 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTools are under-documented: Simple Document Expansion Boosts Tool Retrieval
Oct 26, 2025Large Language Models (LLMs) have recently demonstrated strong capabilities in tool use, yet progress in tool retrieval remains hindered by incomplete and heterogeneous tool documentation. To address this challenge, we introduce Tool-DE, a new benchmark and framework that systematically enriches tool documentation with structured fields to enable more effective tool retrieval, together with two dedicated models, Tool-Embed and Tool-Rank. We design a scalable document expansion pipeline that leverages both open- and closed-source LLMs to generate, validate, and refine enriched tool profiles at low cost, producing large-scale corpora with 50k instances for embedding-based retrievers and 200k for rerankers. On top of this data, we develop two models specifically tailored for tool retrieval: Tool-Embed, a dense retriever, and Tool-Rank, an LLM-based reranker. Extensive experiments on ToolRet and Tool-DE demonstrate that document expansion substantially improves retrieval performance, with Tool-Embed and Tool-Rank achieving new state-of-the-art results on both benchmarks. We further analyze the contribution of individual fields to retrieval effectiveness, as well as the broader impact of document expansion on both training and evaluation. Overall, our findings highlight both the promise and limitations of LLM-driven document expansion, positioning Tool-DE, along with the proposed Tool-Embed and Tool-Rank, as a foundation for future research in tool retrieval.
MultiConIR: Towards multi-condition Information Retrieval
Mar 11, 2025



In this paper, we introduce MultiConIR, the first benchmark designed to evaluate retrieval models in multi-condition scenarios. Unlike existing datasets that primarily focus on single-condition queries from search engines, MultiConIR captures real-world complexity by incorporating five diverse domains: books, movies, people, medical cases, and legal documents. We propose three tasks to systematically assess retrieval and reranking models on multi-condition robustness, monotonic relevance ranking, and query format sensitivity. Our findings reveal that existing retrieval and reranking models struggle with multi-condition retrieval, with rerankers suffering severe performance degradation as query complexity increases. We further investigate the performance gap between retrieval and reranking models, exploring potential reasons for these discrepancies, and analysis the impact of different pooling strategies on condition placement sensitivity. Finally, we highlight the strengths of GritLM and Nv-Embed, which demonstrate enhanced adaptability to multi-condition queries, offering insights for future retrieval models. The code and datasets are available at https://github.com/EIT-NLP/MultiConIR.
Where to Go Next Day: Multi-scale Spatial-Temporal Decoupled Model for Mid-term Human Mobility Prediction
Jan 11, 2025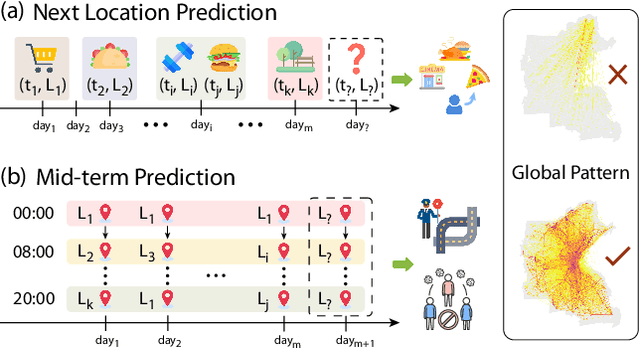
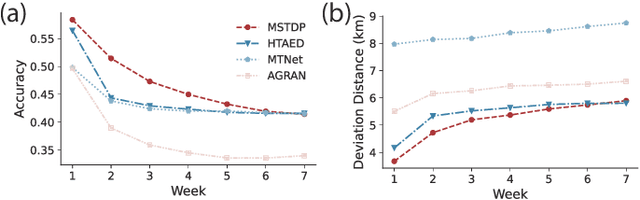
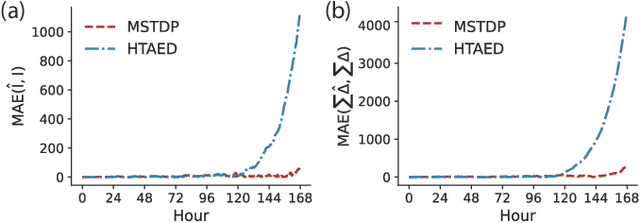
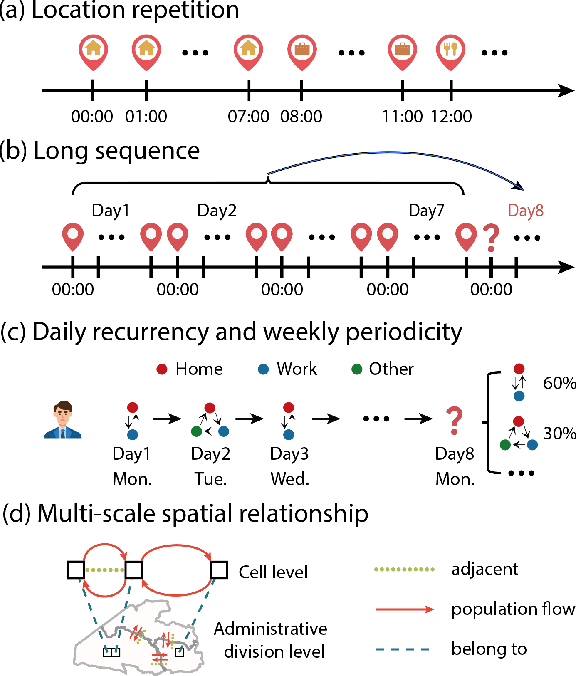
Predicting individual mobility patterns is crucial across various applications. While current methods mainly focus on predicting the next location for personalized services like recommendations, they often fall short in supporting broader applications such as traffic management and epidemic control, which require longer period forecasts of human mobility. This study addresses mid-term mobility prediction, aiming to capture daily travel patterns and forecast trajectories for the upcoming day or week. We propose a novel Multi-scale Spatial-Temporal Decoupled Predictor (MSTDP) designed to efficiently extract spatial and temporal information by decoupling daily trajectories into distinct location-duration chains. Our approach employs a hierarchical encoder to model multi-scale temporal patterns, including daily recurrence and weekly periodicity, and utilizes a transformer-based decoder to globally attend to predicted information in the location or duration chain. Additionally, we introduce a spatial heterogeneous graph learner to capture multi-scale spatial relationships, enhancing semantic-rich representations. Extensive experiments, including statistical physics analysis, are conducted on large-scale mobile phone records in five cities (Boston, Los Angeles, SF Bay Area, Shanghai, and Tokyo), to demonstrate MSTDP's advantages. Applied to epidemic modeling in Boston, MSTDP significantly outperforms the best-performing baseline, achieving a remarkable 62.8% reduction in MAE for cumulative new cases.
