 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).
Improving Multimodal fusion via Mutual Dependency Maximisation
Sep 09, 2021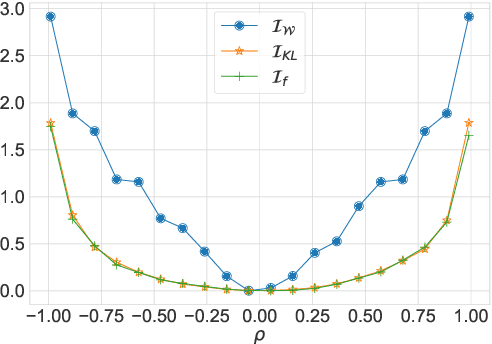
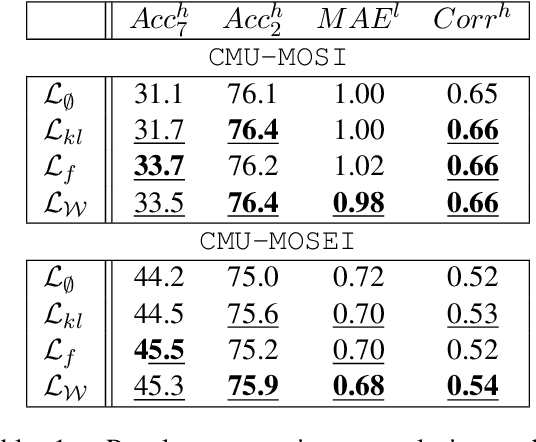
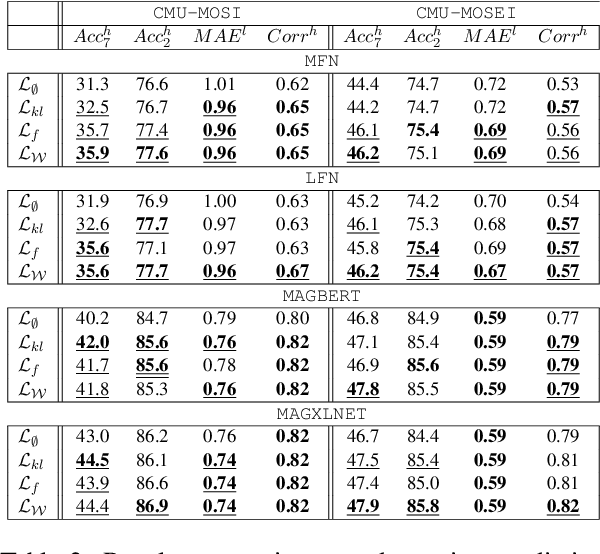
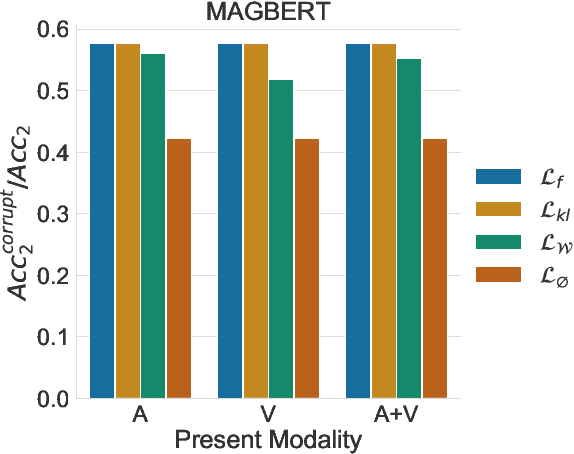
Multimodal sentiment analysis is a trending area of research, and the multimodal fusion is one of its most active topic. Acknowledging humans communicate through a variety of channels (i.e visual, acoustic, linguistic), multimodal systems aim at integrating different unimodal representations into a synthetic one. So far, a consequent effort has been made on developing complex architectures allowing the fusion of these modalities. However, such systems are mainly trained by minimising simple losses such as $L_1$ or cross-entropy. In this work, we investigate unexplored penalties and propose a set of new objectives that measure the dependency between modalities. We demonstrate that our new penalties lead to a consistent improvement (up to $4.3$ on accuracy) across a large variety of state-of-the-art models on two well-known sentiment analysis datasets: \texttt{CMU-MOSI} and \texttt{CMU-MOSEI}. Our method not only achieves a new SOTA on both datasets but also produces representations that are more robust to modality drops. Finally, a by-product of our methods includes a statistical network which can be used to interpret the high dimensional representations learnt by the model.
