 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQiana: A First-Order Formalism to Quantify over Contexts and Formulas with Temporality
Apr 02, 2026We introduce Qiana, a logic framework for reasoning on formulas that are true only in specific contexts. In Qiana, it is possible to quantify over both formulas and contexts to express, e.g., that ``everyone knows everything Alice says''. Qiana also permits paraconsistent logics within contexts, so that contexts can contain contradictions. Furthermore, Qiana is based on first-order logic, and is finitely axiomatizable, so that Qiana theories are compatible with pre-existing first-order logic theorem provers. We show how Qiana can be used to represent temporality, event calculus, and modal logic. We also discuss different design alternatives of Qiana.
The Factuality of Large Language Models in the Legal Domain
Sep 18, 2024



This paper investigates the factuality of large language models (LLMs) as knowledge bases in the legal domain, in a realistic usage scenario: we allow for acceptable variations in the answer, and let the model abstain from answering when uncertain. First, we design a dataset of diverse factual questions about case law and legislation. We then use the dataset to evaluate several LLMs under different evaluation methods, including exact, alias, and fuzzy matching. Our results show that the performance improves significantly under the alias and fuzzy matching methods. Further, we explore the impact of abstaining and in-context examples, finding that both strategies enhance precision. Finally, we demonstrate that additional pre-training on legal documents, as seen with SaulLM, further improves factual precision from 63% to 81%.
MAFALDA: A Benchmark and Comprehensive Study of Fallacy Detection and Classification
Nov 16, 2023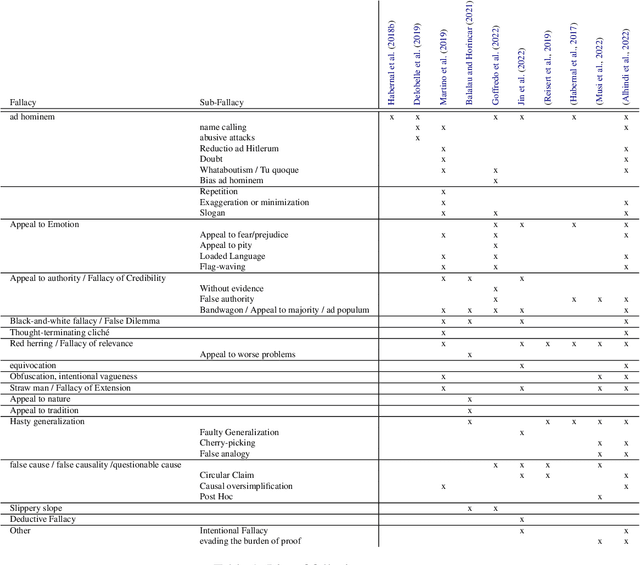

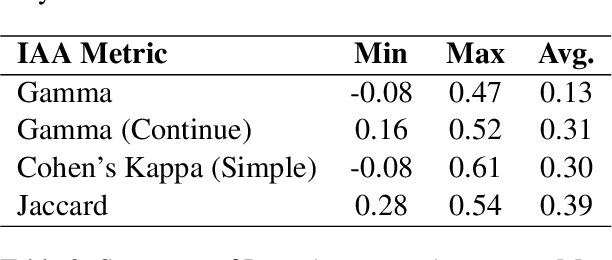
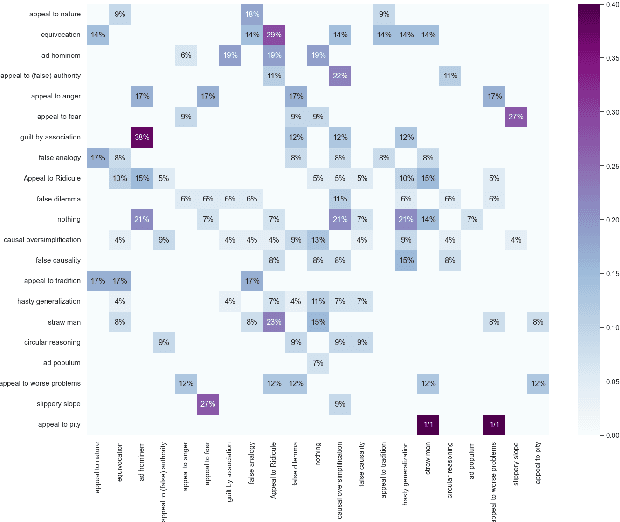
