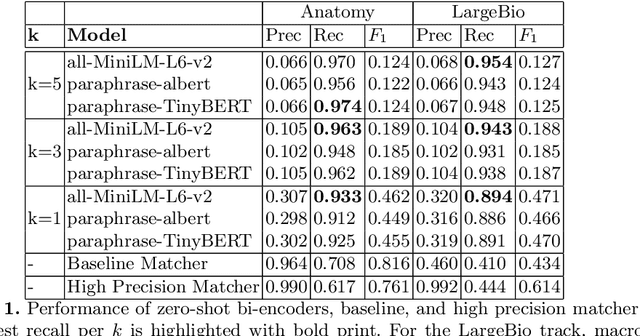

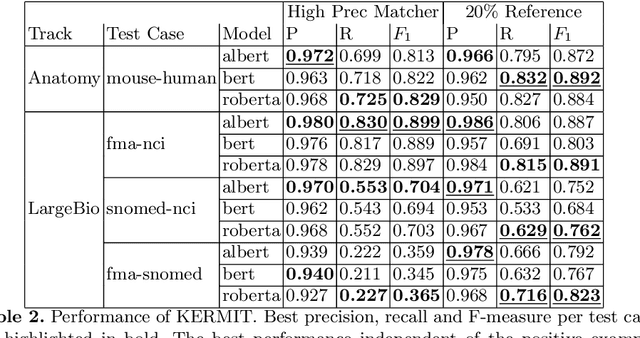
One of the strongest signals for automated matching of knowledge graphs and ontologies are textual concept descriptions. With the rise of transformer-based language models, text comparison based on meaning (rather than lexical features) is available to researchers. However, performing pairwise comparisons of all textual descriptions of concepts in two knowledge graphs is expensive and scales quadratically (or even worse if concepts have more than one description). To overcome this problem, we follow a two-step approach: we first generate matching candidates using a pre-trained sentence transformer (so called bi-encoder). In a second step, we use fine-tuned transformer cross-encoders to generate the best candidates. We evaluate our approach on multiple datasets and show that it is feasible and produces competitive results.
Order Matters: Matching Multiple Knowledge Graphs
Nov 03, 2021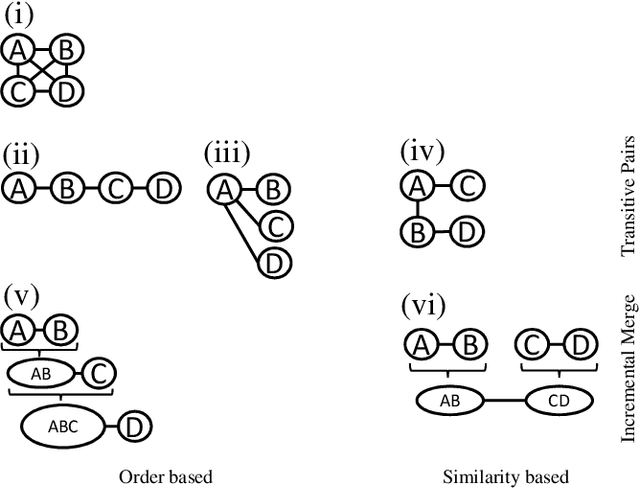
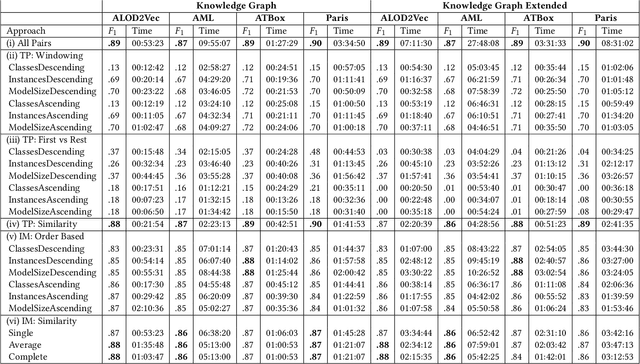
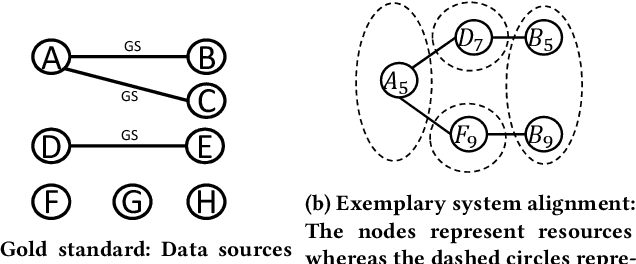
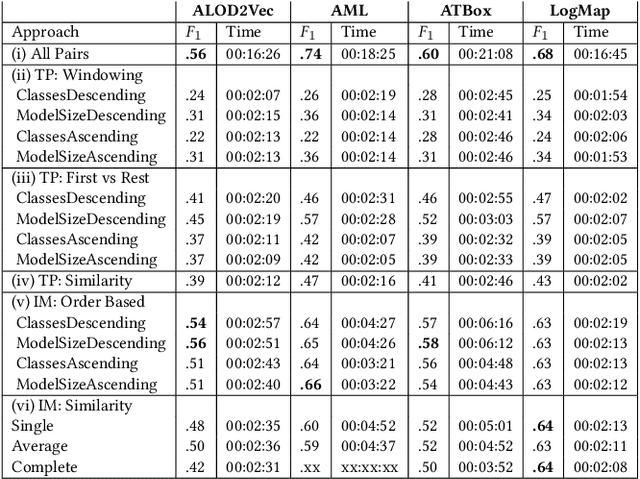
Knowledge graphs (KGs) provide information in machine interpretable form. In cases where multiple KGs are used in the same system, that information needs to be integrated. This is usually done by automated matching systems. Most of those systems consider only 1:1 (binary) matching tasks. Thus, matching a larger number of knowledge graphs with such systems would lead to quadratic efforts. In this paper, we empirically analyze different approaches to reduce the task of multi-source matching to a linear number of executions of binary matching systems. We show that the matching order of KGs and the multi-source strategy actually matter and that near-optimal results can be achieved with linear efforts.
