 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Composition Diffusion Model for Closed-loop Traffic Generation
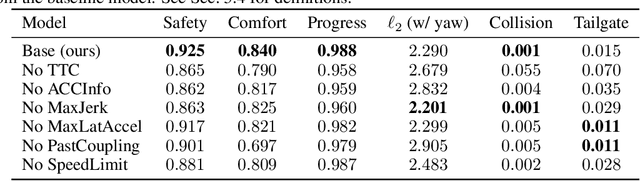
Dec 23, 2024Simulation is critical for safety evaluation in autonomous driving, particularly in capturing complex interactive behaviors. However, generating realistic and controllable traffic scenarios in long-tail situations remains a significant challenge. Existing generative models suffer from the conflicting objective between user-defined controllability and realism constraints, which is amplified in safety-critical contexts. In this work, we introduce the Causal Compositional Diffusion Model (CCDiff), a structure-guided diffusion framework to address these challenges. We first formulate the learning of controllable and realistic closed-loop simulation as a constrained optimization problem. Then, CCDiff maximizes controllability while adhering to realism by automatically identifying and injecting causal structures directly into the diffusion process, providing structured guidance to enhance both realism and controllability. Through rigorous evaluations on benchmark datasets and in a closed-loop simulator, CCDiff demonstrates substantial gains over state-of-the-art approaches in generating realistic and user-preferred trajectories. Our results show CCDiff's effectiveness in extracting and leveraging causal structures, showing improved closed-loop performance based on key metrics such as collision rate, off-road rate, FDE, and comfort.
Flash3D: Super-scaling Point Transformers through Joint Hardware-Geometry Locality
Dec 21, 2024Recent efforts recognize the power of scale in 3D learning (e.g. PTv3) and attention mechanisms (e.g. FlashAttention). However, current point cloud backbones fail to holistically unify geometric locality, attention mechanisms, and GPU architectures in one view. In this paper, we introduce Flash3D Transformer, which aligns geometric locality and GPU tiling through a principled locality mechanism based on Perfect Spatial Hashing (PSH). The common alignment with GPU tiling naturally fuses our PSH locality mechanism with FlashAttention at negligible extra cost. This mechanism affords flexible design choices throughout the backbone that result in superior downstream task results. Flash3D outperforms state-of-the-art PTv3 results on benchmark datasets, delivering a 2.25x speed increase and 2.4x memory efficiency boost. This efficiency enables scaling to wider attention scopes and larger models without additional overhead. Such scaling allows Flash3D to achieve even higher task accuracies than PTv3 under the same compute budget.
DriveGPT: Scaling Autoregressive Behavior Models for Driving
Dec 19, 2024



We present DriveGPT, a scalable behavior model for autonomous driving. We model driving as a sequential decision making task, and learn a transformer model to predict future agent states as tokens in an autoregressive fashion. We scale up our model parameters and training data by multiple orders of magnitude, enabling us to explore the scaling properties in terms of dataset size, model parameters, and compute. We evaluate DriveGPT across different scales in a planning task, through both quantitative metrics and qualitative examples including closed-loop driving in complex real-world scenarios. In a separate prediction task, DriveGPT outperforms a state-of-the-art baseline and exhibits improved performance by pretraining on a large-scale dataset, further validating the benefits of data scaling.
VLM-AD: End-to-End Autonomous Driving through Vision-Language Model Supervision
Dec 19, 2024



