 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConExion: Concept Extraction with Large Language Models
Apr 22, 2025
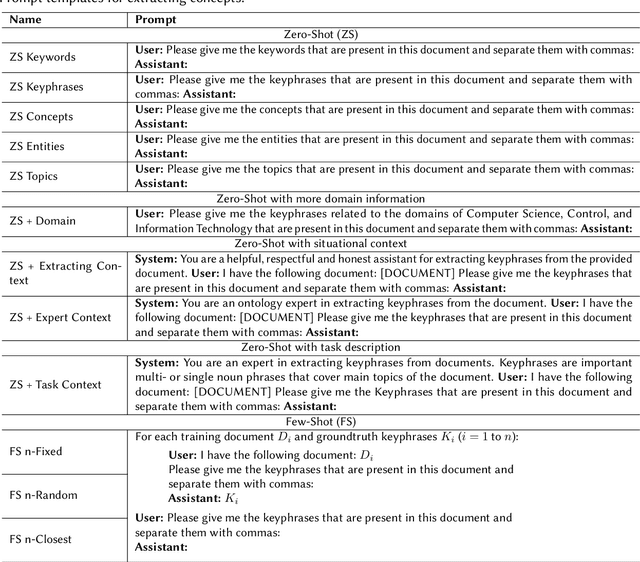
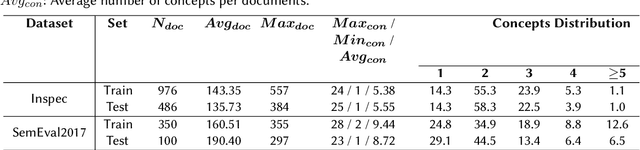
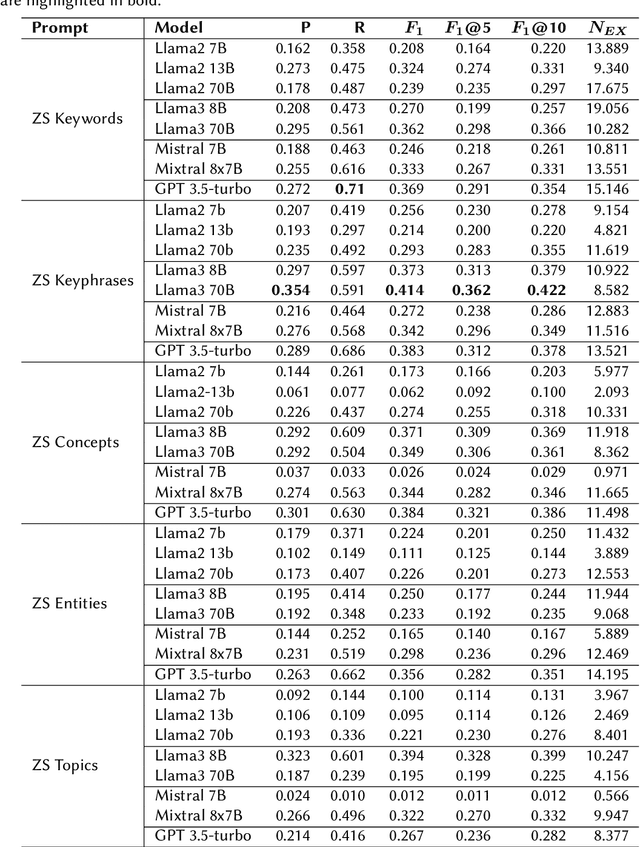
In this paper, an approach for concept extraction from documents using pre-trained large language models (LLMs) is presented. Compared with conventional methods that extract keyphrases summarizing the important information discussed in a document, our approach tackles a more challenging task of extracting all present concepts related to the specific domain, not just the important ones. Through comprehensive evaluations of two widely used benchmark datasets, we demonstrate that our method improves the F1 score compared to state-of-the-art techniques. Additionally, we explore the potential of using prompts within these models for unsupervised concept extraction. The extracted concepts are intended to support domain coverage evaluation of ontologies and facilitate ontology learning, highlighting the effectiveness of LLMs in concept extraction tasks. Our source code and datasets are publicly available at https://github.com/ISE-FIZKarlsruhe/concept_extraction.
