 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurosymbolic Methods for Dynamic Knowledge Graphs
Sep 06, 2024

Knowledge graphs (KGs) have recently been used for many tools and applications, making them rich resources in structured format. However, in the real world, KGs grow due to the additions of new knowledge in the form of entities and relations, making these KGs dynamic. This chapter formally defines several types of dynamic KGs and summarizes how these KGs can be represented. Additionally, many neurosymbolic methods have been proposed for learning representations over static KGs for several tasks such as KG completion and entity alignment. This chapter further focuses on neurosymbolic methods for dynamic KGs with or without temporal information. More specifically, it provides an insight into neurosymbolic methods for dynamic (temporal or non-temporal) KG completion and entity alignment tasks. It further discusses the challenges of current approaches and provides some future directions.
NFDI4DSO: Towards a BFO Compliant Ontology for Data Science
Aug 16, 2024


The NFDI4DataScience (NFDI4DS) project aims to enhance the accessibility and interoperability of research data within Data Science (DS) and Artificial Intelligence (AI) by connecting digital artifacts and ensuring they adhere to FAIR (Findable, Accessible, Interoperable, and Reusable) principles. To this end, this poster introduces the NFDI4DS Ontology, which describes resources in DS and AI and models the structure of the NFDI4DS consortium. Built upon the NFDICore ontology and mapped to the Basic Formal Ontology (BFO), this ontology serves as the foundation for the NFDI4DS knowledge graph currently under development.
RAILD: Towards Leveraging Relation Features for Inductive Link Prediction In Knowledge Graphs
Nov 21, 2022Due to the open world assumption, Knowledge Graphs (KGs) are never complete. In order to address this issue, various Link Prediction (LP) methods are proposed so far. Some of these methods are inductive LP models which are capable of learning representations for entities not seen during training. However, to the best of our knowledge, none of the existing inductive LP models focus on learning representations for unseen relations. In this work, a novel Relation Aware Inductive Link preDiction (RAILD) is proposed for KG completion which learns representations for both unseen entities and unseen relations. In addition to leveraging textual literals associated with both entities and relations by employing language models, RAILD also introduces a novel graph-based approach to generate features for relations. Experiments are conducted with different existing and newly created challenging benchmark datasets and the results indicate that RAILD leads to performance improvement over the state-of-the-art models. Moreover, since there are no existing inductive LP models which learn representations for unseen relations, we have created our own baselines and the results obtained with RAILD also outperform these baselines.
A Knowledge Graph Embeddings based Approach for Author Name Disambiguation using Literals
Jan 24, 2022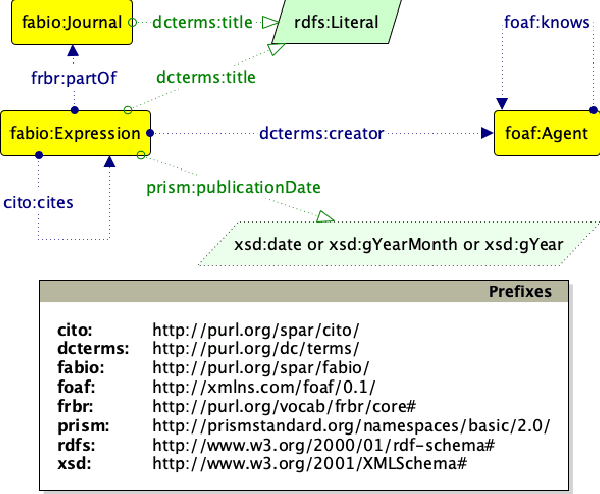

