 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPOT: An Annotated French Corpus and Benchmark for Detecting Critical Interventions in Online Conversations
Nov 10, 2025We introduce SPOT (Stopping Points in Online Threads), the first annotated corpus translating the sociological concept of stopping point into a reproducible NLP task. Stopping points are ordinary critical interventions that pause or redirect online discussions through a range of forms (irony, subtle doubt or fragmentary arguments) that frameworks like counterspeech or social correction often overlook. We operationalize this concept as a binary classification task and provide reliable annotation guidelines. The corpus contains 43,305 manually annotated French Facebook comments linked to URLs flagged as false information by social media users, enriched with contextual metadata (article, post, parent comment, page or group, and source). We benchmark fine-tuned encoder models (CamemBERT) and instruction-tuned LLMs under various prompting strategies. Results show that fine-tuned encoders outperform prompted LLMs in F1 score by more than 10 percentage points, confirming the importance of supervised learning for emerging non-English social media tasks. Incorporating contextual metadata further improves encoder models F1 scores from 0.75 to 0.78. We release the anonymized dataset, along with the annotation guidelines and code in our code repository, to foster transparency and reproducible research.
Graphically Speaking: Unmasking Abuse in Social Media with Conversation Insights
Apr 02, 2025Detecting abusive language in social media conversations poses significant challenges, as identifying abusiveness often depends on the conversational context, characterized by the content and topology of preceding comments. Traditional Abusive Language Detection (ALD) models often overlook this context, which can lead to unreliable performance metrics. Recent Natural Language Processing (NLP) methods that integrate conversational context often depend on limited and simplified representations, and report inconsistent results. In this paper, we propose a novel approach that utilize graph neural networks (GNNs) to model social media conversations as graphs, where nodes represent comments, and edges capture reply structures. We systematically investigate various graph representations and context windows to identify the optimal configuration for ALD. Our GNN model outperform both context-agnostic baselines and linear context-aware methods, achieving significant improvements in F1 scores. These findings demonstrate the critical role of structured conversational context and establish GNNs as a robust framework for advancing context-aware abusive language detection.
Benchmarking Linguistic Diversity of Large Language Models
Dec 13, 2024



The development and evaluation of Large Language Models (LLMs) has primarily focused on their task-solving capabilities, with recent models even surpassing human performance in some areas. However, this focus often neglects whether machine-generated language matches the human level of diversity, in terms of vocabulary choice, syntactic construction, and expression of meaning, raising questions about whether the fundamentals of language generation have been fully addressed. This paper emphasizes the importance of examining the preservation of human linguistic richness by language models, given the concerning surge in online content produced or aided by LLMs. We propose a comprehensive framework for evaluating LLMs from various linguistic diversity perspectives including lexical, syntactic, and semantic dimensions. Using this framework, we benchmark several state-of-the-art LLMs across all diversity dimensions, and conduct an in-depth case study for syntactic diversity. Finally, we analyze how different development and deployment choices impact the linguistic diversity of LLM outputs.
Socio-Emotional Response Generation: A Human Evaluation Protocol for LLM-Based Conversational Systems
Nov 26, 2024Conversational systems are now capable of producing impressive and generally relevant responses. However, we have no visibility nor control of the socio-emotional strategies behind state-of-the-art Large Language Models (LLMs), which poses a problem in terms of their transparency and thus their trustworthiness for critical applications. Another issue is that current automated metrics are not able to properly evaluate the quality of generated responses beyond the dataset's ground truth. In this paper, we propose a neural architecture that includes an intermediate step in planning socio-emotional strategies before response generation. We compare the performance of open-source baseline LLMs to the outputs of these same models augmented with our planning module. We also contrast the outputs obtained from automated metrics and evaluation results provided by human annotators. We describe a novel evaluation protocol that includes a coarse-grained consistency evaluation, as well as a finer-grained annotation of the responses on various social and emotional criteria. Our study shows that predicting a sequence of expected strategy labels and using this sequence to generate a response yields better results than a direct end-to-end generation scheme. It also highlights the divergences and the limits of current evaluation metrics for generated content. The code for the annotation platform and the annotated data are made publicly available for the evaluation of future models.
