 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning-Guided Claim Normalization for Noisy Multilingual Social Media Posts
Nov 07, 2025We address claim normalization for multilingual misinformation detection - transforming noisy social media posts into clear, verifiable statements across 20 languages. The key contribution demonstrates how systematic decomposition of posts using Who, What, Where, When, Why and How questions enables robust cross-lingual transfer despite training exclusively on English data. Our methodology incorporates finetuning Qwen3-14B using LoRA with the provided dataset after intra-post deduplication, token-level recall filtering for semantic alignment and retrieval-augmented few-shot learning with contextual examples during inference. Our system achieves METEOR scores ranging from 41.16 (English) to 15.21 (Marathi), securing third rank on the English leaderboard and fourth rank for Dutch and Punjabi. The approach shows 41.3% relative improvement in METEOR over baseline configurations and substantial gains over existing methods. Results demonstrate effective cross-lingual generalization for Romance and Germanic languages while maintaining semantic coherence across diverse linguistic structures.
Fine Tuning without Catastrophic Forgetting via Selective Low Rank Adaptation
Jan 26, 2025Adapting deep learning models to new domains often requires computationally intensive retraining and risks catastrophic forgetting. While fine-tuning enables domain-specific adaptation, it can reduce robustness to distribution shifts, impacting out-of-distribution (OOD) performance. Pre-trained zero-shot models like CLIP offer strong generalization but may suffer degraded robustness after fine-tuning. Building on Task Adaptive Parameter Sharing (TAPS), we propose a simple yet effective extension as a parameter-efficient fine-tuning (PEFT) method, using an indicator function to selectively activate Low-Rank Adaptation (LoRA) blocks. Our approach minimizes knowledge loss, retains its generalization strengths under domain shifts, and significantly reduces computational costs compared to traditional fine-tuning. We demonstrate that effective fine-tuning can be achieved with as few as 5\% of active blocks, substantially improving efficiency. Evaluations on pre-trained models such as CLIP and DINO-ViT demonstrate our method's broad applicability and effectiveness in maintaining performance and knowledge retention.
VLM-KD: Knowledge Distillation from VLM for Long-Tail Visual Recognition
