 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuQuant++: Fine-grained Rotation Enhances Microscaling FP4 Quantization
Apr 21, 2026The MXFP4 microscaling format, which partitions tensors into blocks of 32 elements sharing an E8M0 scaling factor, has emerged as a promising substrate for efficient LLM inference, backed by native hardware support on NVIDIA Blackwell Tensor Cores. However, activation outliers pose a unique challenge under this format: a single outlier inflates the shared block scale, compressing the effective dynamic range of the remaining elements and causing significant quantization error. Existing rotation-based remedies, including randomized Hadamard and learnable rotations, are data-agnostic and therefore unable to specifically target the channels where outliers concentrate. We propose DuQuant++, which adapts the outlier-aware fine-grained rotation of DuQuant to the MXFP4 format by aligning the rotation block size with the microscaling group size (B{=}32). Because each MXFP4 group possesses an independent scaling factor, the cross-block variance issue that necessitates dual rotations and a zigzag permutation in the original DuQuant becomes irrelevant, enabling DuQuant++ to replace the entire pipeline with a single outlier-aware rotation, which halves the online rotation cost while simultaneously smoothing the weight distribution. Extensive experiments on the LLaMA-3 family under MXFP4 W4A4 quantization show that DuQuant++ consistently achieves state-of-the-art performance. Our code is available at https://github.com/Hsu1023/DuQuant-v2.
Rethinking Code Similarity for Automated Algorithm Design with LLMs
Mar 03, 2026The rise of Large Language Model-based Automated Algorithm Design (LLM-AAD) has transformed algorithm development by autonomously generating code implementations of expert-level algorithms. Unlike traditional expert-driven algorithm development, in the LLM-AAD paradigm, the main design principle behind an algorithm is often implicitly embedded in the generated code. Therefore, assessing algorithmic similarity directly from code, distinguishing genuine algorithmic innovation from mere syntactic variation, becomes essential. While various code similarity metrics exist, they fail to capture algorithmic similarity, as they focus on surface-level syntax or output equivalence rather than the underlying algorithmic logic. We propose BehaveSim, a novel method to measure algorithmic similarity through the lens of problem-solving behavior as a sequence of intermediate solutions produced during execution, dubbed as problem-solving trajectories (PSTrajs). By quantifying the alignment between PSTrajs using dynamic time warping (DTW), BehaveSim distinguishes algorithms with divergent logic despite syntactic or output-level similarities. We demonstrate its utility in two key applications: (i) Enhancing LLM-AAD: Integrating BehaveSim into existing LLM-AAD frameworks (e.g., FunSearch, EoH) promotes behavioral diversity, significantly improving performance on three AAD tasks. (ii) Algorithm analysis: BehaveSim clusters generated algorithms by behavior, enabling systematic analysis of problem-solving strategies--a crucial tool for the growing ecosystem of AI-generated algorithms. Data and code of this work are open-sourced at https://github.com/RayZhhh/behavesim.
Survey on Neural Routing Solvers
Feb 25, 2026Neural routing solvers (NRSs) that leverage deep learning to tackle vehicle routing problems have demonstrated notable potential for practical applications. By learning implicit heuristic rules from data, NRSs replace the handcrafted counterparts in classic heuristic frameworks, thereby reducing reliance on costly manual design and trial-and-error adjustments. This survey makes two main contributions: (1) The heuristic nature of NRSs is highlighted, and existing NRSs are reviewed from the perspective of heuristics. A hierarchical taxonomy based on heuristic principles is further introduced. (2) A generalization-focused evaluation pipeline is proposed to address limitations of the conventional pipeline. Comparative benchmarking of representative NRSs across both pipelines uncovers a series of previously unreported gaps in current research.
Evolving Interdependent Operators with Large Language Models for Multi-Objective Combinatorial Optimization
Jan 25, 2026Neighborhood search operators are critical to the performance of Multi-Objective Evolutionary Algorithms (MOEAs) and rely heavily on expert design. Although recent LLM-based Automated Heuristic Design (AHD) methods have made notable progress, they primarily optimize individual heuristics or components independently, lacking explicit exploration and exploitation of dynamic coupling relationships between multiple operators. In this paper, multi-operator optimization in MOEAs is formulated as a Markov decision process, enabling the improvement of interdependent operators through sequential decision-making. To address this, we propose the Evolution of Operator Combination (E2OC) framework for MOEAs, which achieves the co-evolution of design strategies and executable codes. E2OC employs Monte Carlo Tree Search to progressively search combinations of operator design strategies and adopts an operator rotation mechanism to identify effective operator configurations while supporting the integration of mainstream AHD methods as the underlying designer. Experimental results across AHD tasks with varying objectives and problem scales show that E2OC consistently outperforms state-of-the-art AHD and other multi-heuristic co-design frameworks, demonstrating strong generalization and sustained optimization capability.
