 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTailoring Strictly Proper Scoring Rules for Downstream Tasks: An Application to Causal Inference
Jun 02, 2026Probabilistic models are typically trained using task-agnostic objectives like log-loss, which can lead to significant errors in downstream estimation. This disconnect is especially critical in Inverse Probability Weighting (IPW) for causal inference, where propensity score errors near $0$ and $1$ often lead to high bias and variance. We propose a principled framework for deriving task-specific strictly proper scoring rules by matching the local curvature of the downstream error metric. We apply this to the Average Treatment Effect (ATE) estimation, deriving a closed-form loss and its corresponding canonical probability mapping that can be readily integrated with any model like a neural network or a gradient boosting algorithm. Extensive evaluations on causal inference benchmarks demonstrate that our tailored objective consistently outperforms standard likelihood-based and covariate-balancing approaches.
Learning Differentiable Surrogate Losses for Structured Prediction
Nov 18, 2024


Structured prediction involves learning to predict complex structures rather than simple scalar values. The main challenge arises from the non-Euclidean nature of the output space, which generally requires relaxing the problem formulation. Surrogate methods build on kernel-induced losses or more generally, loss functions admitting an Implicit Loss Embedding, and convert the original problem into a regression task followed by a decoding step. However, designing effective losses for objects with complex structures presents significant challenges and often requires domain-specific expertise. In this work, we introduce a novel framework in which a structured loss function, parameterized by neural networks, is learned directly from output training data through Contrastive Learning, prior to addressing the supervised surrogate regression problem. As a result, the differentiable loss not only enables the learning of neural networks due to the finite dimension of the surrogate space but also allows for the prediction of new structures of the output data via a decoding strategy based on gradient descent. Numerical experiments on supervised graph prediction problems show that our approach achieves similar or even better performance than methods based on a pre-defined kernel.
Revisiting Hierarchical Text Classification: Inference and Metrics
Oct 02, 2024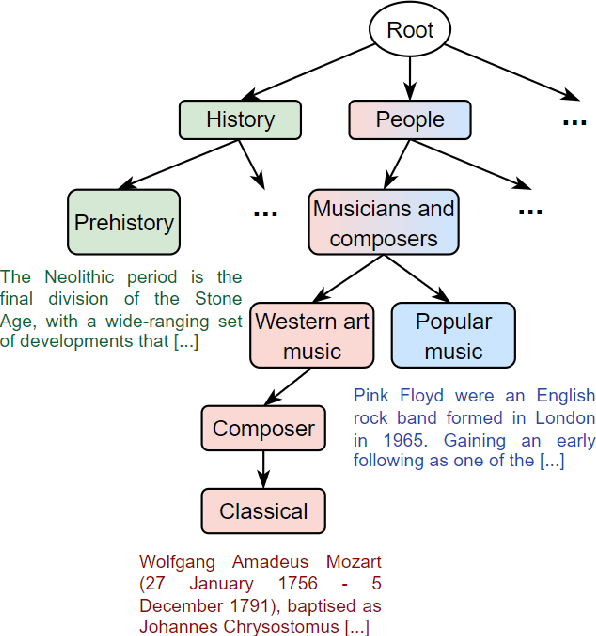
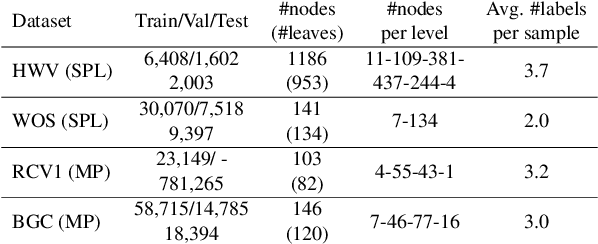
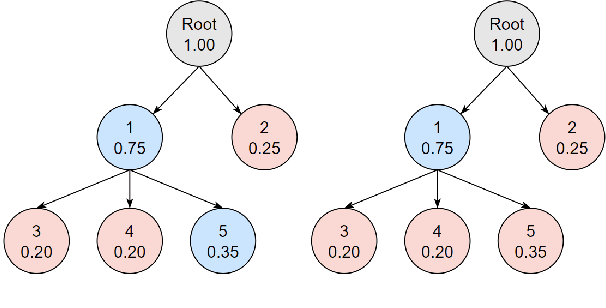
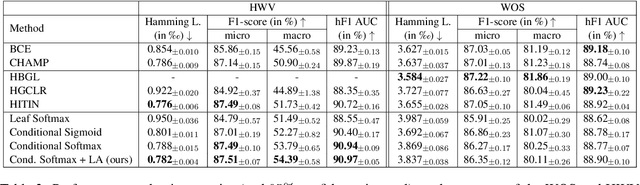
Hierarchical text classification (HTC) is the task of assigning labels to a text within a structured space organized as a hierarchy. Recent works treat HTC as a conventional multilabel classification problem, therefore evaluating it as such. We instead propose to evaluate models based on specifically designed hierarchical metrics and we demonstrate the intricacy of metric choice and prediction inference method. We introduce a new challenging dataset and we evaluate fairly, recent sophisticated models, comparing them with a range of simple but strong baselines, including a new theoretically motivated loss. Finally, we show that those baselines are very often competitive with the latest models. This highlights the importance of carefully considering the evaluation methodology when proposing new methods for HTC. Code implementation and dataset are available at \url{https://github.com/RomanPlaud/revisitingHTC}.