Code-switched inspired losses for generic spoken dialog representations
Sep 09, 2021
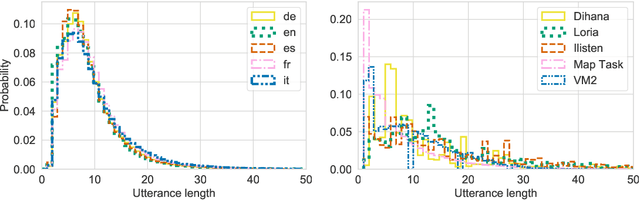
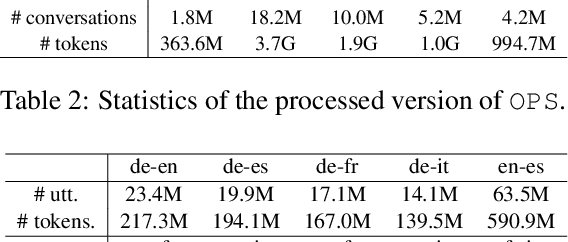
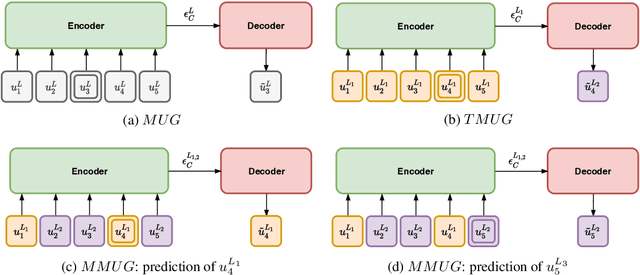
Spoken dialog systems need to be able to handle both multiple languages and multilinguality inside a conversation (\textit{e.g} in case of code-switching). In this work, we introduce new pretraining losses tailored to learn multilingual spoken dialog representations. The goal of these losses is to expose the model to code-switched language. To scale up training, we automatically build a pretraining corpus composed of multilingual conversations in five different languages (French, Italian, English, German and Spanish) from \texttt{OpenSubtitles}, a huge multilingual corpus composed of 24.3G tokens. We test the generic representations on \texttt{MIAM}, a new benchmark composed of five dialog act corpora on the same aforementioned languages as well as on two novel multilingual downstream tasks (\textit{i.e} multilingual mask utterance retrieval and multilingual inconsistency identification). Our experiments show that our new code switched-inspired losses achieve a better performance in both monolingual and multilingual settings.
Hierarchical Pre-training for Sequence Labelling in Spoken Dialog
Oct 03, 2020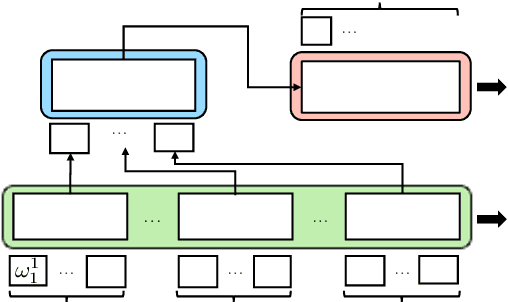
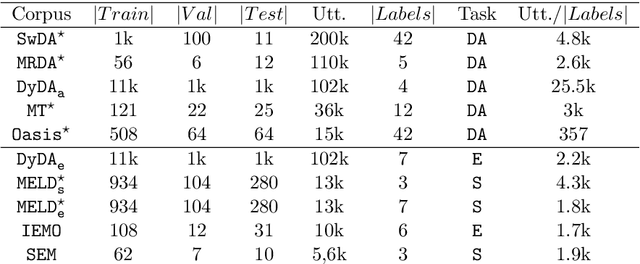
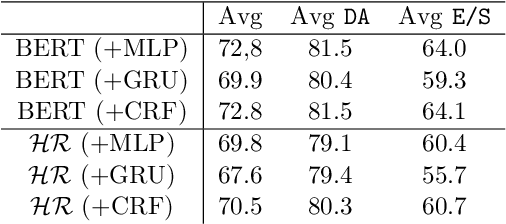
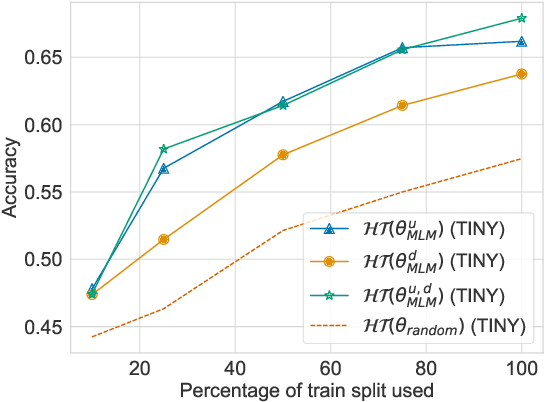
Sequence labelling tasks like Dialog Act and Emotion/Sentiment identification are a key component of spoken dialog systems. In this work, we propose a new approach to learn generic representations adapted to spoken dialog, which we evaluate on a new benchmark we call Sequence labellIng evaLuatIon benChmark fOr spoken laNguagE benchmark (\texttt{SILICONE}). \texttt{SILICONE} is model-agnostic and contains 10 different datasets of various sizes. We obtain our representations with a hierarchical encoder based on transformer architectures, for which we extend two well-known pre-training objectives. Pre-training is performed on OpenSubtitles: a large corpus of spoken dialog containing over $2.3$ billion of tokens. We demonstrate how hierarchical encoders achieve competitive results with consistently fewer parameters compared to state-of-the-art models and we show their importance for both pre-training and fine-tuning.