Matching with Transformers in MELT
Sep 15, 2021
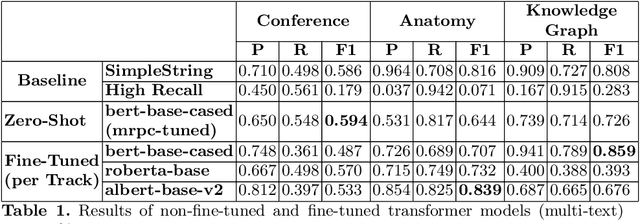
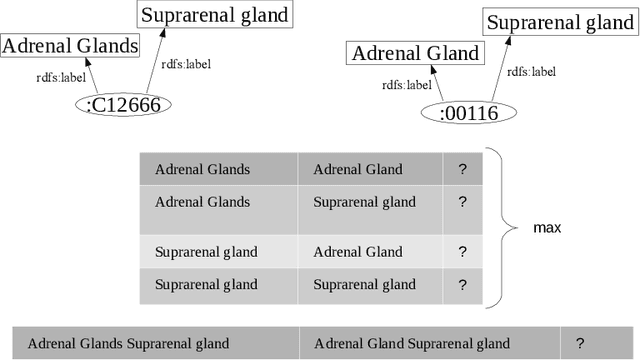
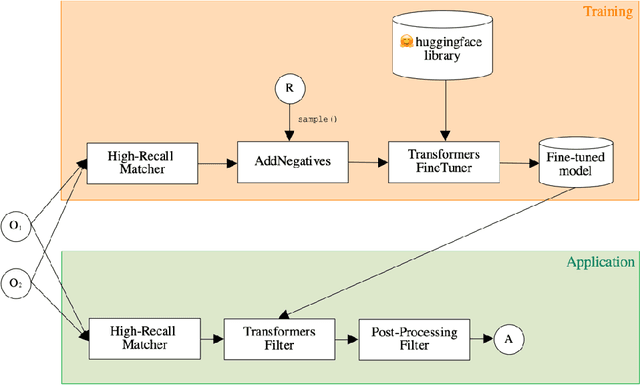
One of the strongest signals for automated matching of ontologies and knowledge graphs are the textual descriptions of the concepts. The methods that are typically applied (such as character- or token-based comparisons) are relatively simple, and therefore do not capture the actual meaning of the texts. With the rise of transformer-based language models, text comparison based on meaning (rather than lexical features) is possible. In this paper, we model the ontology matching task as classification problem and present approaches based on transformer models. We further provide an easy to use implementation in the MELT framework which is suited for ontology and knowledge graph matching. We show that a transformer-based filter helps to choose the correct correspondences given a high-recall alignment and already achieves a good result with simple alignment post-processing methods.
On-Demand and Lightweight Knowledge Graph Generation -- a Demonstration with DBpedia
Jul 02, 2021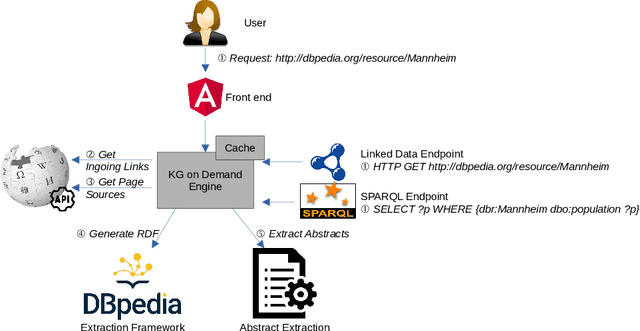

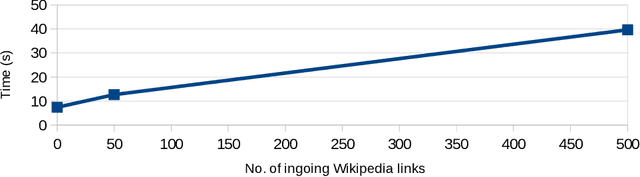
Modern large-scale knowledge graphs, such as DBpedia, are datasets which require large computational resources to serve and process. Moreover, they often have longer release cycles, which leads to outdated information in those graphs. In this paper, we present DBpedia on Demand -- a system which serves DBpedia resources on demand without the need to materialize and store the entire graph, and which even provides limited querying functionality.