EmoDynamiX: Emotional Support Dialogue Strategy Prediction by Modelling MiXed Emotions and Discourse Dynamics
Aug 16, 2024
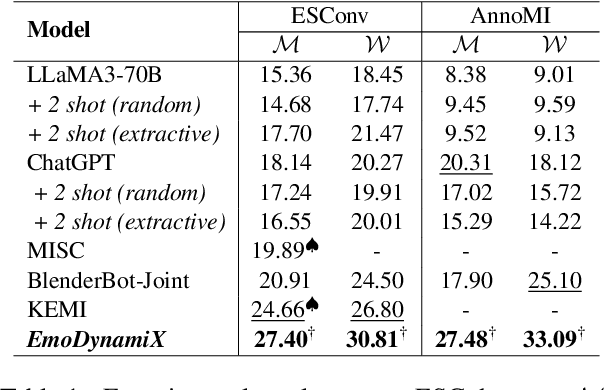
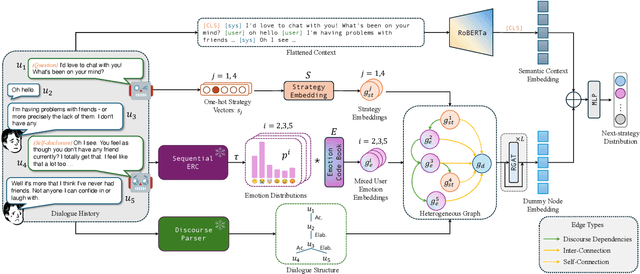
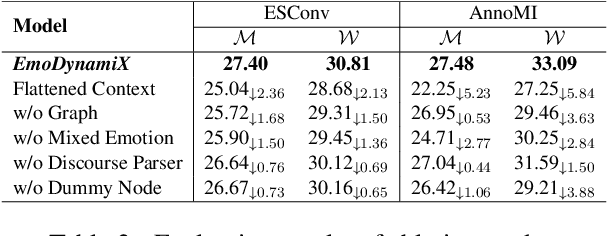
Designing emotionally intelligent conversational systems to provide comfort and advice to people experiencing distress is a compelling area of research. Previous efforts have focused on developing modular dialogue systems that treat socio-emotional strategy prediction as an auxiliary task and generate strategy-conditioned responses with customized decoders. Recently, with advancements in large language models (LLMs), end-to-end dialogue agents without explicit socio-emotional strategy prediction steps have become prevalent. However, despite their excellence in language generation, recent studies show that LLMs' inherent preference bias towards certain socio-emotional strategies hinders the delivery of high-quality emotional support. To address this challenge, we propose decoupling strategy prediction from language generation, and introduce a novel dialogue strategy predictor, EmoDynamiX, which models the discourse dynamics between user emotions and system strategies using a heterogeneous graph. Additionally, we make use of the Emotion Recognition in Conversations (ERC) task and design a flexible mixed-emotion module to capture fine-grained emotional states of the user. Experimental results on two ESC datasets show EmoDynamiX outperforms previous state-of-the-art methods with a significant margin.