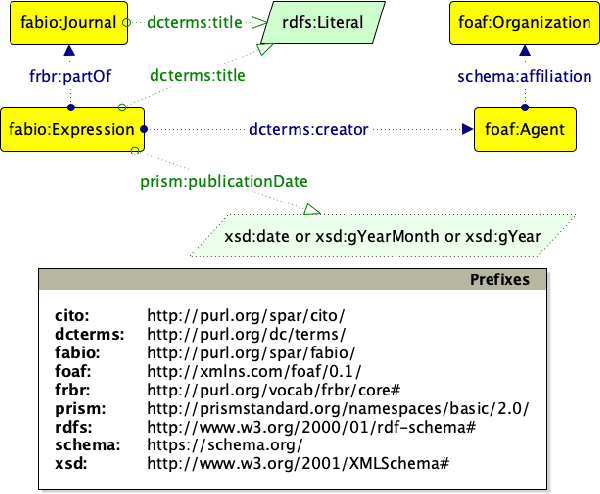

Scholarly data is growing continuously containing information about the articles from plethora of venues including conferences, journals, etc. Many initiatives have been taken to make scholarly data available in the for of Knowledge Graphs (KGs). These efforts to standardize these data and make them accessible have also lead to many challenges such as exploration of scholarly articles, ambiguous authors, etc. This study more specifically targets the problem of Author Name Disambiguation (AND) on Scholarly KGs and presents a novel framework, Literally Author Name Disambiguation (LAND), which utilizes Knowledge Graph Embeddings (KGEs) using multimodal literal information generated from these KGs. This framework is based on three components: 1) Multimodal KGEs, 2) A blocking procedure, and finally, 3) Hierarchical Agglomerative Clustering. Extensive experiments have been conducted on two newly created KGs: (i) KG containing information from Scientometrics Journal from 1978 onwards (OC-782K), and (ii) a KG extracted from a well-known benchmark for AND provided by AMiner (AMiner-534K). The results show that our proposed architecture outperforms our baselines of 8-14\% in terms of F$_1$ score and shows competitive performances on a challenging benchmark such as AMiner. The code and the datasets are publicly available through Github (https://github.com/sntcristian/and-kge) and Zenodo (https://zenodo.org/record/5675787\#.YcCJzL3MJTY) respectively.
Knowledge Graphs Evolution and Preservation -- A Technical Report from ISWS 2019
Dec 22, 2020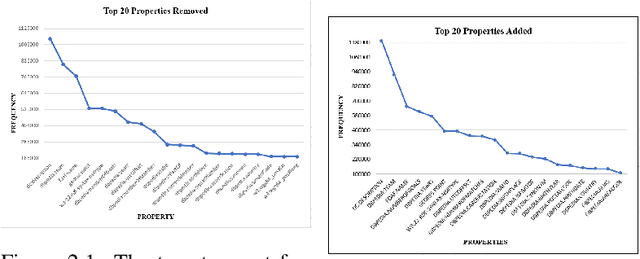
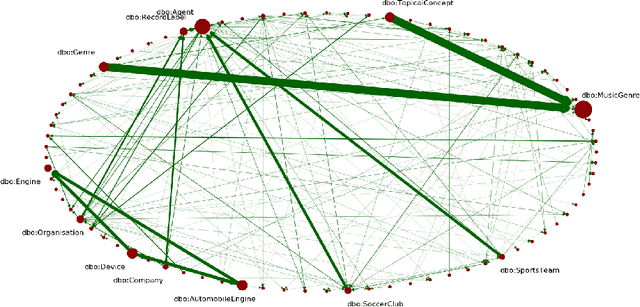