Aug 29, 2024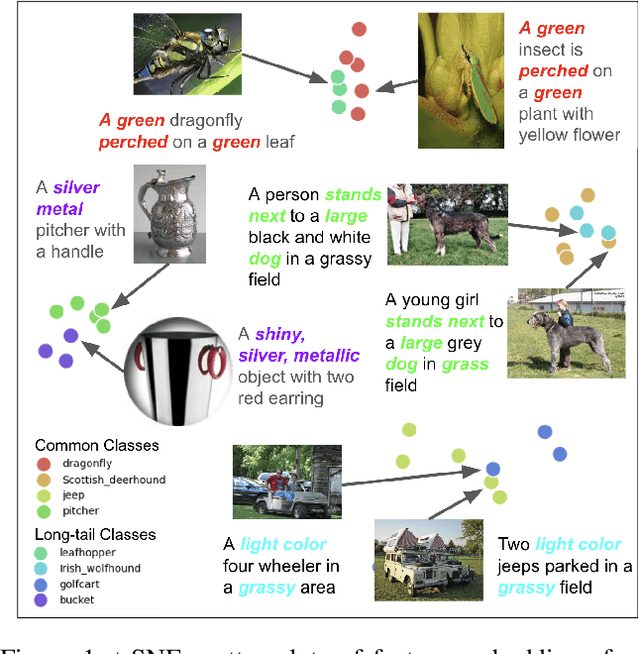
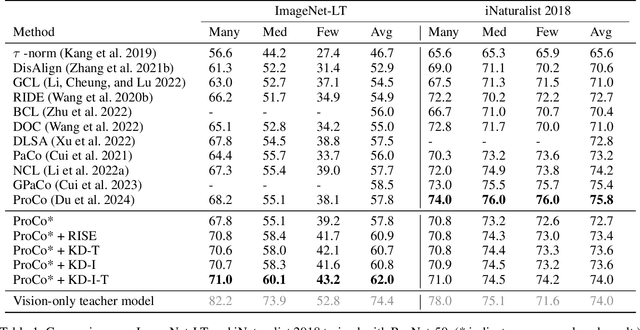
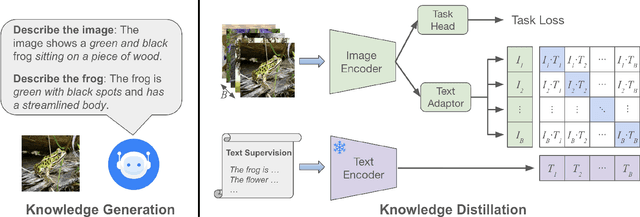
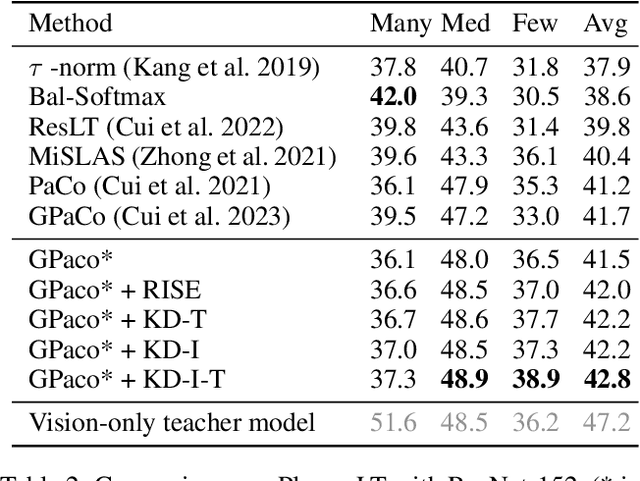
For visual recognition, knowledge distillation typically involves transferring knowledge from a large, well-trained teacher model to a smaller student model. In this paper, we introduce an effective method to distill knowledge from an off-the-shelf vision-language model (VLM), demonstrating that it provides novel supervision in addition to those from a conventional vision-only teacher model. Our key technical contribution is the development of a framework that generates novel text supervision and distills free-form text into a vision encoder. We showcase the effectiveness of our approach, termed VLM-KD, across various benchmark datasets, showing that it surpasses several state-of-the-art long-tail visual classifiers. To our knowledge, this work is the first to utilize knowledge distillation with text supervision generated by an off-the-shelf VLM and apply it to vanilla randomly initialized vision encoders.
InVi: Object Insertion In Videos Using Off-the-Shelf Diffusion Models
Jul 15, 2024

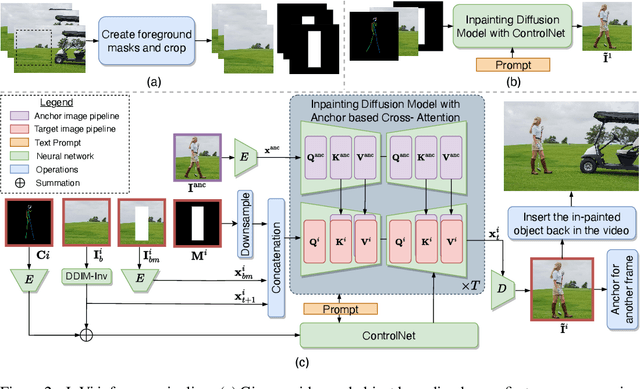

We introduce InVi, an approach for inserting or replacing objects within videos (referred to as inpainting) using off-the-shelf, text-to-image latent diffusion models. InVi targets controlled manipulation of objects and blending them seamlessly into a background video unlike existing video editing methods that focus on comprehensive re-styling or entire scene alterations. To achieve this goal, we tackle two key challenges. Firstly, for high quality control and blending, we employ a two-step process involving inpainting and matching. This process begins with inserting the object into a single frame using a ControlNet-based inpainting diffusion model, and then generating subsequent frames conditioned on features from an inpainted frame as an anchor to minimize the domain gap between the background and the object. Secondly, to ensure temporal coherence, we replace the diffusion model's self-attention layers with extended-attention layers. The anchor frame features serve as the keys and values for these layers, enhancing consistency across frames. Our approach removes the need for video-specific fine-tuning, presenting an efficient and adaptable solution. Experimental results demonstrate that InVi achieves realistic object insertion with consistent blending and coherence across frames, outperforming existing methods.