EmoDynamiX: Emotional Support Dialogue Strategy Prediction by Modelling MiXed Emotions and Discourse Dynamics
Aug 16, 2024
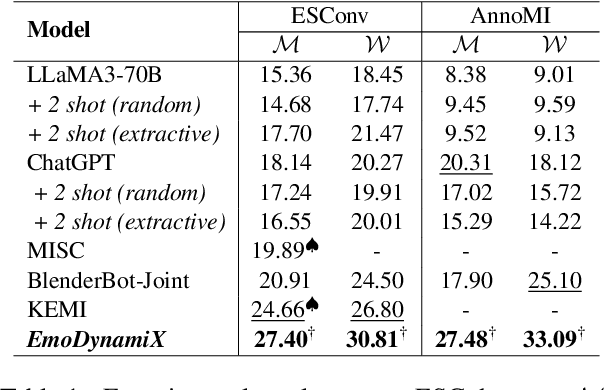
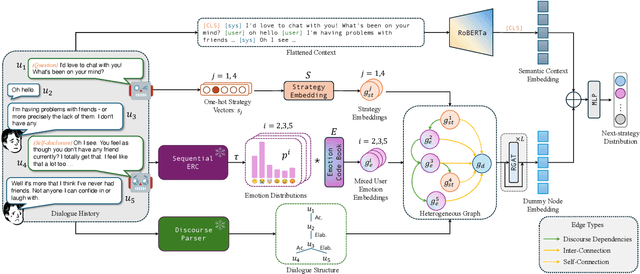
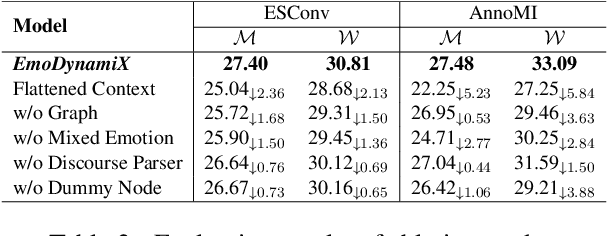
Designing emotionally intelligent conversational systems to provide comfort and advice to people experiencing distress is a compelling area of research. Previous efforts have focused on developing modular dialogue systems that treat socio-emotional strategy prediction as an auxiliary task and generate strategy-conditioned responses with customized decoders. Recently, with advancements in large language models (LLMs), end-to-end dialogue agents without explicit socio-emotional strategy prediction steps have become prevalent. However, despite their excellence in language generation, recent studies show that LLMs' inherent preference bias towards certain socio-emotional strategies hinders the delivery of high-quality emotional support. To address this challenge, we propose decoupling strategy prediction from language generation, and introduce a novel dialogue strategy predictor, EmoDynamiX, which models the discourse dynamics between user emotions and system strategies using a heterogeneous graph. Additionally, we make use of the Emotion Recognition in Conversations (ERC) task and design a flexible mixed-emotion module to capture fine-grained emotional states of the user. Experimental results on two ESC datasets show EmoDynamiX outperforms previous state-of-the-art methods with a significant margin.
Do Language Models Enjoy Their Own Stories? Prompting Large Language Models for Automatic Story Evaluation
May 22, 2024Storytelling is an integral part of human experience and plays a crucial role in social interactions. Thus, Automatic Story Evaluation (ASE) and Generation (ASG) could benefit society in multiple ways, but they are challenging tasks which require high-level human abilities such as creativity, reasoning and deep understanding. Meanwhile, Large Language Models (LLM) now achieve state-of-the-art performance on many NLP tasks. In this paper, we study whether LLMs can be used as substitutes for human annotators for ASE. We perform an extensive analysis of the correlations between LLM ratings, other automatic measures, and human annotations, and we explore the influence of prompting on the results and the explainability of LLM behaviour. Most notably, we find that LLMs outperform current automatic measures for system-level evaluation but still struggle at providing satisfactory explanations for their answers.
The Impact of Word Splitting on the Semantic Content of Contextualized Word Representations
Feb 22, 2024When deriving contextualized word representations from language models, a decision needs to be made on how to obtain one for out-of-vocabulary (OOV) words that are segmented into subwords. What is the best way to represent these words with a single vector, and are these representations of worse quality than those of in-vocabulary words? We carry out an intrinsic evaluation of embeddings from different models on semantic similarity tasks involving OOV words. Our analysis reveals, among other interesting findings, that the quality of representations of words that are split is often, but not always, worse than that of the embeddings of known words. Their similarity values, however, must be interpreted with caution.
Automatic Analysis of Substantiation in Scientific Peer Reviews
Nov 20, 2023With the increasing amount of problematic peer reviews in top AI conferences, the community is urgently in need of automatic quality control measures. In this paper, we restrict our attention to substantiation -- one popular quality aspect indicating whether the claims in a review are sufficiently supported by evidence -- and provide a solution automatizing this evaluation process. To achieve this goal, we first formulate the problem as claim-evidence pair extraction in scientific peer reviews, and collect SubstanReview, the first annotated dataset for this task. SubstanReview consists of 550 reviews from NLP conferences annotated by domain experts. On the basis of this dataset, we train an argument mining system to automatically analyze the level of substantiation in peer reviews. We also perform data analysis on the SubstanReview dataset to obtain meaningful insights on peer reviewing quality in NLP conferences over recent years.