Human drivers rely on commonsense reasoning to navigate diverse and dynamic real-world scenarios. Existing end-to-end (E2E) autonomous driving (AD) models are typically optimized to mimic driving patterns observed in data, without capturing the underlying reasoning processes. This limitation constrains their ability to handle challenging driving scenarios. To close this gap, we propose VLM-AD, a method that leverages vision-language models (VLMs) as teachers to enhance training by providing additional supervision that incorporates unstructured reasoning information and structured action labels. Such supervision enhances the model's ability to learn richer feature representations that capture the rationale behind driving patterns. Importantly, our method does not require a VLM during inference, making it practical for real-time deployment. When integrated with state-of-the-art methods, VLM-AD achieves significant improvements in planning accuracy and reduced collision rates on the nuScenes dataset.
VLM-KD: Knowledge Distillation from VLM for Long-Tail Visual Recognition
Aug 29, 2024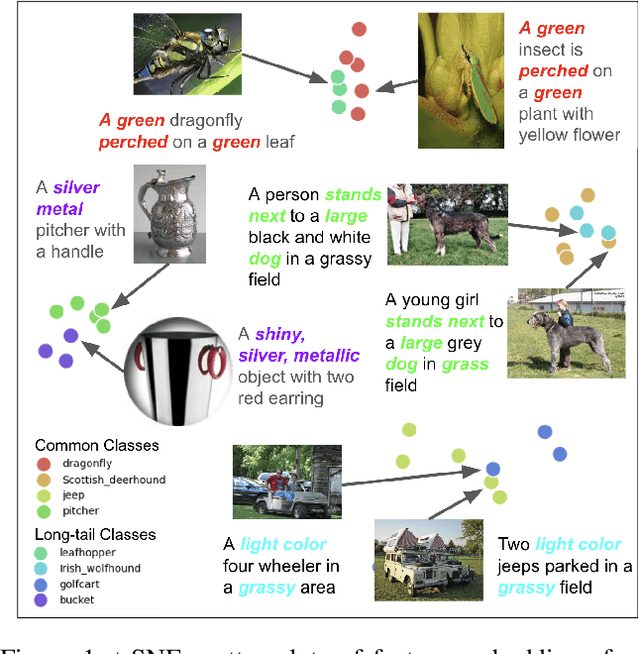
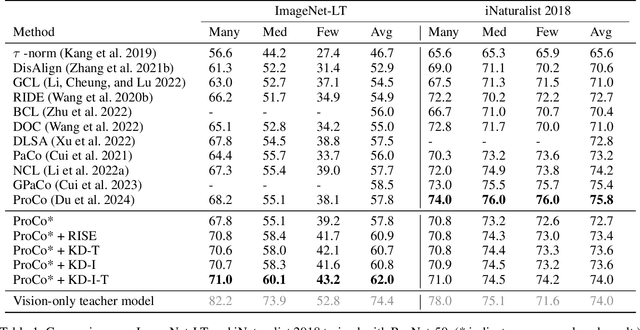
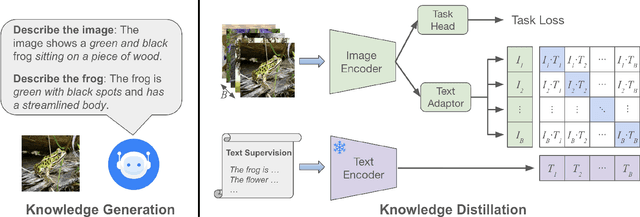
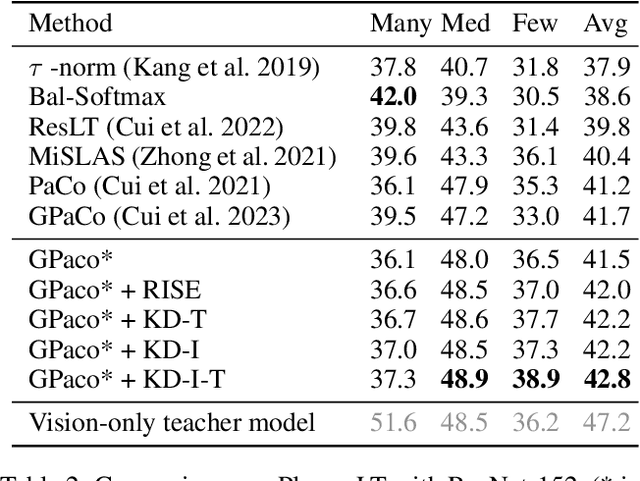
For visual recognition, knowledge distillation typically involves transferring knowledge from a large, well-trained teacher model to a smaller student model. In this paper, we introduce an effective method to distill knowledge from an off-the-shelf vision-language model (VLM), demonstrating that it provides novel supervision in addition to those from a conventional vision-only teacher model. Our key technical contribution is the development of a framework that generates novel text supervision and distills free-form text into a vision encoder. We showcase the effectiveness of our approach, termed VLM-KD, across various benchmark datasets, showing that it surpasses several state-of-the-art long-tail visual classifiers. To our knowledge, this work is the first to utilize knowledge distillation with text supervision generated by an off-the-shelf VLM and apply it to vanilla randomly initialized vision encoders.
Cohere3D: Exploiting Temporal Coherence for Unsupervised Representation Learning of Vision-based Autonomous Driving
Feb 23, 2024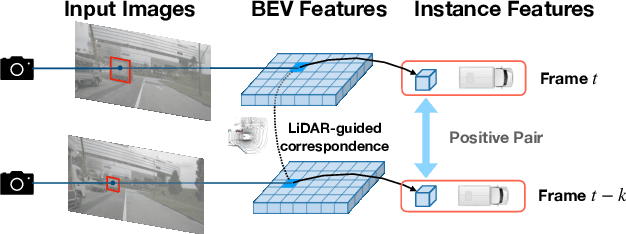
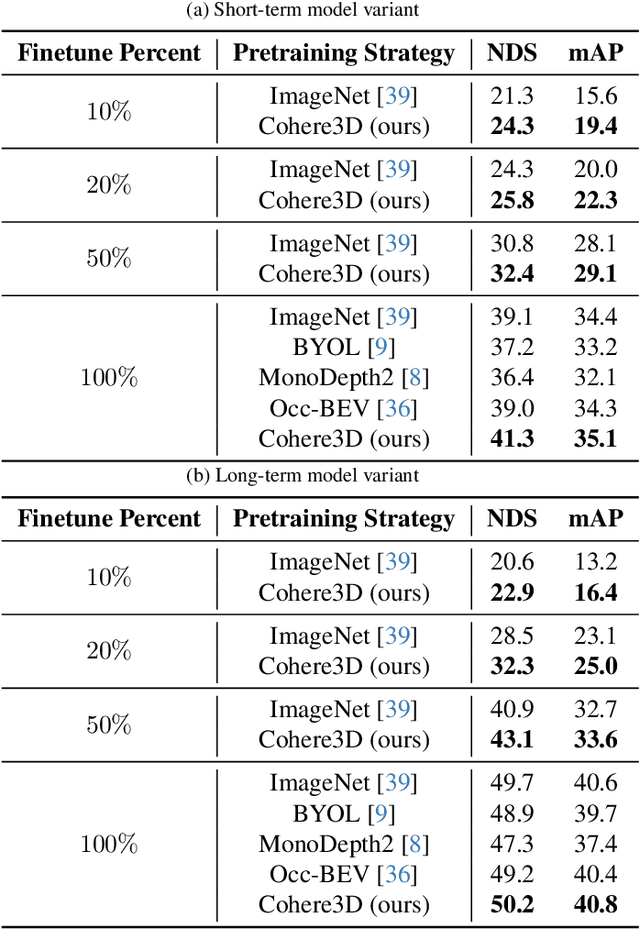
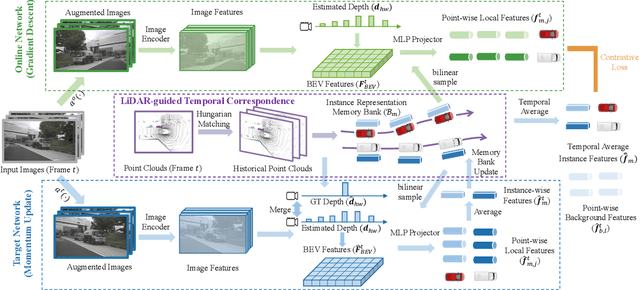

