 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).
CANDLE: Decomposing Conditional and Conjunctive Queries for Task-Oriented Dialogue Systems
Jul 08, 2021
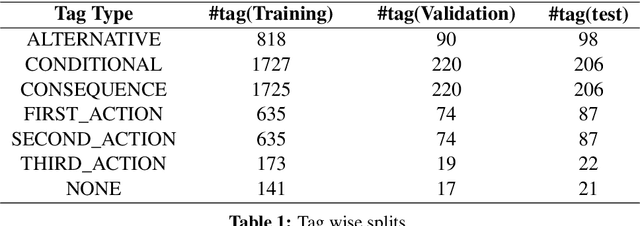


Domain-specific dialogue systems generally determine user intents by relying on sentence-level classifiers which mainly focus on single action sentences. Such classifiers are not designed to effectively handle complex queries composed of conditional and sequential clauses that represent multiple actions. We attempt to decompose such queries into smaller single-action sub-queries that are reasonable for intent classifiers to understand in a dialogue pipeline. We release CANDLE (Conditional & AND type Expressions), a dataset consisting of 3124 utterances manually tagged with conditional and sequential labels and demonstrates this decomposition by training two baseline taggers.