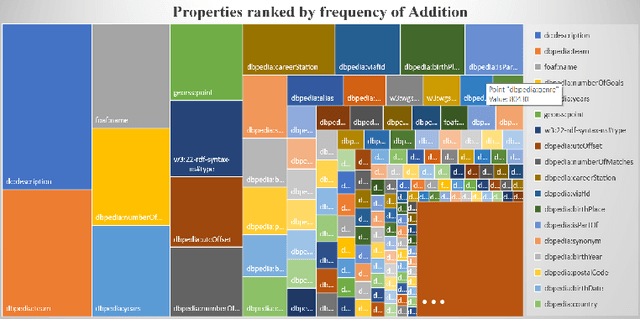
One of the grand challenges discussed during the Dagstuhl Seminar "Knowledge Graphs: New Directions for Knowledge Representation on the Semantic Web" and described in its report is that of a: "Public FAIR Knowledge Graph of Everything: We increasingly see the creation of knowledge graphs that capture information about the entirety of a class of entities. [...] This grand challenge extends this further by asking if we can create a knowledge graph of "everything" ranging from common sense concepts to location based entities. This knowledge graph should be "open to the public" in a FAIR manner democratizing this mass amount of knowledge." Although linked open data (LOD) is one knowledge graph, it is the closest realisation (and probably the only one) to a public FAIR Knowledge Graph (KG) of everything. Surely, LOD provides a unique testbed for experimenting and evaluating research hypotheses on open and FAIR KG. One of the most neglected FAIR issues about KGs is their ongoing evolution and long term preservation. We want to investigate this problem, that is to understand what preserving and supporting the evolution of KGs means and how these problems can be addressed. Clearly, the problem can be approached from different perspectives and may require the development of different approaches, including new theories, ontologies, metrics, strategies, procedures, etc. This document reports a collaborative effort performed by 9 teams of students, each guided by a senior researcher as their mentor, attending the International Semantic Web Research School (ISWS 2019). Each team provides a different perspective to the problem of knowledge graph evolution substantiated by a set of research questions as the main subject of their investigation. In addition, they provide their working definition for KG preservation and evolution.
Semantic Entity Enrichment by Leveraging Multilingual Descriptions for Link Prediction
Apr 22, 2020
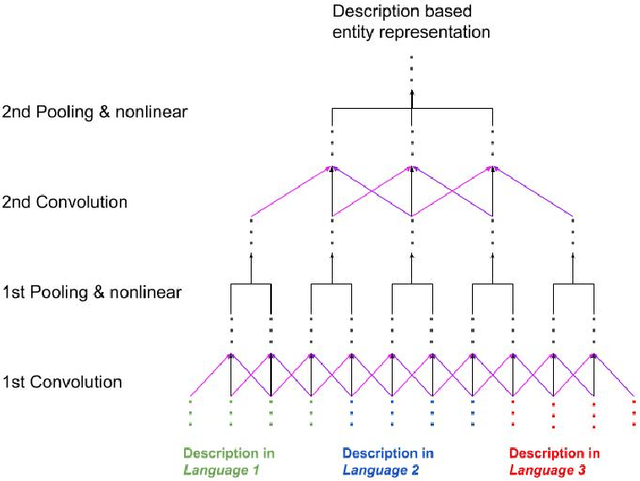
Most Knowledge Graphs (KGs) contain textual descriptions of entities in various natural languages. These descriptions of entities provide valuable information that may not be explicitly represented in the structured part of the KG. Based on this fact, some link prediction methods which make use of the information presented in the textual descriptions of entities have been proposed to learn representations of (monolingual) KGs. However, these methods use entity descriptions in only one language and ignore the fact that descriptions given in different languages may provide complementary information and thereby also additional semantics. In this position paper, the problem of effectively leveraging multilingual entity descriptions for the purpose of link prediction in KGs will be discussed along with potential solutions to the problem.
A Survey on Knowledge Graph Embeddings with Literals: Which model links better Literal-ly?
Oct 28, 2019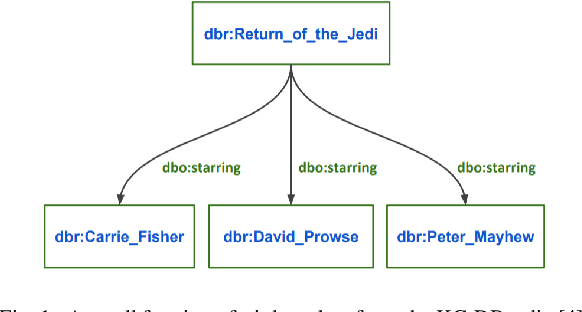
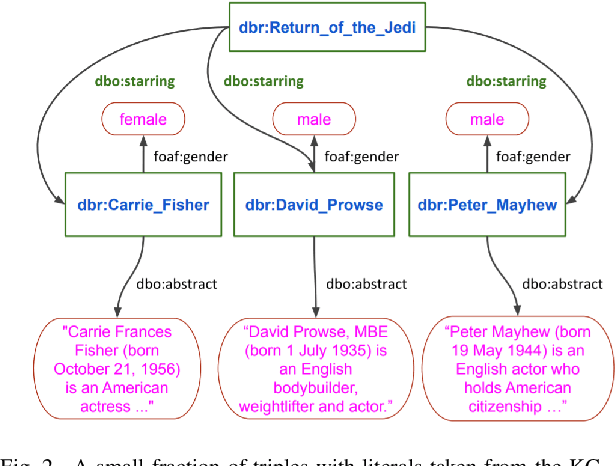

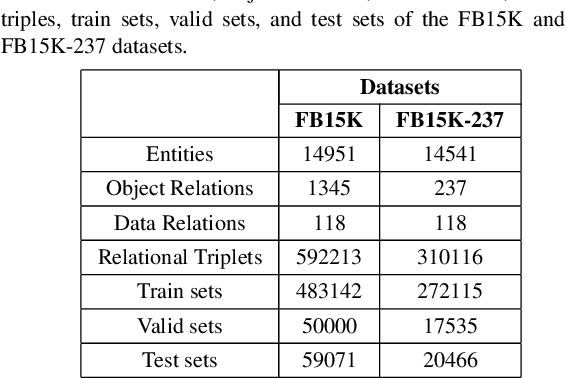
Knowledge Graphs (KGs) are composed of structured information about a particular domain in the form of entities and relations. In addition to the structured information KGs help in facilitating interconnectivity and interoperability between different resources represented in the Linked Data Cloud. KGs have been used in a variety of applications such as entity linking, question answering, recommender systems, etc. However, KG applications suffer from high computational and storage costs. Hence, there arises the necessity for a representation able to map the high dimensional KGs into low dimensional spaces, i.e., embedding space, preserving structural as well as relational information. This paper conducts a survey of KG embedding models which not only consider the structured information contained in the form of entities and relations in a KG but also the unstructured information represented as literals such as text, numerical values, images, etc. Along with a theoretical analysis and comparison of the methods proposed so far for generating KG embeddings with literals, an empirical evaluation of the different methods under identical settings has been performed for the general task of link prediction.