 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlada: Alternating Adaptation of Momentum Method for Memory-Efficient Matrix Optimization
Dec 15, 2025This work proposes Alada, an adaptive momentum method for stochastic optimization over large-scale matrices. Alada employs a rank-one factorization approach to estimate the second moment of gradients, where factors are updated alternatively to minimize the estimation error. Alada achieves sublinear memory overheads and can be readily extended to optimizing tensor-shaped variables.We also equip Alada with a first moment estimation rule, which enhances the algorithm's robustness without incurring additional memory overheads. The theoretical performance of Alada aligns with that of traditional methods such as Adam. Numerical studies conducted on several natural language processing tasks demonstrate the reduction in memory overheads and the robustness in training large models relative to Adam and its variants.
Functional Consistency of LLM Code Embeddings: A Self-Evolving Data Synthesis Framework for Benchmarking
Aug 27, 2025Embedding models have demonstrated strong performance in tasks like clustering, retrieval, and feature extraction while offering computational advantages over generative models and cross-encoders. Benchmarks such as MTEB have shown that text embeddings from large language models (LLMs) capture rich semantic information, but their ability to reflect code-level functional semantics remains unclear. Existing studies largely focus on code clone detection, which emphasizes syntactic similarity and overlooks functional understanding. In this paper, we focus on the functional consistency of LLM code embeddings, which determines if two code snippets perform the same function regardless of syntactic differences. We propose a novel data synthesis framework called Functionality-Oriented Code Self-Evolution to construct diverse and challenging benchmarks. Specifically, we define code examples across four semantic and syntactic categories and find that existing datasets predominantly capture syntactic properties. Our framework generates four unique variations from a single code instance, providing a broader spectrum of code examples that better reflect functional differences. Extensive experiments on three downstream tasks-code clone detection, code functional consistency identification, and code retrieval-demonstrate that embedding models significantly improve their performance when trained on our evolved datasets. These results highlight the effectiveness and generalization of our data synthesis framework, advancing the functional understanding of code.
Mitigating Social Bias in Large Language Models: A Multi-Objective Approach within a Multi-Agent Framework
Dec 20, 2024



Natural language processing (NLP) has seen remarkable advancements with the development of large language models (LLMs). Despite these advancements, LLMs often produce socially biased outputs. Recent studies have mainly addressed this problem by prompting LLMs to behave ethically, but this approach results in unacceptable performance degradation. In this paper, we propose a multi-objective approach within a multi-agent framework (MOMA) to mitigate social bias in LLMs without significantly compromising their performance. The key idea of MOMA involves deploying multiple agents to perform causal interventions on bias-related contents of the input questions, breaking the shortcut connection between these contents and the corresponding answers. Unlike traditional debiasing techniques leading to performance degradation, MOMA substantially reduces bias while maintaining accuracy in downstream tasks. Our experiments conducted on two datasets and two models demonstrate that MOMA reduces bias scores by up to 87.7%, with only a marginal performance degradation of up to 6.8% in the BBQ dataset. Additionally, it significantly enhances the multi-objective metric icat in the StereoSet dataset by up to 58.1%. Code will be made available at https://github.com/Cortantse/MOMA.