Fallacies can be used to spread disinformation, fake news, and propaganda, underlining the importance of their detection. Automated detection and classification of fallacies, however, remain challenging, mainly because of the innate subjectivity of the task and the need for a comprehensive, unified approach in existing research. Addressing these limitations, our study introduces a novel taxonomy of fallacies that aligns and refines previous classifications, a new annotation scheme tailored for subjective NLP tasks, and a new evaluation method designed to handle subjectivity, adapted to precision, recall, and F1-Score metrics. Using our annotation scheme, the paper introduces MAFALDA (Multi-level Annotated FALlacy DAtaset), a gold standard dataset. MAFALDA is based on examples from various previously existing fallacy datasets under our unified taxonomy across three levels of granularity. We then evaluate several language models under a zero-shot learning setting using MAFALDA to assess their fallacy detection and classification capability. Our comprehensive evaluation not only benchmarks the performance of these models but also provides valuable insights into their strengths and limitations in addressing fallacious reasoning.
Integrating the Wikidata Taxonomy into YAGO
Aug 23, 2023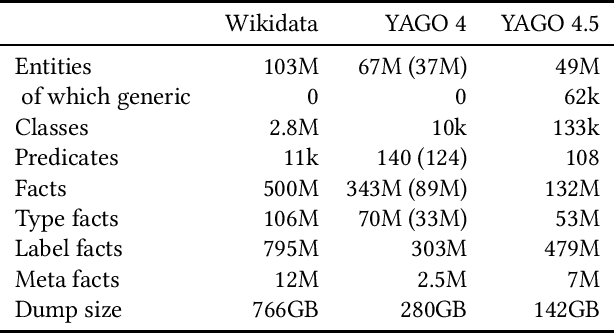
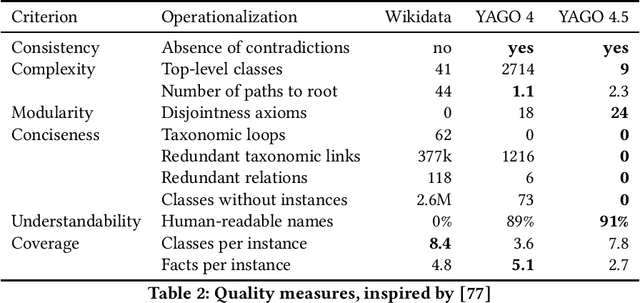
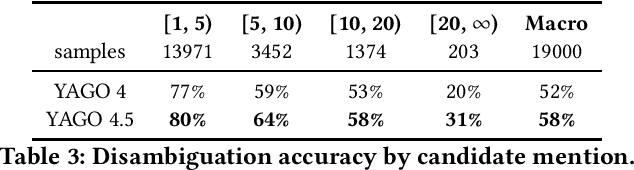
Wikidata is one of the largest public general-purpose Knowledge Bases (KBs). Yet, due to its collaborative nature, its schema and taxonomy have become convoluted. For the YAGO 4 KB, we combined Wikidata with the ontology from Schema.org, which reduced and cleaned up the taxonomy and constraints and made it possible to run automated reasoners on the data. However, it also cut away large parts of the Wikidata taxonomy. In this paper, we present our effort to merge the entire Wikidata taxonomy into the YAGO KB as much as possible. We pay particular attention to logical constraints and a careful distinction of classes and instances. Our work creates YAGO 4.5, which adds a rich layer of informative classes to YAGO, while at the same time keeping the KB logically consistent.