GenMM: Geometrically and Temporally Consistent Multimodal Data Generation for Video and LiDAR
Jun 15, 2024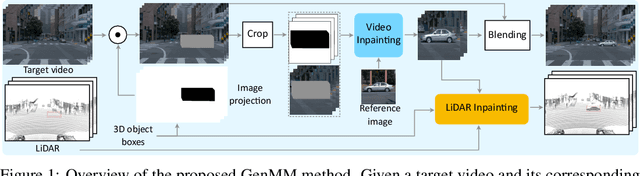
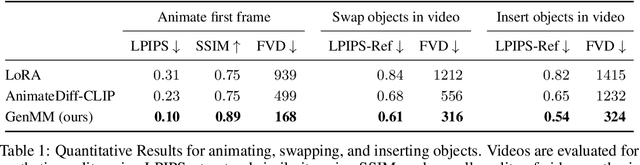
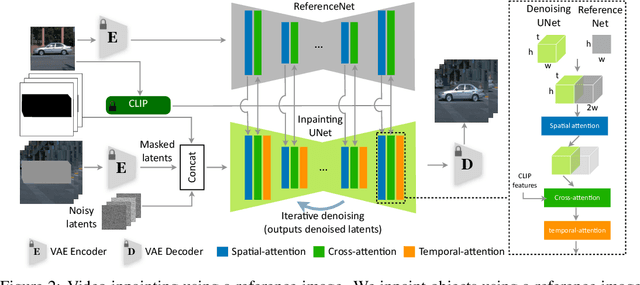

Multimodal synthetic data generation is crucial in domains such as autonomous driving, robotics, augmented/virtual reality, and retail. We propose a novel approach, GenMM, for jointly editing RGB videos and LiDAR scans by inserting temporally and geometrically consistent 3D objects. Our method uses a reference image and 3D bounding boxes to seamlessly insert and blend new objects into target videos. We inpaint the 2D Regions of Interest (consistent with 3D boxes) using a diffusion-based video inpainting model. We then compute semantic boundaries of the object and estimate it's surface depth using state-of-the-art semantic segmentation and monocular depth estimation techniques. Subsequently, we employ a geometry-based optimization algorithm to recover the 3D shape of the object's surface, ensuring it fits precisely within the 3D bounding box. Finally, LiDAR rays intersecting with the new object surface are updated to reflect consistent depths with its geometry. Our experiments demonstrate the effectiveness of GenMM in inserting various 3D objects across video and LiDAR modalities.
SHIFT3D: Synthesizing Hard Inputs For Tricking 3D Detectors
Sep 11, 2023



We present SHIFT3D, a differentiable pipeline for generating 3D shapes that are structurally plausible yet challenging to 3D object detectors. In safety-critical applications like autonomous driving, discovering such novel challenging objects can offer insight into unknown vulnerabilities of 3D detectors. By representing objects with a signed distanced function (SDF), we show that gradient error signals allow us to smoothly deform the shape or pose of a 3D object in order to confuse a downstream 3D detector. Importantly, the objects generated by SHIFT3D physically differ from the baseline object yet retain a semantically recognizable shape. Our approach provides interpretable failure modes for modern 3D object detectors, and can aid in preemptive discovery of potential safety risks within 3D perception systems before these risks become critical failures.
NOVA: NOvel View Augmentation for Neural Composition of Dynamic Objects
Aug 24, 2023We propose a novel-view augmentation (NOVA) strategy to train NeRFs for photo-realistic 3D composition of dynamic objects in a static scene. Compared to prior work, our framework significantly reduces blending artifacts when inserting multiple dynamic objects into a 3D scene at novel views and times; achieves comparable PSNR without the need for additional ground truth modalities like optical flow; and overall provides ease, flexibility, and scalability in neural composition. Our codebase is on GitHub.
I see what you hear: a vision-inspired method to localize words
Oct 24, 2022This paper explores the possibility of using visual object detection techniques for word localization in speech data. Object detection has been thoroughly studied in the contemporary literature for visual data. Noting that an audio can be interpreted as a 1-dimensional image, object localization techniques can be fundamentally useful for word localization. Building upon this idea, we propose a lightweight solution for word detection and localization. We use bounding box regression for word localization, which enables our model to detect the occurrence, offset, and duration of keywords in a given audio stream. We experiment with LibriSpeech and train a model to localize 1000 words. Compared to existing work, our method reduces model size by 94%, and improves the F1 score by 6.5\%.