Beyond the Lower Bound: Bridging Regret Minimization and Best Arm Identification in Lexicographic Bandits
Nov 08, 2025In multi-objective decision-making with hierarchical preferences, lexicographic bandits provide a natural framework for optimizing multiple objectives in a prioritized order. In this setting, a learner repeatedly selects arms and observes reward vectors, aiming to maximize the reward for the highest-priority objective, then the next, and so on. While previous studies have primarily focused on regret minimization, this work bridges the gap between \textit{regret minimization} and \textit{best arm identification} under lexicographic preferences. We propose two elimination-based algorithms to address this joint objective. The first algorithm eliminates suboptimal arms sequentially, layer by layer, in accordance with the objective priorities, and achieves sample complexity and regret bounds comparable to those of the best single-objective algorithms. The second algorithm simultaneously leverages reward information from all objectives in each round, effectively exploiting cross-objective dependencies. Remarkably, it outperforms the known lower bound for the single-objective bandit problem, highlighting the benefit of cross-objective information sharing in the multi-objective setting. Empirical results further validate their superior performance over baselines.
ASBench: Image Anomalies Synthesis Benchmark for Anomaly Detection
Oct 09, 2025Anomaly detection plays a pivotal role in manufacturing quality control, yet its application is constrained by limited abnormal samples and high manual annotation costs. While anomaly synthesis offers a promising solution, existing studies predominantly treat anomaly synthesis as an auxiliary component within anomaly detection frameworks, lacking systematic evaluation of anomaly synthesis algorithms. Current research also overlook crucial factors specific to anomaly synthesis, such as decoupling its impact from detection, quantitative analysis of synthetic data and adaptability across different scenarios. To address these limitations, we propose ASBench, the first comprehensive benchmarking framework dedicated to evaluating anomaly synthesis methods. Our framework introduces four critical evaluation dimensions: (i) the generalization performance across different datasets and pipelines (ii) the ratio of synthetic to real data (iii) the correlation between intrinsic metrics of synthesis images and anomaly detection performance metrics , and (iv) strategies for hybrid anomaly synthesis methods. Through extensive experiments, ASBench not only reveals limitations in current anomaly synthesis methods but also provides actionable insights for future research directions in anomaly synthesis
SpikingMamba: Towards Energy-Efficient Large Language Models via Knowledge Distillation from Mamba
Oct 06, 2025
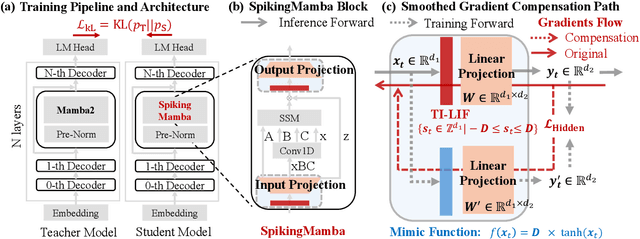


Large Language Models (LLMs) have achieved remarkable performance across tasks but remain energy-intensive due to dense matrix operations. Spiking neural networks (SNNs) improve energy efficiency by replacing dense matrix multiplications with sparse accumulations. Their sparse spike activity enables efficient LLMs deployment on edge devices. However, prior SNN-based LLMs often sacrifice performance for efficiency, and recovering accuracy typically requires full pretraining, which is costly and impractical. To address this, we propose SpikingMamba, an energy-efficient SNN-based LLMs distilled from Mamba that improves energy efficiency with minimal accuracy sacrifice. SpikingMamba integrates two key components: (a) TI-LIF, a ternary-integer spiking neuron that preserves semantic polarity through signed multi-level spike representations. (b) A training-exclusive Smoothed Gradient Compensation (SGC) path mitigating quantization loss while preserving spike-driven efficiency. We employ a single-stage distillation strategy to transfer the zero-shot ability of pretrained Mamba and further enhance it via reinforcement learning (RL). Experiments show that SpikingMamba-1.3B achieves a 4.76$\times$ energy benefit, with only a 4.78\% zero-shot accuracy gap compared to the original Mamba, and achieves a further 2.55\% accuracy improvement after RL.
Functional Consistency of LLM Code Embeddings: A Self-Evolving Data Synthesis Framework for Benchmarking
Aug 27, 2025Embedding models have demonstrated strong performance in tasks like clustering, retrieval, and feature extraction while offering computational advantages over generative models and cross-encoders. Benchmarks such as MTEB have shown that text embeddings from large language models (LLMs) capture rich semantic information, but their ability to reflect code-level functional semantics remains unclear. Existing studies largely focus on code clone detection, which emphasizes syntactic similarity and overlooks functional understanding. In this paper, we focus on the functional consistency of LLM code embeddings, which determines if two code snippets perform the same function regardless of syntactic differences. We propose a novel data synthesis framework called Functionality-Oriented Code Self-Evolution to construct diverse and challenging benchmarks. Specifically, we define code examples across four semantic and syntactic categories and find that existing datasets predominantly capture syntactic properties. Our framework generates four unique variations from a single code instance, providing a broader spectrum of code examples that better reflect functional differences. Extensive experiments on three downstream tasks-code clone detection, code functional consistency identification, and code retrieval-demonstrate that embedding models significantly improve their performance when trained on our evolved datasets. These results highlight the effectiveness and generalization of our data synthesis framework, advancing the functional understanding of code.