End-to-end Supervised Prediction of Arbitrary-size Graphs with Partially-Masked Fused Gromov-Wasserstein Matching
Feb 23, 2024



We present a novel end-to-end deep learning-based approach for Supervised Graph Prediction (SGP). We introduce an original Optimal Transport (OT)-based loss, the Partially-Masked Fused Gromov-Wasserstein loss (PM-FGW), that allows to directly leverage graph representations such as adjacency and feature matrices. PM-FGW exhibits all the desirable properties for SGP: it is node permutation invariant, sub-differentiable and handles graphs of different sizes by comparing their padded representations as well as their masking vectors. Moreover, we present a flexible transformer-based architecture that easily adapts to different types of input data. In the experimental section, three different tasks, a novel and challenging synthetic dataset (image2graph) and two real-world tasks, image2map and fingerprint2molecule - showcase the efficiency and versatility of the approach compared to competitors.
The Impact of Word Splitting on the Semantic Content of Contextualized Word Representations
Feb 22, 2024When deriving contextualized word representations from language models, a decision needs to be made on how to obtain one for out-of-vocabulary (OOV) words that are segmented into subwords. What is the best way to represent these words with a single vector, and are these representations of worse quality than those of in-vocabulary words? We carry out an intrinsic evaluation of embeddings from different models on semantic similarity tasks involving OOV words. Our analysis reveals, among other interesting findings, that the quality of representations of words that are split is often, but not always, worse than that of the embeddings of known words. Their similarity values, however, must be interpreted with caution.
Exploiting Edge Features in Graphs with Fused Network Gromov-Wasserstein Distance
Sep 28, 2023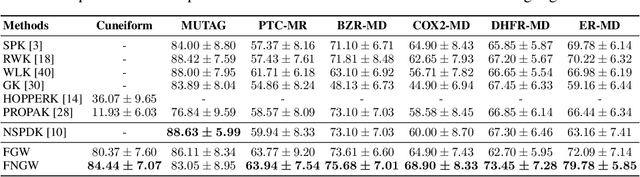
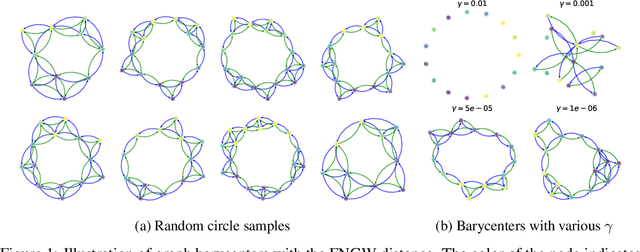
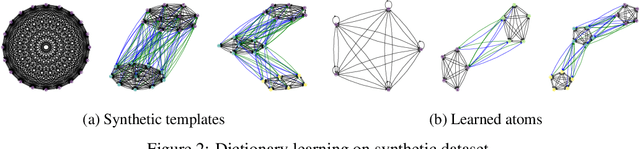
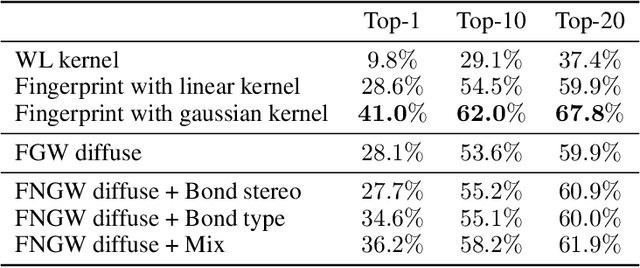
Pairwise comparison of graphs is key to many applications in Machine learning ranging from clustering, kernel-based classification/regression and more recently supervised graph prediction. Distances between graphs usually rely on informative representations of these structured objects such as bag of substructures or other graph embeddings. A recently popular solution consists in representing graphs as metric measure spaces, allowing to successfully leverage Optimal Transport, which provides meaningful distances allowing to compare them: the Gromov-Wasserstein distances. However, this family of distances overlooks edge attributes, which are essential for many structured objects. In this work, we introduce an extension of Gromov-Wasserstein distance for comparing graphs whose both nodes and edges have features. We propose novel algorithms for distance and barycenter computation. We empirically show the effectiveness of the novel distance in learning tasks where graphs occur in either input space or output space, such as classification and graph prediction.