TrajGEOS: Trajectory Graph Enhanced Orientation-based Sequential Network for Mobility Prediction
Dec 26, 2024Human mobility studies how people move to access their needed resources and plays a significant role in urban planning and location-based services. As a paramount task of human mobility modeling, next location prediction is challenging because of the diversity of users' historical trajectories that gives rise to complex mobility patterns and various contexts. Deep sequential models have been widely used to predict the next location by leveraging the inherent sequentiality of trajectory data. However, they do not fully leverage the relationship between locations and fail to capture users' multi-level preferences. This work constructs a trajectory graph from users' historical traces and proposes a \textbf{Traj}ectory \textbf{G}raph \textbf{E}nhanced \textbf{O}rientation-based \textbf{S}equential network (TrajGEOS) for next-location prediction tasks. TrajGEOS introduces hierarchical graph convolution to capture location and user embeddings. Such embeddings consider not only the contextual feature of locations but also the relation between them, and serve as additional features in downstream modules. In addition, we design an orientation-based module to learn users' mid-term preferences from sequential modeling modules and their recent trajectories. Extensive experiments on three real-world LBSN datasets corroborate the value of graph and orientation-based modules and demonstrate that TrajGEOS outperforms the state-of-the-art methods on the next location prediction task.
Learning Chemical Reaction Representation with Reactant-Product Alignment
Nov 26, 2024



Organic synthesis stands as a cornerstone of chemical industry. The development of robust machine learning models to support tasks associated with organic reactions is of significant interest. However, current methods rely on hand-crafted features or direct adaptations of model architectures from other domains, which lacks feasibility as data scales increase or overlook the rich chemical information inherent in reactions. To address these issues, this paper introduces {\modelname}, a novel chemical reaction representation learning model tailored for a variety of organic-reaction-related tasks. By integrating atomic correspondence between reactants and products, our model discerns the molecular transformations that occur during the reaction, thereby enhancing the comprehension of the reaction mechanism. We have designed an adapter structure to incorporate reaction conditions into the chemical reaction representation, allowing the model to handle diverse reaction conditions and adapt to various datasets and downstream tasks, e.g., reaction performance prediction. Additionally, we introduce a reaction-center aware attention mechanism that enables the model to concentrate on key functional groups, thereby generating potent representations for chemical reactions. Our model has been evaluated on a range of downstream tasks, including reaction condition prediction, reaction yield prediction, and reaction selectivity prediction. Experimental results indicate that our model markedly outperforms existing chemical reaction representation learning architectures across all tasks. Notably, our model significantly outperforms all the baselines with up to 25\% (top-1) and 16\% (top-10) increased accuracy over the strongest baseline on USPTO\_CONDITION dataset for reaction condition prediction. We plan to open-source the code contingent upon the acceptance of the paper.