Driving in the Occupancy World: Vision-Centric 4D Occupancy Forecasting and Planning via World Models for Autonomous Driving
Aug 26, 2024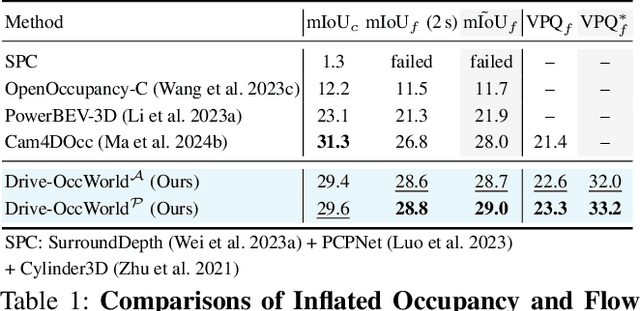
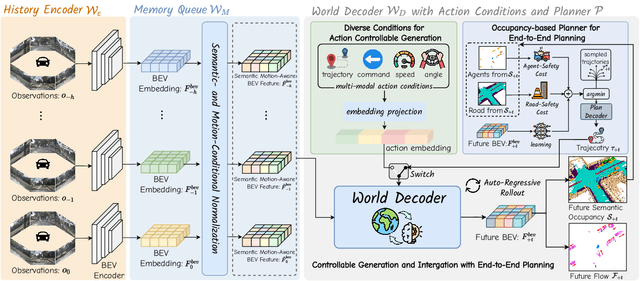
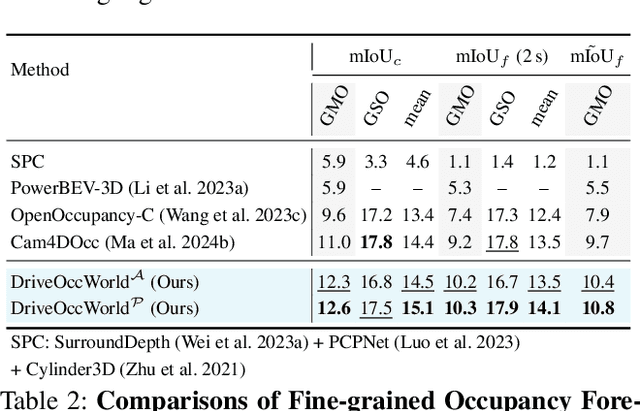
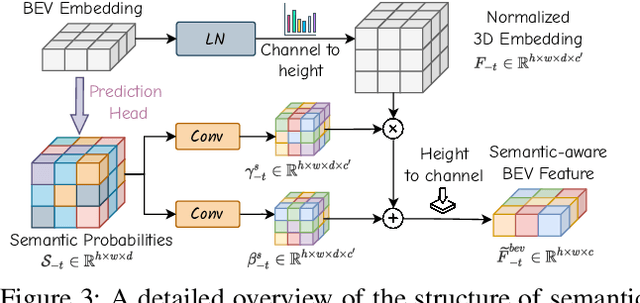
World models envision potential future states based on various ego actions. They embed extensive knowledge about the driving environment, facilitating safe and scalable autonomous driving. Most existing methods primarily focus on either data generation or the pretraining paradigms of world models. Unlike the aforementioned prior works, we propose Drive-OccWorld, which adapts a vision-centric 4D forecasting world model to end-to-end planning for autonomous driving. Specifically, we first introduce a semantic and motion-conditional normalization in the memory module, which accumulates semantic and dynamic information from historical BEV embeddings. These BEV features are then conveyed to the world decoder for future occupancy and flow forecasting, considering both geometry and spatiotemporal modeling. Additionally, we propose injecting flexible action conditions, such as velocity, steering angle, trajectory, and commands, into the world model to enable controllable generation and facilitate a broader range of downstream applications. Furthermore, we explore integrating the generative capabilities of the 4D world model with end-to-end planning, enabling continuous forecasting of future states and the selection of optimal trajectories using an occupancy-based cost function. Extensive experiments on the nuScenes dataset demonstrate that our method can generate plausible and controllable 4D occupancy, opening new avenues for driving world generation and end-to-end planning.
LLM-Guided Multi-View Hypergraph Learning for Human-Centric Explainable Recommendation
Jan 16, 2024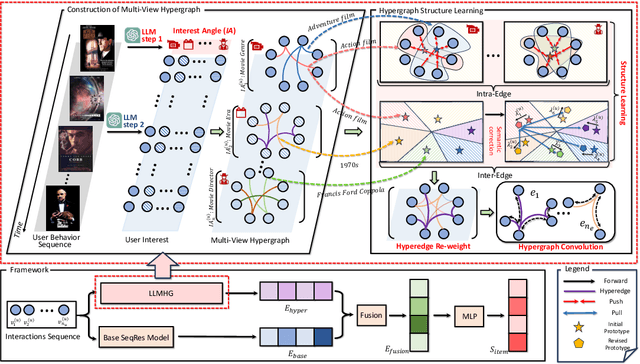
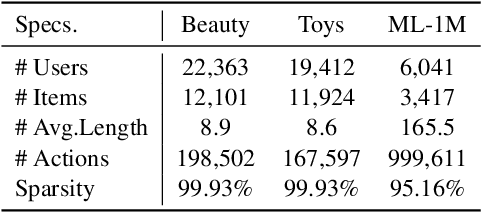
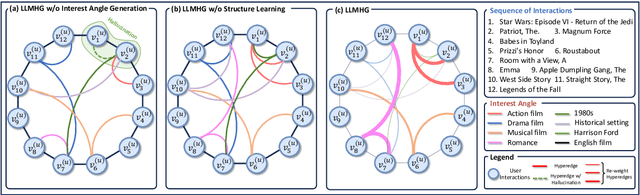
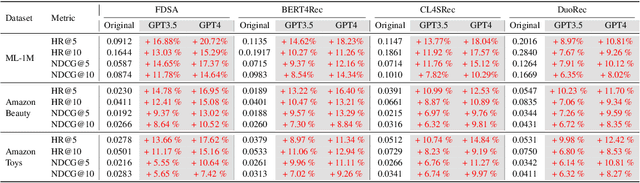
As personalized recommendation systems become vital in the age of information overload, traditional methods relying solely on historical user interactions often fail to fully capture the multifaceted nature of human interests. To enable more human-centric modeling of user preferences, this work proposes a novel explainable recommendation framework, i.e., LLMHG, synergizing the reasoning capabilities of large language models (LLMs) and the structural advantages of hypergraph neural networks. By effectively profiling and interpreting the nuances of individual user interests, our framework pioneers enhancements to recommendation systems with increased explainability. We validate that explicitly accounting for the intricacies of human preferences allows our human-centric and explainable LLMHG approach to consistently outperform conventional models across diverse real-world datasets. The proposed plug-and-play enhancement framework delivers immediate gains in recommendation performance while offering a pathway to apply advanced LLMs for better capturing the complexity of human interests across machine learning applications.