Due to the lack of depth cues in images, multi-frame inputs are important for the success of vision-based perception, prediction, and planning in autonomous driving. Observations from different angles enable the recovery of 3D object states from 2D image inputs if we can identify the same instance in different input frames. However, the dynamic nature of autonomous driving scenes leads to significant changes in the appearance and shape of each instance captured by the camera at different time steps. To this end, we propose a novel contrastive learning algorithm, Cohere3D, to learn coherent instance representations in a long-term input sequence robust to the change in distance and perspective. The learned representation aids in instance-level correspondence across multiple input frames in downstream tasks. In the pretraining stage, the raw point clouds from LiDAR sensors are utilized to construct the long-term temporal correspondence for each instance, which serves as guidance for the extraction of instance-level representation from the vision-based bird's eye-view (BEV) feature map. Cohere3D encourages a consistent representation for the same instance at different frames but distinguishes between representations of different instances. We evaluate our algorithm by finetuning the pretrained model on various downstream perception, prediction, and planning tasks. Results show a notable improvement in both data efficiency and task performance.
Driving in Real Life with Inverse Reinforcement Learning
Jun 07, 2022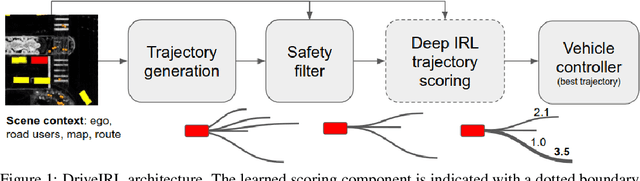