A survey of neural models for the automatic analysis of conversation: Towards a better integration of the social sciences
Mar 31, 2022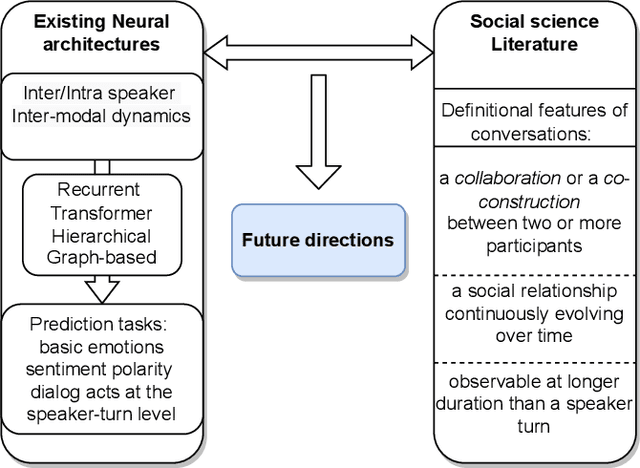
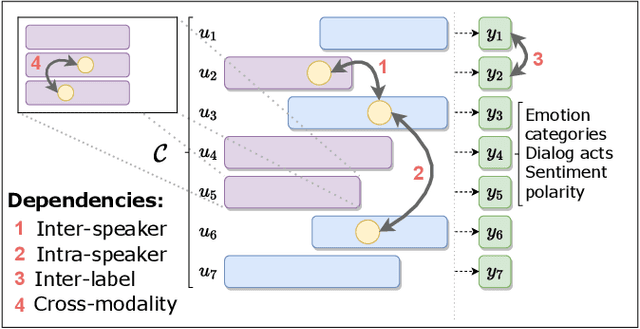
Some exciting new approaches to neural architectures for the analysis of conversation have been introduced over the past couple of years. These include neural architectures for detecting emotion, dialogue acts, and sentiment polarity. They take advantage of some of the key attributes of contemporary machine learning, such as recurrent neural networks with attention mechanisms and transformer-based approaches. However, while the architectures themselves are extremely promising, the phenomena they have been applied to to date are but a small part of what makes conversation engaging. In this paper we survey these neural architectures and what they have been applied to. On the basis of the social science literature, we then describe what we believe to be the most fundamental and definitional feature of conversation, which is its co-construction over time by two or more interlocutors. We discuss how neural architectures of the sort surveyed could profitably be applied to these more fundamental aspects of conversation, and what this buys us in terms of a better analysis of conversation and even, in the longer term, a better way of generating conversation for a conversational system.