Chain-of-Thought Tuning: Masked Language Models can also Think Step By Step in Natural Language Understanding
Oct 18, 2023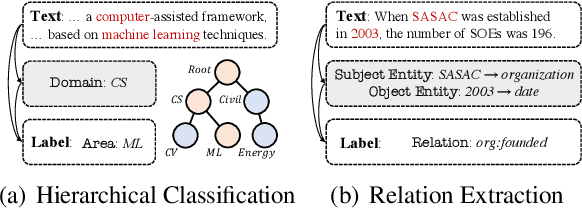
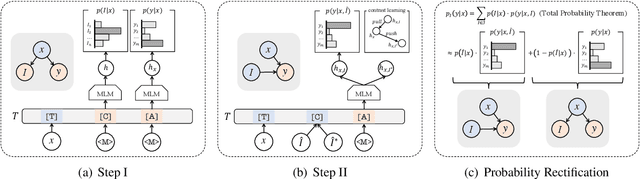
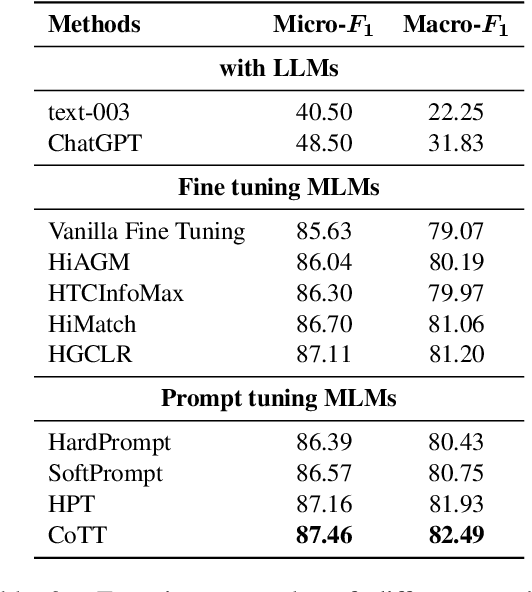
Chain-of-Thought (CoT) is a technique that guides Large Language Models (LLMs) to decompose complex tasks into multi-step reasoning through intermediate steps in natural language form. Briefly, CoT enables LLMs to think step by step. However, although many Natural Language Understanding (NLU) tasks also require thinking step by step, LLMs perform less well than small-scale Masked Language Models (MLMs). To migrate CoT from LLMs to MLMs, we propose Chain-of-Thought Tuning (CoTT), a two-step reasoning framework based on prompt tuning, to implement step-by-step thinking for MLMs on NLU tasks. From the perspective of CoT, CoTT's two-step framework enables MLMs to implement task decomposition; CoTT's prompt tuning allows intermediate steps to be used in natural language form. Thereby, the success of CoT can be extended to NLU tasks through MLMs. To verify the effectiveness of CoTT, we conduct experiments on two NLU tasks: hierarchical classification and relation extraction, and the results show that CoTT outperforms baselines and achieves state-of-the-art performance.