Semantic Web and Creative AI -- A Technical Report from ISWS 2023
Jan 30, 2025



The International Semantic Web Research School (ISWS) is a week-long intensive program designed to immerse participants in the field. This document reports a collaborative effort performed by ten teams of students, each guided by a senior researcher as their mentor, attending ISWS 2023. Each team provided a different perspective to the topic of creative AI, substantiated by a set of research questions as the main subject of their investigation. The 2023 edition of ISWS focuses on the intersection of Semantic Web technologies and Creative AI. ISWS 2023 explored various intersections between Semantic Web technologies and creative AI. A key area of focus was the potential of LLMs as support tools for knowledge engineering. Participants also delved into the multifaceted applications of LLMs, including legal aspects of creative content production, humans in the loop, decentralised approaches to multimodal generative AI models, nanopublications and AI for personal scientific knowledge graphs, commonsense knowledge in automatic story and narrative completion, generative AI for art critique, prompt engineering, automatic music composition, commonsense prototyping and conceptual blending, and elicitation of tacit knowledge. As Large Language Models and semantic technologies continue to evolve, new exciting prospects are emerging: a future where the boundaries between creative expression and factual knowledge become increasingly permeable and porous, leading to a world of knowledge that is both informative and inspiring.
NFDI4DSO: Towards a BFO Compliant Ontology for Data Science
Aug 16, 2024


The NFDI4DataScience (NFDI4DS) project aims to enhance the accessibility and interoperability of research data within Data Science (DS) and Artificial Intelligence (AI) by connecting digital artifacts and ensuring they adhere to FAIR (Findable, Accessible, Interoperable, and Reusable) principles. To this end, this poster introduces the NFDI4DS Ontology, which describes resources in DS and AI and models the structure of the NFDI4DS consortium. Built upon the NFDICore ontology and mapped to the Basic Formal Ontology (BFO), this ontology serves as the foundation for the NFDI4DS knowledge graph currently under development.
The landscape of ontologies in materials science and engineering: A survey and evaluation
Aug 12, 2024Ontologies are widely used in materials science to describe experiments, processes, material properties, and experimental and computational workflows. Numerous online platforms are available for accessing and sharing ontologies in Materials Science and Engineering (MSE). Additionally, several surveys of these ontologies have been conducted. However, these studies often lack comprehensive analysis and quality control metrics. This paper provides an overview of ontologies used in Materials Science and Engineering to assist domain experts in selecting the most suitable ontology for a given purpose. Sixty selected ontologies are analyzed and compared based on the requirements outlined in this paper. Statistical data on ontology reuse and key metrics are also presented. The evaluation results provide valuable insights into the strengths and weaknesses of the investigated MSE ontologies. This enables domain experts to select suitable ontologies and to incorporate relevant terms from existing resources.
OAEI Machine Learning Dataset for Online Model Generation
Apr 29, 2024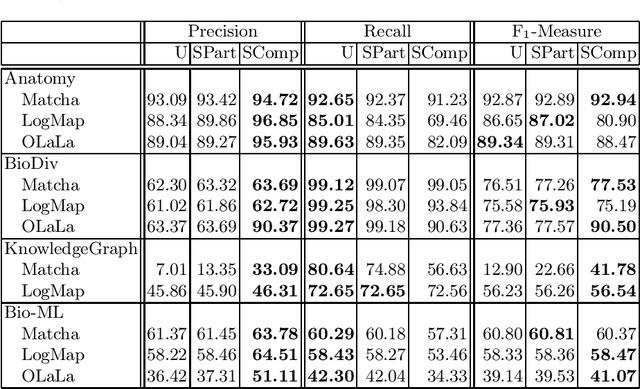
Ontology and knowledge graph matching systems are evaluated annually by the Ontology Alignment Evaluation Initiative (OAEI). More and more systems use machine learning-based approaches, including large language models. The training and validation datasets are usually determined by the system developer and often a subset of the reference alignments are used. This sampling is against the OAEI rules and makes a fair comparison impossible. Furthermore, those models are trained offline (a trained and optimized model is packaged into the matcher) and therefore the systems are specifically trained for those tasks. In this paper, we introduce a dataset that contains training, validation, and test sets for most of the OAEI tracks. Thus, online model learning (the systems must adapt to the given input alignment without human intervention) is made possible to enable a fair comparison for ML-based systems. We showcase the usefulness of the dataset by fine-tuning the confidence thresholds of popular systems.