Quantization Meets dLLMs: A Systematic Study of Post-training Quantization for Diffusion LLMs
Aug 20, 2025Recent advances in diffusion large language models (dLLMs) have introduced a promising alternative to autoregressive (AR) LLMs for natural language generation tasks, leveraging full attention and denoising-based decoding strategies. However, the deployment of these models on edge devices remains challenging due to their massive parameter scale and high resource demands. While post-training quantization (PTQ) has emerged as a widely adopted technique for compressing AR LLMs, its applicability to dLLMs remains largely unexplored. In this work, we present the first systematic study on quantizing diffusion-based language models. We begin by identifying the presence of activation outliers, characterized by abnormally large activation values that dominate the dynamic range. These outliers pose a key challenge to low-bit quantization, as they make it difficult to preserve precision for the majority of values. More importantly, we implement state-of-the-art PTQ methods and conduct a comprehensive evaluation across multiple task types and model variants. Our analysis is structured along four key dimensions: bit-width, quantization method, task category, and model type. Through this multi-perspective evaluation, we offer practical insights into the quantization behavior of dLLMs under different configurations. We hope our findings provide a foundation for future research in efficient dLLM deployment. All codes and experimental setups will be released to support the community.
Discovering Interpretable Programmatic Policies via Multimodal LLM-assisted Evolutionary Search
Aug 07, 2025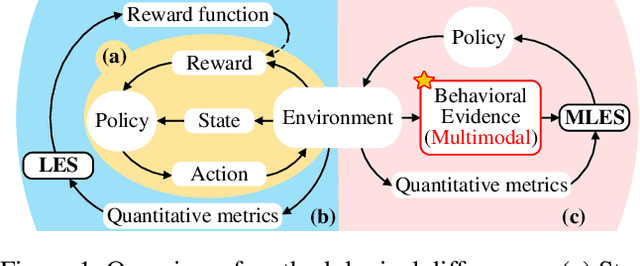
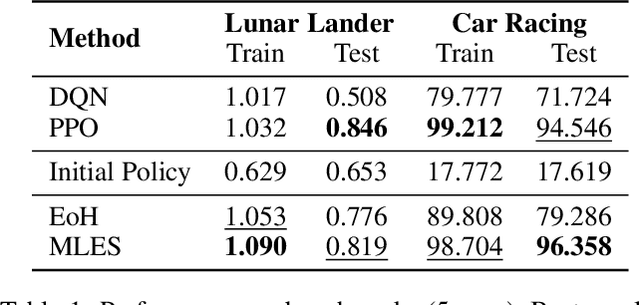
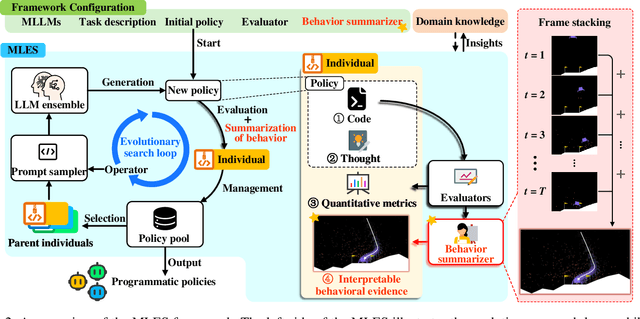
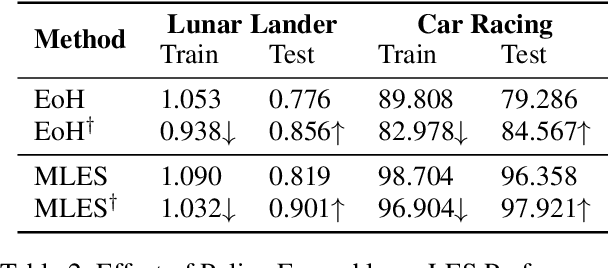
Interpretability and high performance are essential goals in designing control policies, particularly for safety-critical tasks. Deep reinforcement learning has greatly enhanced performance, yet its inherent lack of interpretability often undermines trust and hinders real-world deployment. This work addresses these dual challenges by introducing a novel approach for programmatic policy discovery, called Multimodal Large Language Model-assisted Evolutionary Search (MLES). MLES utilizes multimodal large language models as policy generators, combining them with evolutionary mechanisms for automatic policy optimization. It integrates visual feedback-driven behavior analysis within the policy generation process to identify failure patterns and facilitate targeted improvements, enhancing the efficiency of policy discovery and producing adaptable, human-aligned policies. Experimental results show that MLES achieves policy discovery capabilities and efficiency comparable to Proximal Policy Optimization (PPO) across two control tasks, while offering transparent control logic and traceable design processes. This paradigm overcomes the limitations of predefined domain-specific languages, facilitates knowledge transfer and reuse, and is scalable across various control tasks. MLES shows promise as a leading approach for the next generation of interpretable control policy discovery.