Accurate Use of Label Dependency in Multi-Label Text Classification Through the Lens of Causality
Oct 11, 2023Multi-Label Text Classification (MLTC) aims to assign the most relevant labels to each given text. Existing methods demonstrate that label dependency can help to improve the model's performance. However, the introduction of label dependency may cause the model to suffer from unwanted prediction bias. In this study, we attribute the bias to the model's misuse of label dependency, i.e., the model tends to utilize the correlation shortcut in label dependency rather than fusing text information and label dependency for prediction. Motivated by causal inference, we propose a CounterFactual Text Classifier (CFTC) to eliminate the correlation bias, and make causality-based predictions. Specifically, our CFTC first adopts the predict-then-modify backbone to extract precise label information embedded in label dependency, then blocks the correlation shortcut through the counterfactual de-bias technique with the help of the human causal graph. Experimental results on three datasets demonstrate that our CFTC significantly outperforms the baselines and effectively eliminates the correlation bias in datasets.
Unlock the Potential of Counterfactually-Augmented Data in Out-Of-Distribution Generalization
Oct 10, 2023

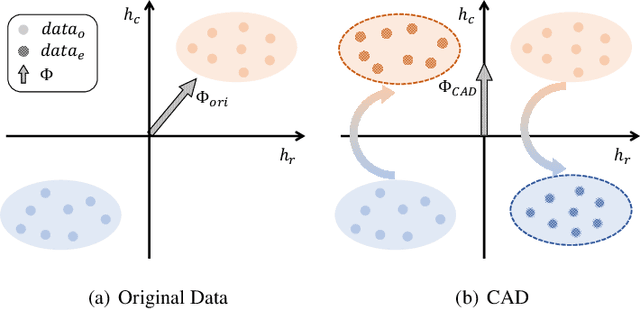

Counterfactually-Augmented Data (CAD) -- minimal editing of sentences to flip the corresponding labels -- has the potential to improve the Out-Of-Distribution (OOD) generalization capability of language models, as CAD induces language models to exploit domain-independent causal features and exclude spurious correlations. However, the empirical results of CAD's OOD generalization are not as efficient as anticipated. In this study, we attribute the inefficiency to the myopia phenomenon caused by CAD: language models only focus on causal features that are edited in the augmentation operation and exclude other non-edited causal features. Therefore, the potential of CAD is not fully exploited. To address this issue, we analyze the myopia phenomenon in feature space from the perspective of Fisher's Linear Discriminant, then we introduce two additional constraints based on CAD's structural properties (dataset-level and sentence-level) to help language models extract more complete causal features in CAD, thereby mitigating the myopia phenomenon and improving OOD generalization capability. We evaluate our method on two tasks: Sentiment Analysis and Natural Language Inference, and the experimental results demonstrate that our method could unlock the potential of CAD and improve the OOD generalization performance of language models by 1.0% to 5.9%.
MaxGNR: A Dynamic Weight Strategy via Maximizing Gradient-to-Noise Ratio for Multi-Task Learning
Feb 18, 2023



When modeling related tasks in computer vision, Multi-Task Learning (MTL) can outperform Single-Task Learning (STL) due to its ability to capture intrinsic relatedness among tasks. However, MTL may encounter the insufficient training problem, i.e., some tasks in MTL may encounter non-optimal situation compared with STL. A series of studies point out that too much gradient noise would lead to performance degradation in STL, however, in the MTL scenario, Inter-Task Gradient Noise (ITGN) is an additional source of gradient noise for each task, which can also affect the optimization process. In this paper, we point out ITGN as a key factor leading to the insufficient training problem. We define the Gradient-to-Noise Ratio (GNR) to measure the relative magnitude of gradient noise and design the MaxGNR algorithm to alleviate the ITGN interference of each task by maximizing the GNR of each task. We carefully evaluate our MaxGNR algorithm on two standard image MTL datasets: NYUv2 and Cityscapes. The results show that our algorithm outperforms the baselines under identical experimental conditions.
Improving the Out-Of-Distribution Generalization Capability of Language Models: Counterfactually-Augmented Data is not Enough
Feb 18, 2023Counterfactually-Augmented Data (CAD) has the potential to improve language models' Out-Of-Distribution (OOD) generalization capability, as CAD induces language models to exploit causal features and exclude spurious correlations. However, the empirical results of OOD generalization on CAD are not as efficient as expected. In this paper, we attribute the inefficiency to Myopia Phenomenon caused by CAD: language models only focus on causal features that are edited in the augmentation and exclude other non-edited causal features. As a result, the potential of CAD is not fully exploited. Based on the structural properties of CAD, we design two additional constraints to help language models extract more complete causal features contained in CAD, thus improving the OOD generalization capability. We evaluate our method on two tasks: Sentiment Analysis and Natural Language Inference, and the experimental results demonstrate that our method could unlock CAD's potential and improve language models' OOD generalization capability.