Multimodal Search on Iconclass using Vision-Language Pre-Trained Models
Jun 23, 2023
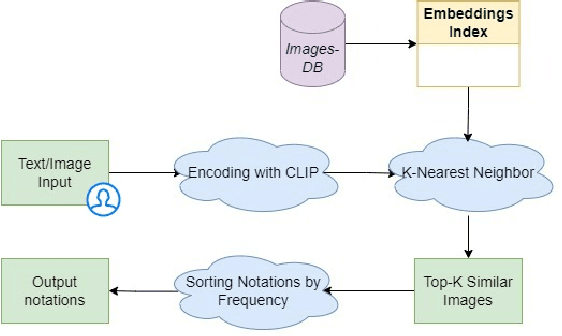
Terminology sources, such as controlled vocabularies, thesauri and classification systems, play a key role in digitizing cultural heritage. However, Information Retrieval (IR) systems that allow to query and explore these lexical resources often lack an adequate representation of the semantics behind the user's search, which can be conveyed through multiple expression modalities (e.g., images, keywords or textual descriptions). This paper presents the implementation of a new search engine for one of the most widely used iconography classification system, Iconclass. The novelty of this system is the use of a pre-trained vision-language model, namely CLIP, to retrieve and explore Iconclass concepts using visual or textual queries.
RAILD: Towards Leveraging Relation Features for Inductive Link Prediction In Knowledge Graphs
Nov 21, 2022Due to the open world assumption, Knowledge Graphs (KGs) are never complete. In order to address this issue, various Link Prediction (LP) methods are proposed so far. Some of these methods are inductive LP models which are capable of learning representations for entities not seen during training. However, to the best of our knowledge, none of the existing inductive LP models focus on learning representations for unseen relations. In this work, a novel Relation Aware Inductive Link preDiction (RAILD) is proposed for KG completion which learns representations for both unseen entities and unseen relations. In addition to leveraging textual literals associated with both entities and relations by employing language models, RAILD also introduces a novel graph-based approach to generate features for relations. Experiments are conducted with different existing and newly created challenging benchmark datasets and the results indicate that RAILD leads to performance improvement over the state-of-the-art models. Moreover, since there are no existing inductive LP models which learn representations for unseen relations, we have created our own baselines and the results obtained with RAILD also outperform these baselines.
Entity Type Prediction Leveraging Graph Walks and Entity Descriptions
Jul 29, 2022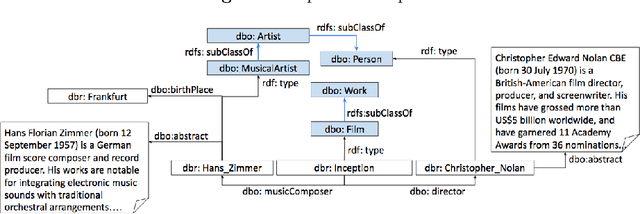
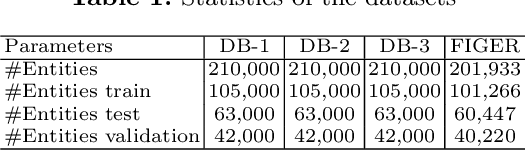
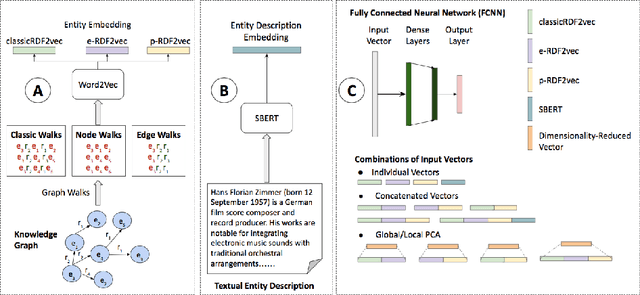
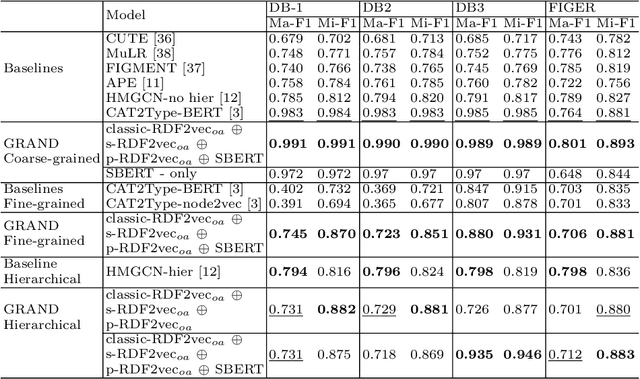
The entity type information in Knowledge Graphs (KGs) such as DBpedia, Freebase, etc. is often incomplete due to automated generation or human curation. Entity typing is the task of assigning or inferring the semantic type of an entity in a KG. This paper presents \textit{GRAND}, a novel approach for entity typing leveraging different graph walk strategies in RDF2vec together with textual entity descriptions. RDF2vec first generates graph walks and then uses a language model to obtain embeddings for each node in the graph. This study shows that the walk generation strategy and the embedding model have a significant effect on the performance of the entity typing task. The proposed approach outperforms the baseline approaches on the benchmark datasets DBpedia and FIGER for entity typing in KGs for both fine-grained and coarse-grained classes. The results show that the combination of order-aware RDF2vec variants together with the contextual embeddings of the textual entity descriptions achieve the best results.