BELLA: Black box model Explanations by Local Linear Approximations
May 18, 2023



In recent years, understanding the decision-making process of black-box models has become not only a legal requirement but also an additional way to assess their performance. However, the state of the art post-hoc interpretation approaches rely on synthetic data generation. This introduces uncertainty and can hurt the reliability of the interpretations. Furthermore, they tend to produce explanations that apply to only very few data points. This makes the explanations brittle and limited in scope. Finally, they provide scores that have no direct verifiable meaning. In this paper, we present BELLA, a deterministic model-agnostic post-hoc approach for explaining the individual predictions of regression black-box models. BELLA provides explanations in the form of a linear model trained in the feature space. Thus, its coefficients can be used directly to compute the predicted value from the feature values. Furthermore, BELLA maximizes the size of the neighborhood to which the linear model applies, so that the explanations are accurate, simple, general, and robust. BELLA can produce both factual and counterfactual explanations. Our user study confirms the importance of the desiderata we optimize, and our experiments show that BELLA outperforms the state-of-the-art approaches on these desiderata.
Completeness, Recall, and Negation in Open-World Knowledge Bases: A Survey
May 09, 2023General-purpose knowledge bases (KBs) are a cornerstone of knowledge-centric AI. Many of them are constructed pragmatically from Web sources, and are thus far from complete. This poses challenges for the consumption as well as the curation of their content. While several surveys target the problem of completing incomplete KBs, the first problem is arguably to know whether and where the KB is incomplete in the first place, and to which degree. In this survey we discuss how knowledge about completeness, recall, and negation in KBs can be expressed, extracted, and inferred. We cover (i) the logical foundations of knowledge representation and querying under partial closed-world semantics; (ii) the estimation of this information via statistical patterns; (iii) the extraction of information about recall from KBs and text; (iv) the identification of interesting negative statements; and (v) relaxed notions of relative recall. This survey is targeted at two types of audiences: (1) practitioners who are interested in tracking KB quality, focusing extraction efforts, and building quality-aware downstream applications; and (2) data management, knowledge base and semantic web researchers who wish to understand the state of the art of knowledge bases beyond the open-world assumption. Consequently, our survey presents both fundamental methodologies and their working, and gives practice-oriented recommendations on how to choose between different approaches for a problem at hand.
* 33 pages, 5 tables
Machine Knowledge: Creation and Curation of Comprehensive Knowledge Bases
Sep 24, 2020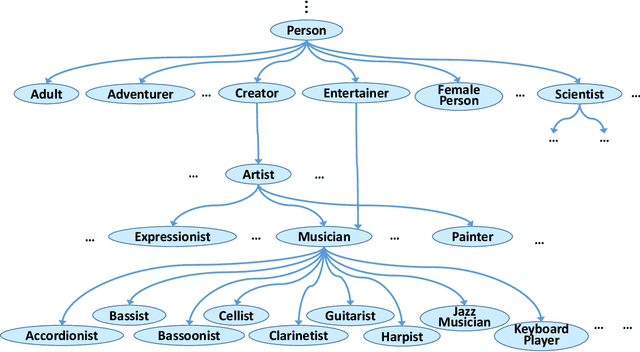
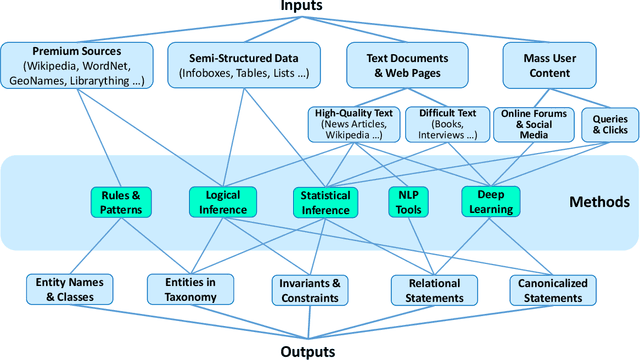


Equipping machines with comprehensive knowledge of the world's entities and their relationships has been a long-standing goal of AI. Over the last decade, large-scale knowledge bases, also known as knowledge graphs, have been automatically constructed from web contents and text sources, and have become a key asset for search engines. This machine knowledge can be harnessed to semantically interpret textual phrases in news, social media and web tables, and contributes to question answering, natural language processing and data analytics. This article surveys fundamental concepts and practical methods for creating and curating large knowledge bases. It covers models and methods for discovering and canonicalizing entities and their semantic types and organizing them into clean taxonomies. On top of this, the article discusses the automatic extraction of entity-centric properties. To support the long-term life-cycle and the quality assurance of machine knowledge, the article presents methods for constructing open schemas and for knowledge curation. Case studies on academic projects and industrial knowledge graphs complement the survey of concepts and methods.