The Curious Decline of Linguistic Diversity: Training Language Models on Synthetic Text
Nov 16, 2023This study investigates the consequences of training large language models (LLMs) on synthetic data generated by their predecessors, an increasingly prevalent practice aimed at addressing the limited supply of human-generated training data. Diverging from the usual emphasis on performance metrics, we focus on the impact of this training methodology on linguistic diversity, especially when conducted recursively over time. To assess this, we developed a set of novel metrics targeting lexical, syntactic, and semantic diversity, applying them in recursive fine-tuning experiments across various natural language generation tasks. Our findings reveal a marked decrease in the diversity of the models' outputs through successive iterations. This trend underscores the potential risks of training LLMs on predecessor-generated text, particularly concerning the preservation of linguistic richness. Our study highlights the need for careful consideration of the long-term effects of such training approaches on the linguistic capabilities of LLMs.
MAFALDA: A Benchmark and Comprehensive Study of Fallacy Detection and Classification
Nov 16, 2023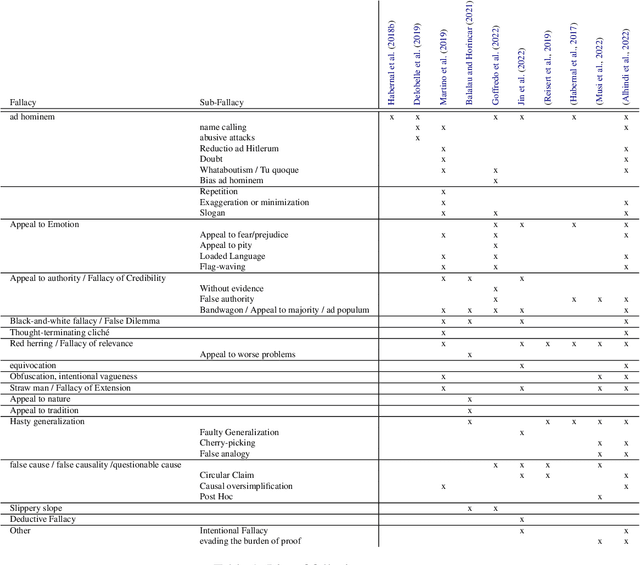

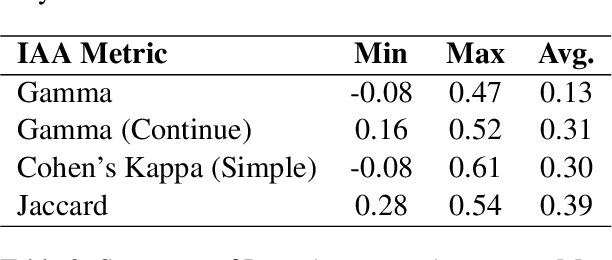
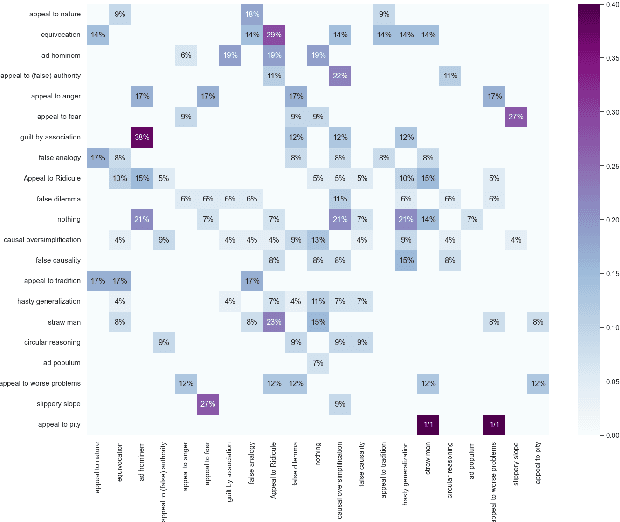
Fallacies can be used to spread disinformation, fake news, and propaganda, underlining the importance of their detection. Automated detection and classification of fallacies, however, remain challenging, mainly because of the innate subjectivity of the task and the need for a comprehensive, unified approach in existing research. Addressing these limitations, our study introduces a novel taxonomy of fallacies that aligns and refines previous classifications, a new annotation scheme tailored for subjective NLP tasks, and a new evaluation method designed to handle subjectivity, adapted to precision, recall, and F1-Score metrics. Using our annotation scheme, the paper introduces MAFALDA (Multi-level Annotated FALlacy DAtaset), a gold standard dataset. MAFALDA is based on examples from various previously existing fallacy datasets under our unified taxonomy across three levels of granularity. We then evaluate several language models under a zero-shot learning setting using MAFALDA to assess their fallacy detection and classification capability. Our comprehensive evaluation not only benchmarks the performance of these models but also provides valuable insights into their strengths and limitations in addressing fallacious reasoning.