A Knowledge Graph Embeddings based Approach for Author Name Disambiguation using Literals
Jan 24, 2022


Scholarly data is growing continuously containing information about the articles from plethora of venues including conferences, journals, etc. Many initiatives have been taken to make scholarly data available in the for of Knowledge Graphs (KGs). These efforts to standardize these data and make them accessible have also lead to many challenges such as exploration of scholarly articles, ambiguous authors, etc. This study more specifically targets the problem of Author Name Disambiguation (AND) on Scholarly KGs and presents a novel framework, Literally Author Name Disambiguation (LAND), which utilizes Knowledge Graph Embeddings (KGEs) using multimodal literal information generated from these KGs. This framework is based on three components: 1) Multimodal KGEs, 2) A blocking procedure, and finally, 3) Hierarchical Agglomerative Clustering. Extensive experiments have been conducted on two newly created KGs: (i) KG containing information from Scientometrics Journal from 1978 onwards (OC-782K), and (ii) a KG extracted from a well-known benchmark for AND provided by AMiner (AMiner-534K). The results show that our proposed architecture outperforms our baselines of 8-14\% in terms of F$_1$ score and shows competitive performances on a challenging benchmark such as AMiner. The code and the datasets are publicly available through Github (https://github.com/sntcristian/and-kge) and Zenodo (https://zenodo.org/record/5675787\#.YcCJzL3MJTY) respectively.
MigrationsKB: A Knowledge Base of Public Attitudes towards Migrations and their Driving Factors
Aug 17, 2021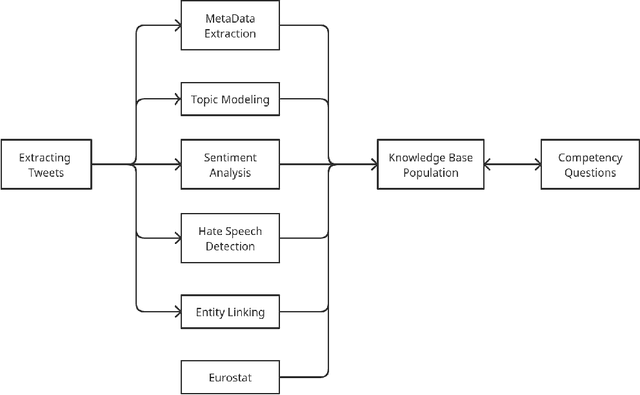
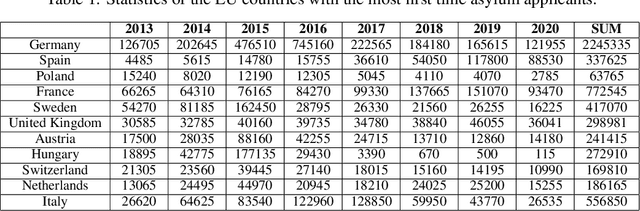

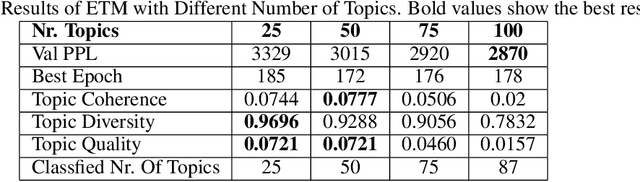
With the increasing trend in the topic of migration in Europe, the public is now more engaged in expressing their opinions through various platforms such as Twitter. Understanding the online discourses is therefore essential to capture the public opinion. The goal of this study is the analysis of social media platform to quantify public attitudes towards migrations and the identification of different factors causing these attitudes. The tweets spanning from 2013 to Jul-2021 in the European countries which are hosts to immigrants are collected, pre-processed, and filtered using advanced topic modeling technique. BERT-based entity linking and sentiment analysis, and attention-based hate speech detection are performed to annotate the curated tweets. Moreover, the external databases are used to identify the potential social and economic factors causing negative attitudes of the people about migration. To further promote research in the interdisciplinary fields of social science and computer science, the outcomes are integrated into a Knowledge Base (KB), i.e., MigrationsKB which significantly extends the existing models to take into account the public attitudes towards migrations and the economic indicators. This KB is made public using FAIR principles, which can be queried through SPARQL endpoint. Data dumps are made available on Zenodo.