NeuroQuery: comprehensive meta-analysis of human brain mapping
Feb 21, 2020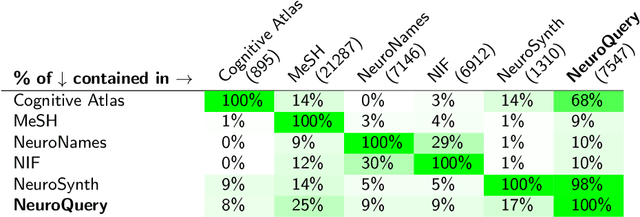
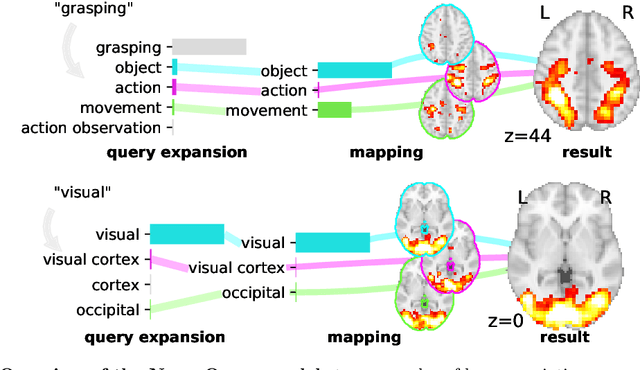
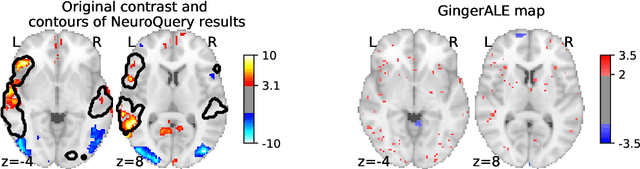
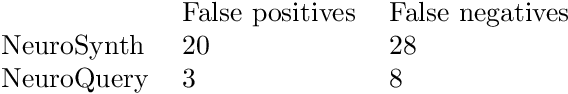
Reaching a global view of brain organization requires assembling evidence on widely different mental processes and mechanisms. The variety of human neuroscience concepts and terminology poses a fundamental challenge to relating brain imaging results across the scientific literature. Existing meta-analysis methods perform statistical tests on sets of publications associated with a particular concept. Thus, large-scale meta-analyses only tackle single terms that occur frequently. We propose a new paradigm, focusing on prediction rather than inference. Our multivariate model predicts the spatial distribution of neurological observations, given text describing an experiment, cognitive process, or disease. This approach handles text of arbitrary length and terms that are too rare for standard meta-analysis. We capture the relationships and neural correlates of 7 547 neuroscience terms across 13 459 neuroimaging publications. The resulting meta-analytic tool, neuroquery.org, can ground hypothesis generation and data-analysis priors on a comprehensive view of published findings on the brain.