Few-Shot Emotion Recognition in Conversation with Sequential Prototypical Networks
Sep 20, 2021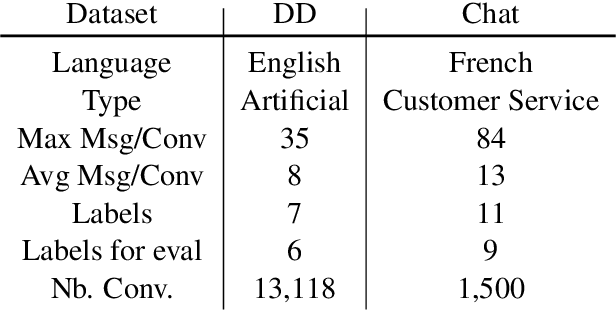
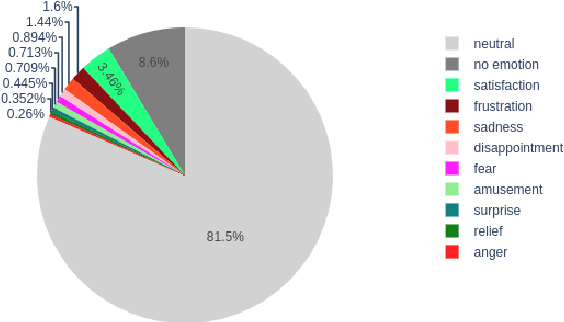
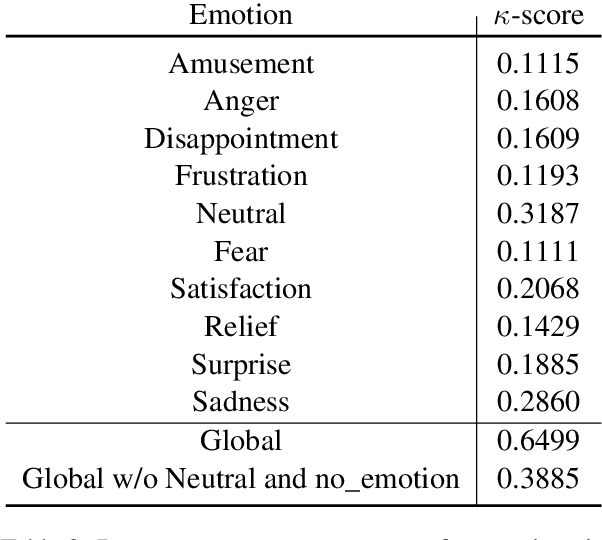
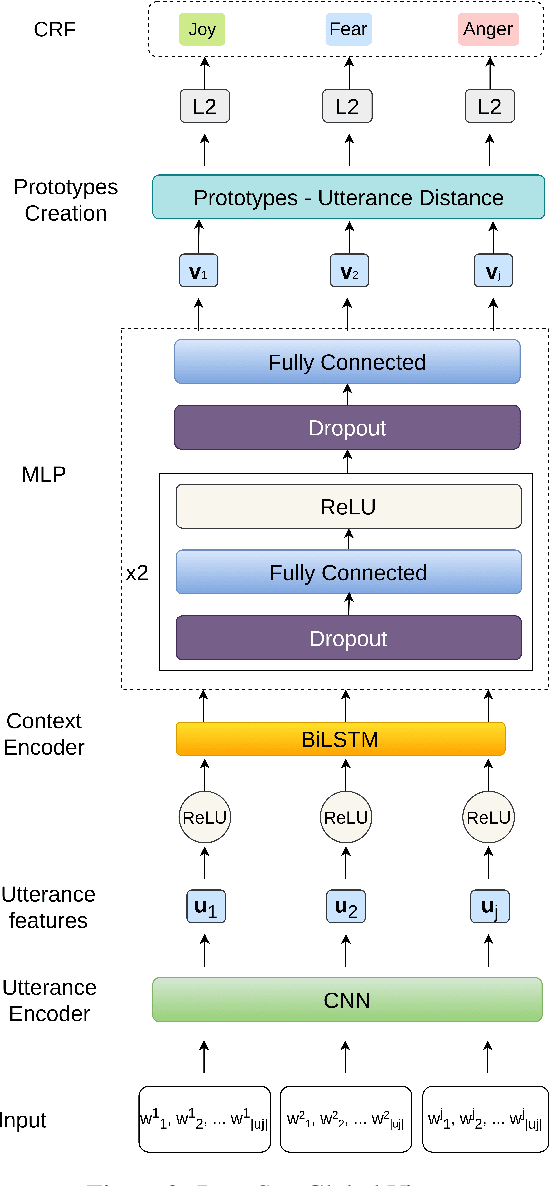
Several recent studies on dyadic human-human interactions have been done on conversations without specific business objectives. However, many companies might benefit from studies dedicated to more precise environments such as after sales services or customer satisfaction surveys. In this work, we place ourselves in the scope of a live chat customer service in which we want to detect emotions and their evolution in the conversation flow. This context leads to multiple challenges that range from exploiting restricted, small and mostly unlabeled datasets to finding and adapting methods for such context.We tackle these challenges by using Few-Shot Learning while making the hypothesis it can serve conversational emotion classification for different languages and sparse labels. We contribute by proposing a variation of Prototypical Networks for sequence labeling in conversation that we name ProtoSeq. We test this method on two datasets with different languages: daily conversations in English and customer service chat conversations in French. When applied to emotion classification in conversations, our method proved to be competitive even when compared to other ones.
