 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQiana: A First-Order Formalism to Quantify over Contexts and Formulas with Temporality
Apr 02, 2026We introduce Qiana, a logic framework for reasoning on formulas that are true only in specific contexts. In Qiana, it is possible to quantify over both formulas and contexts to express, e.g., that ``everyone knows everything Alice says''. Qiana also permits paraconsistent logics within contexts, so that contexts can contain contradictions. Furthermore, Qiana is based on first-order logic, and is finitely axiomatizable, so that Qiana theories are compatible with pre-existing first-order logic theorem provers. We show how Qiana can be used to represent temporality, event calculus, and modal logic. We also discuss different design alternatives of Qiana.
Neurosymbolic Methods for Dynamic Knowledge Graphs
Sep 06, 2024

Knowledge graphs (KGs) have recently been used for many tools and applications, making them rich resources in structured format. However, in the real world, KGs grow due to the additions of new knowledge in the form of entities and relations, making these KGs dynamic. This chapter formally defines several types of dynamic KGs and summarizes how these KGs can be represented. Additionally, many neurosymbolic methods have been proposed for learning representations over static KGs for several tasks such as KG completion and entity alignment. This chapter further focuses on neurosymbolic methods for dynamic KGs with or without temporal information. More specifically, it provides an insight into neurosymbolic methods for dynamic (temporal or non-temporal) KG completion and entity alignment tasks. It further discusses the challenges of current approaches and provides some future directions.
MAFALDA: A Benchmark and Comprehensive Study of Fallacy Detection and Classification
Nov 16, 2023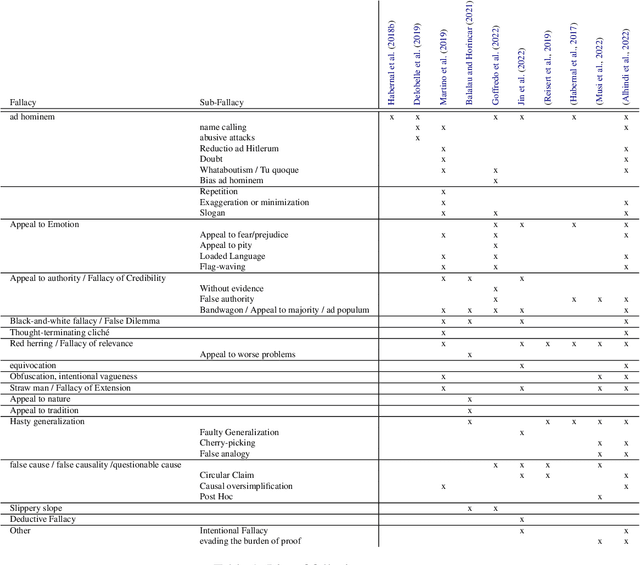

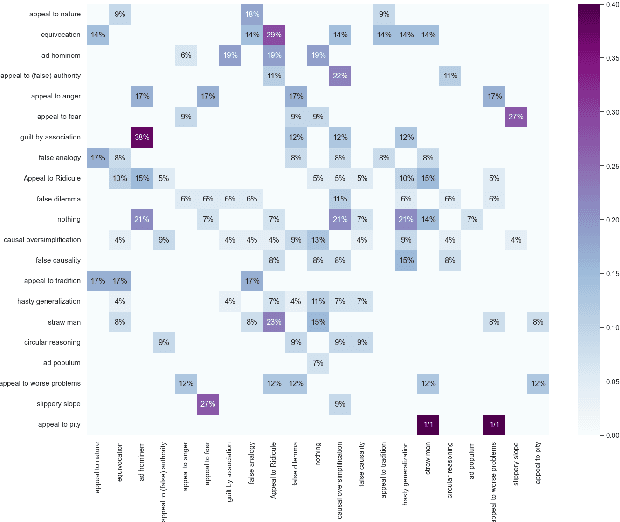
Fallacies can be used to spread disinformation, fake news, and propaganda, underlining the importance of their detection. Automated detection and classification of fallacies, however, remain challenging, mainly because of the innate subjectivity of the task and the need for a comprehensive, unified approach in existing research. Addressing these limitations, our study introduces a novel taxonomy of fallacies that aligns and refines previous classifications, a new annotation scheme tailored for subjective NLP tasks, and a new evaluation method designed to handle subjectivity, adapted to precision, recall, and F1-Score metrics. Using our annotation scheme, the paper introduces MAFALDA (Multi-level Annotated FALlacy DAtaset), a gold standard dataset. MAFALDA is based on examples from various previously existing fallacy datasets under our unified taxonomy across three levels of granularity. We then evaluate several language models under a zero-shot learning setting using MAFALDA to assess their fallacy detection and classification capability. Our comprehensive evaluation not only benchmarks the performance of these models but also provides valuable insights into their strengths and limitations in addressing fallacious reasoning.
Integrating the Wikidata Taxonomy into YAGO
Aug 23, 2023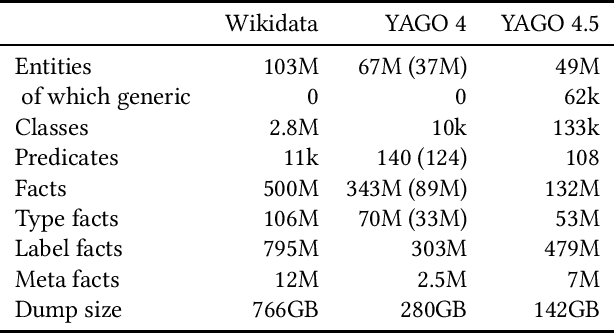
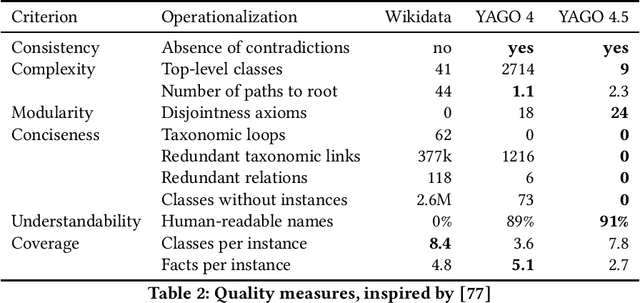
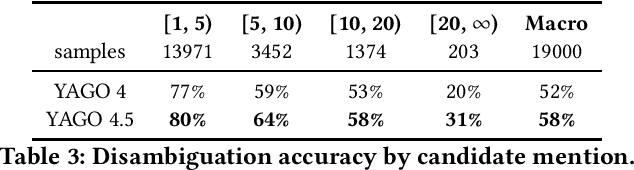
Wikidata is one of the largest public general-purpose Knowledge Bases (KBs). Yet, due to its collaborative nature, its schema and taxonomy have become convoluted. For the YAGO 4 KB, we combined Wikidata with the ontology from Schema.org, which reduced and cleaned up the taxonomy and constraints and made it possible to run automated reasoners on the data. However, it also cut away large parts of the Wikidata taxonomy. In this paper, we present our effort to merge the entire Wikidata taxonomy into the YAGO KB as much as possible. We pay particular attention to logical constraints and a careful distinction of classes and instances. Our work creates YAGO 4.5, which adds a rich layer of informative classes to YAGO, while at the same time keeping the KB logically consistent.