Text to brain: predicting the spatial distribution of neuroimaging observations from text reports
Jun 28, 2018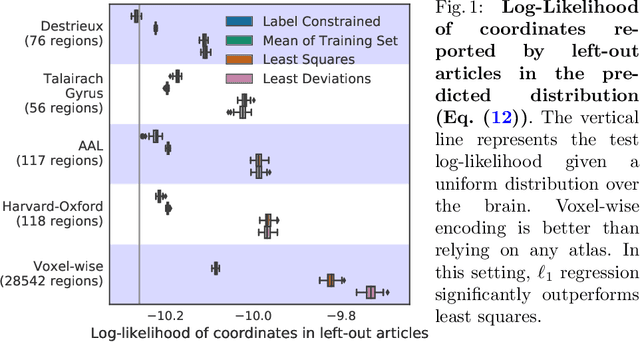
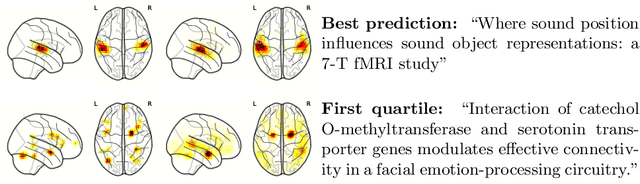
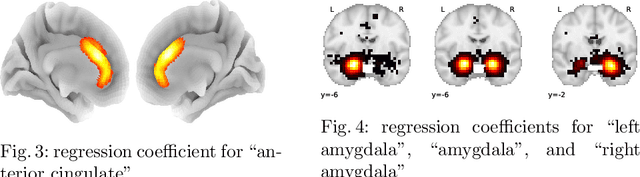
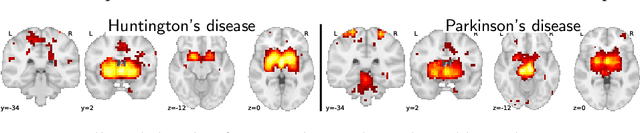
Despite the digital nature of magnetic resonance imaging, the resulting observations are most frequently reported and stored in text documents. There is a trove of information untapped in medical health records, case reports, and medical publications. In this paper, we propose to mine brain medical publications to learn the spatial distribution associated with anatomical terms. The problem is formulated in terms of minimization of a risk on distributions which leads to a least-deviation cost function. An efficient algorithm in the dual then learns the mapping from documents to brain structures. Empirical results using coordinates extracted from the brain-imaging literature show that i) models must adapt to semantic variation in the terms used to describe a given anatomical structure, ii) voxel-wise parameterization leads to higher likelihood of locations reported in unseen documents, iii) least-deviation cost outperforms least-square. As a proof of concept for our method, we use our model of spatial distributions to predict the distribution of specific neurological conditions from text-only reports.
Ontology Alignment at the Instance and Schema Level
Aug 18, 2011
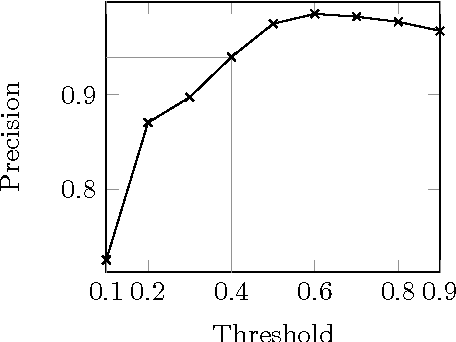
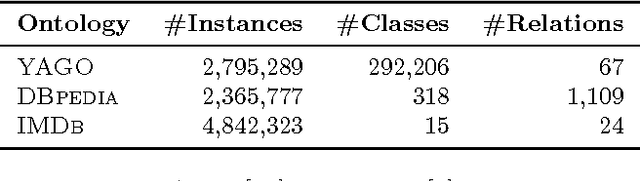

We present PARIS, an approach for the automatic alignment of ontologies. PARIS aligns not only instances, but also relations and classes. Alignments at the instance-level cross-fertilize with alignments at the schema-level. Thereby, our system provides a truly holistic solution to the problem of ontology alignment. The heart of the approach is probabilistic. This allows PARIS to run without any parameter tuning. We demonstrate the efficiency of the algorithm and its precision through extensive experiments. In particular, we obtain a precision of around 90% in experiments with two of the world's largest ontologies.
* Technical Report at INRIA RT-0408