In this paper, we introduce the first learning-based planner to drive a car in dense, urban traffic using Inverse Reinforcement Learning (IRL). Our planner, DriveIRL, generates a diverse set of trajectory proposals, filters these trajectories with a lightweight and interpretable safety filter, and then uses a learned model to score each remaining trajectory. The best trajectory is then tracked by the low-level controller of our self-driving vehicle. We train our trajectory scoring model on a 500+ hour real-world dataset of expert driving demonstrations in Las Vegas within the maximum entropy IRL framework. DriveIRL's benefits include: a simple design due to only learning the trajectory scoring function, relatively interpretable features, and strong real-world performance. We validated DriveIRL on the Las Vegas Strip and demonstrated fully autonomous driving in heavy traffic, including scenarios involving cut-ins, abrupt braking by the lead vehicle, and hotel pickup/dropoff zones. Our dataset will be made public to help further research in this area.
Multimodal Trajectory Prediction Conditioned on Lane-Graph Traversals
Jun 28, 2021



Accurately predicting the future motion of surrounding vehicles requires reasoning about the inherent uncertainty in goals and driving behavior. This uncertainty can be loosely decoupled into lateral (e.g., keeping lane, turning) and longitudinal (e.g., accelerating, braking). We present a novel method that combines learned discrete policy rollouts with a focused decoder on subsets of the lane graph. The policy rollouts explore different goals given our current observations, ensuring that the model captures lateral variability. The longitudinal variability is captured by our novel latent variable model decoder that is conditioned on various subsets of the lane graph. Our model achieves state-of-the-art performance on the nuScenes motion prediction dataset, and qualitatively demonstrates excellent scene compliance. Detailed ablations highlight the importance of both the policy rollouts and the decoder architecture.
Motion Prediction using Trajectory Sets and Self-Driving Domain Knowledge
Jun 08, 2020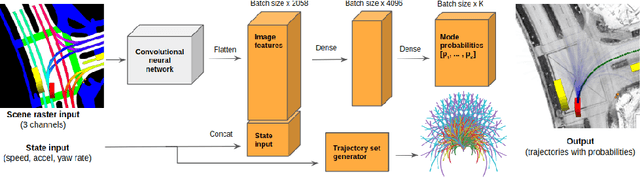

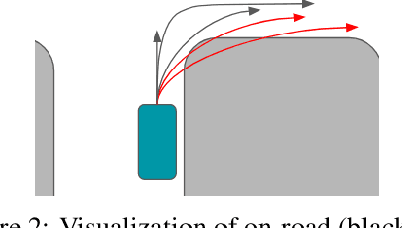

Predicting the future motion of vehicles has been studied using various techniques, including stochastic policies, generative models, and regression. Recent work has shown that classification over a trajectory set, which approximates possible motions, achieves state-of-the-art performance and avoids issues like mode collapse. However, map information and the physical relationships between nearby trajectories is not fully exploited in this formulation. We build on classification-based approaches to motion prediction by adding an auxiliary loss that penalizes off-road predictions. This auxiliary loss can easily be \emph{pretrained} using only map information (e.g., off-road area), which significantly improves performance on small datasets. We also investigate weighted cross-entropy losses to capture spatial-temporal relationships among trajectories. Our final contribution is a detailed comparison of classification and ordinal regression on two public self-driving datasets.
CoverNet: Multimodal Behavior Prediction using Trajectory Sets
Nov 23, 2019



We present CoverNet, a new method for multimodal, probabilistic trajectory prediction in urban driving scenarios. Previous work has employed a variety of methods, including multimodal regression, occupancy maps, and 1-step stochastic policies. We instead frame the trajectory prediction problem as classification over a diverse set of trajectories. The size of this set remains manageable, due to the fact that there are a limited number of distinct actions that can be taken over a reasonable prediction horizon. We structure the trajectory set to a) ensure a desired level of coverage of the state space, and b) eliminate physically impossible trajectories. By dynamically generating trajectory sets based on the agent's current state, we can further improve the efficiency of our method. We demonstrate our approach on public, real-world self-driving datasets, and show that it outperforms state-of-the-art methods.