Improving Multimodal fusion via Mutual Dependency Maximisation
Sep 09, 2021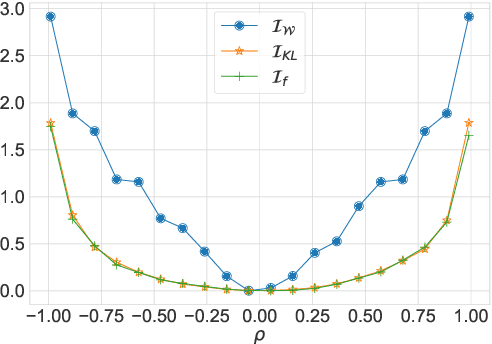
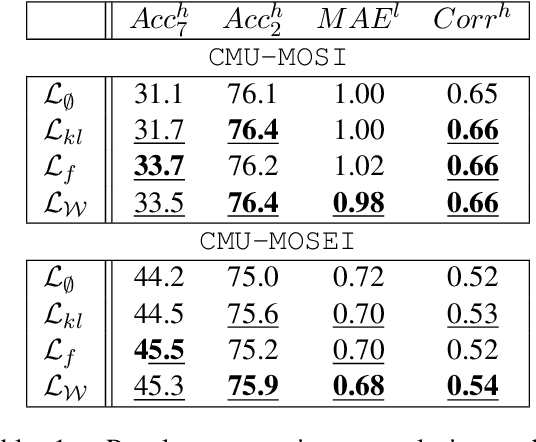
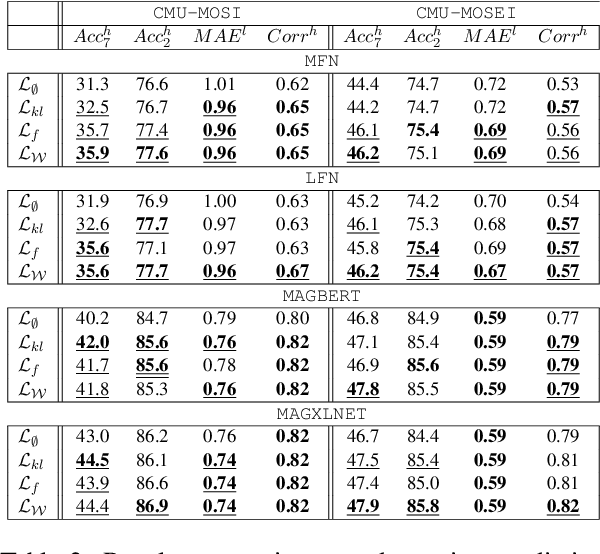
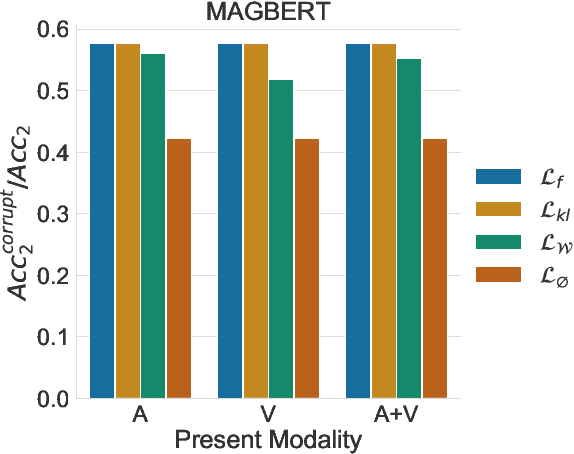
Multimodal sentiment analysis is a trending area of research, and the multimodal fusion is one of its most active topic. Acknowledging humans communicate through a variety of channels (i.e visual, acoustic, linguistic), multimodal systems aim at integrating different unimodal representations into a synthetic one. So far, a consequent effort has been made on developing complex architectures allowing the fusion of these modalities. However, such systems are mainly trained by minimising simple losses such as $L_1$ or cross-entropy. In this work, we investigate unexplored penalties and propose a set of new objectives that measure the dependency between modalities. We demonstrate that our new penalties lead to a consistent improvement (up to $4.3$ on accuracy) across a large variety of state-of-the-art models on two well-known sentiment analysis datasets: \texttt{CMU-MOSI} and \texttt{CMU-MOSEI}. Our method not only achieves a new SOTA on both datasets but also produces representations that are more robust to modality drops. Finally, a by-product of our methods includes a statistical network which can be used to interpret the high dimensional representations learnt by the model.