Guider l'attention dans les modeles de sequence a sequence pour la prediction des actes de dialogue
Feb 26, 2020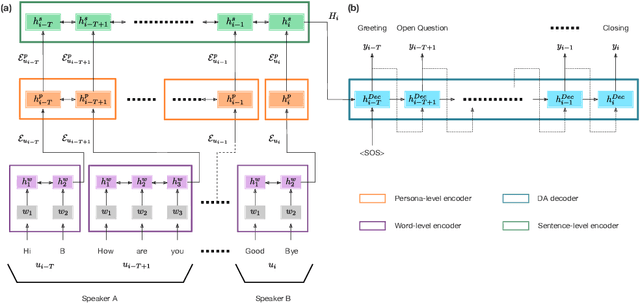
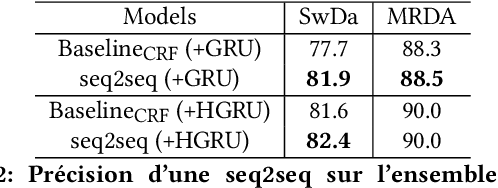
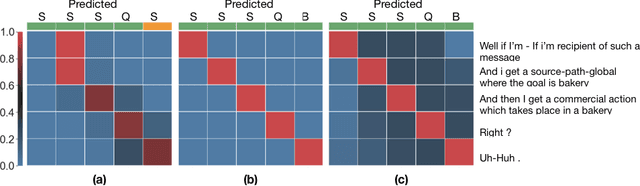

The task of predicting dialog acts (DA) based on conversational dialog is a key component in the development of conversational agents. Accurately predicting DAs requires a precise modeling of both the conversation and the global tag dependencies. We leverage seq2seq approaches widely adopted in Neural Machine Translation (NMT) to improve the modelling of tag sequentiality. Seq2seq models are known to learn complex global dependencies while currently proposed approaches using linear conditional random fields (CRF) only model local tag dependencies. In this work, we introduce a seq2seq model tailored for DA classification using: a hierarchical encoder, a novel guided attention mechanism and beam search applied to both training and inference. Compared to the state of the art our model does not require handcrafted features and is trained end-to-end. Furthermore, the proposed approach achieves an unmatched accuracy score of 85% on SwDA, and state-of-the-art accuracy score of 91.6% on MRDA.
* in French
Guiding attention in Sequence-to-sequence models for Dialogue Act prediction
Feb 26, 2020
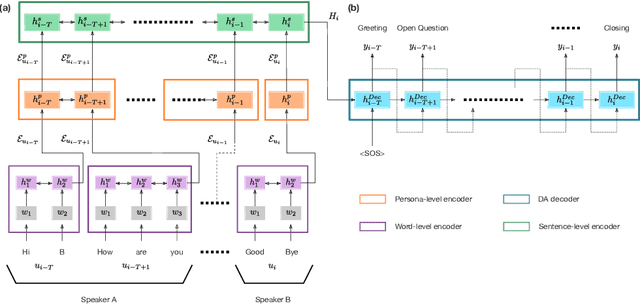
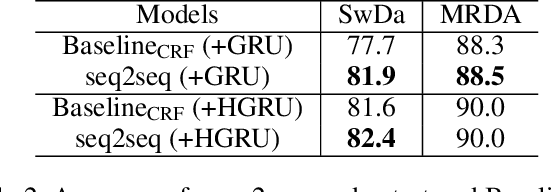

The task of predicting dialog acts (DA) based on conversational dialog is a key component in the development of conversational agents. Accurately predicting DAs requires a precise modeling of both the conversation and the global tag dependencies. We leverage seq2seq approaches widely adopted in Neural Machine Translation (NMT) to improve the modelling of tag sequentiality. Seq2seq models are known to learn complex global dependencies while currently proposed approaches using linear conditional random fields (CRF) only model local tag dependencies. In this work, we introduce a seq2seq model tailored for DA classification using: a hierarchical encoder, a novel guided attention mechanism and beam search applied to both training and inference. Compared to the state of the art our model does not require handcrafted features and is trained end-to-end. Furthermore, the proposed approach achieves an unmatched accuracy score of 85% on SwDA, and state-of-the-art accuracy score of 91.6% on MRDA.