Synt++: Utilizing Imperfect Synthetic Data to Improve Speech Recognition
Oct 21, 2021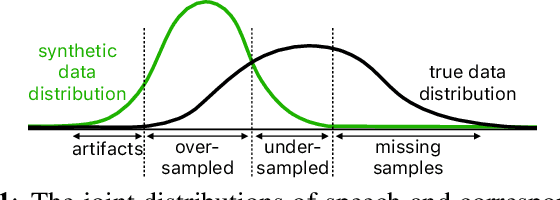
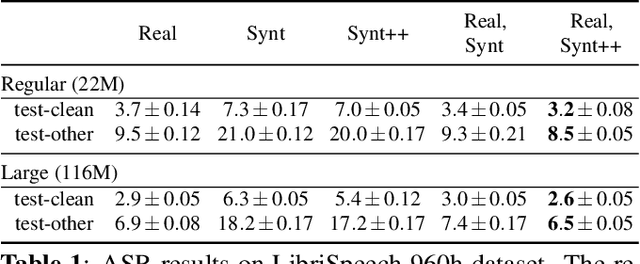
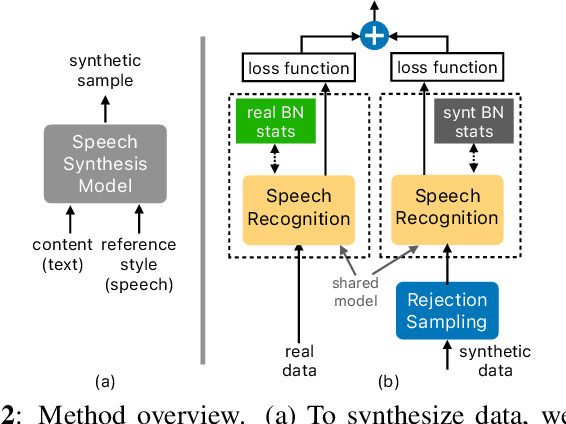
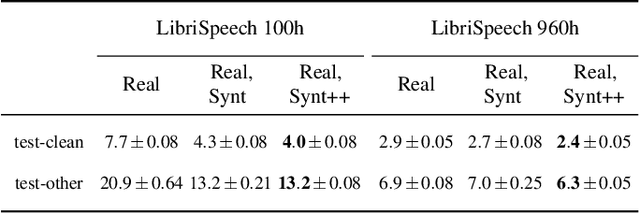
With recent advances in speech synthesis, synthetic data is becoming a viable alternative to real data for training speech recognition models. However, machine learning with synthetic data is not trivial due to the gap between the synthetic and the real data distributions. Synthetic datasets may contain artifacts that do not exist in real data such as structured noise, content errors, or unrealistic speaking styles. Moreover, the synthesis process may introduce a bias due to uneven sampling of the data manifold. We propose two novel techniques during training to mitigate the problems due to the distribution gap: (i) a rejection sampling algorithm and (ii) using separate batch normalization statistics for the real and the synthetic samples. We show that these methods significantly improve the training of speech recognition models using synthetic data. We evaluate the proposed approach on keyword detection and Automatic Speech Recognition (ASR) tasks, and observe up to 18% and 13% relative error reduction, respectively, compared to naively using the synthetic data.
Style Equalization: Unsupervised Learning of Controllable Generative Sequence Models
Oct 06, 2021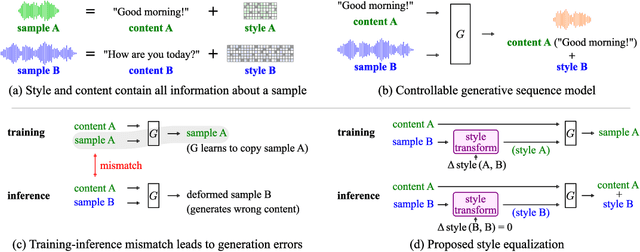
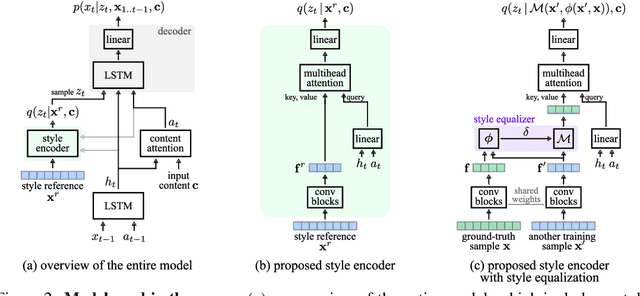
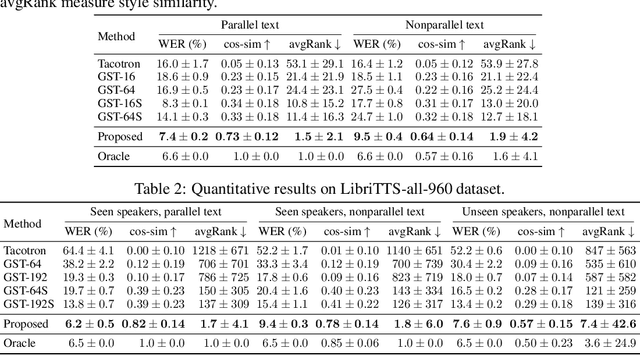

Controllable generative sequence models with the capability to extract and replicate the style of specific examples enable many applications, including narrating audiobooks in different voices, auto-completing and auto-correcting written handwriting, and generating missing training samples for downstream recognition tasks. However, typical training algorithms for these controllable sequence generative models suffer from the training-inference mismatch, where the same sample is used as content and style input during training but different samples are given during inference. In this paper, we tackle the training-inference mismatch encountered during unsupervised learning of controllable generative sequence models. By introducing a style transformation module that we call style equalization, we enable training using different content and style samples and thereby mitigate the training-inference mismatch. To demonstrate its generality, we applied style equalization to text-to-speech and text-to-handwriting synthesis on three datasets. Our models achieve state-of-the-art style replication with a similar mean style opinion score as the real data. Moreover, the proposed method enables style interpolation between sequences and generates novel styles.