Alignment Between the Decision-Making Logic of LLMs and Human Cognition: A Case Study on Legal LLMs
Oct 06, 2024



This paper presents a method to evaluate the alignment between the decision-making logic of Large Language Models (LLMs) and human cognition in a case study on legal LLMs. Unlike traditional evaluations on language generation results, we propose to evaluate the correctness of the detailed decision-making logic of an LLM behind its seemingly correct outputs, which represents the core challenge for an LLM to earn human trust. To this end, we quantify the interactions encoded by the LLM as primitive decision-making logic, because recent theoretical achievements have proven several mathematical guarantees of the faithfulness of the interaction-based explanation. We design a set of metrics to evaluate the detailed decision-making logic of LLMs. Experiments show that even when the language generation results appear correct, a significant portion of the internal inference logic contains notable issues.
Text-Augmented Multimodal LLMs for Chemical Reaction Condition Recommendation
Jul 21, 2024High-throughput reaction condition (RC) screening is fundamental to chemical synthesis. However, current RC screening suffers from laborious and costly trial-and-error workflows. Traditional computer-aided synthesis planning (CASP) tools fail to find suitable RCs due to data sparsity and inadequate reaction representations. Nowadays, large language models (LLMs) are capable of tackling chemistry-related problems, such as molecule design, and chemical logic Q\&A tasks. However, LLMs have not yet achieved accurate predictions of chemical reaction conditions. Here, we present MM-RCR, a text-augmented multimodal LLM that learns a unified reaction representation from SMILES, reaction graphs, and textual corpus for chemical reaction recommendation (RCR). To train MM-RCR, we construct 1.2 million pair-wised Q\&A instruction datasets. Our experimental results demonstrate that MM-RCR achieves state-of-the-art performance on two open benchmark datasets and exhibits strong generalization capabilities on out-of-domain (OOD) and High-Throughput Experimentation (HTE) datasets. MM-RCR has the potential to accelerate high-throughput condition screening in chemical synthesis.
Hypothesis Testing Prompting Improves Deductive Reasoning in Large Language Models
May 09, 2024
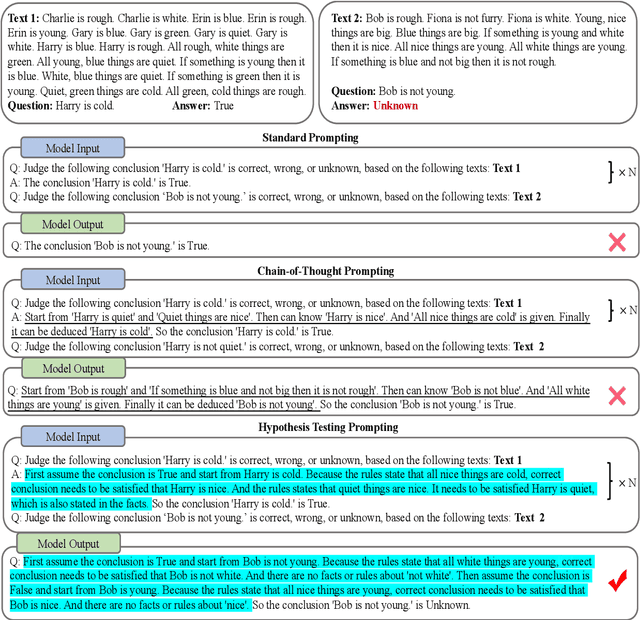
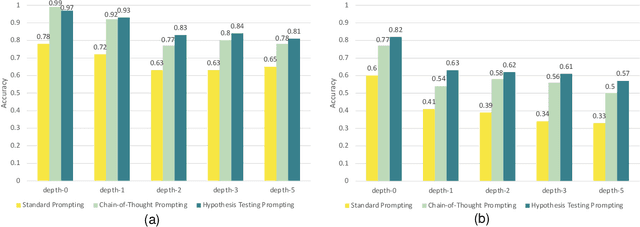
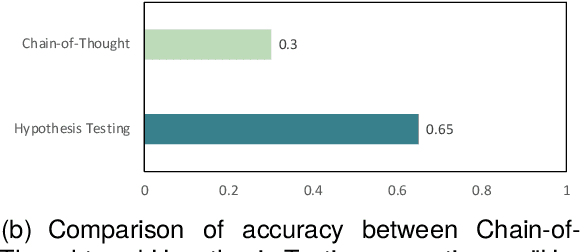
Combining different forms of prompts with pre-trained large language models has yielded remarkable results on reasoning tasks (e.g. Chain-of-Thought prompting). However, along with testing on more complex reasoning, these methods also expose problems such as invalid reasoning and fictional reasoning paths. In this paper, we develop \textit{Hypothesis Testing Prompting}, which adds conclusion assumptions, backward reasoning, and fact verification during intermediate reasoning steps. \textit{Hypothesis Testing prompting} involves multiple assumptions and reverses validation of conclusions leading to its unique correct answer. Experiments on two challenging deductive reasoning datasets ProofWriter and RuleTaker show that hypothesis testing prompting not only significantly improves the effect, but also generates a more reasonable and standardized reasoning process.
Logical Negation Augmenting and Debiasing for Prompt-based Methods
May 08, 2024
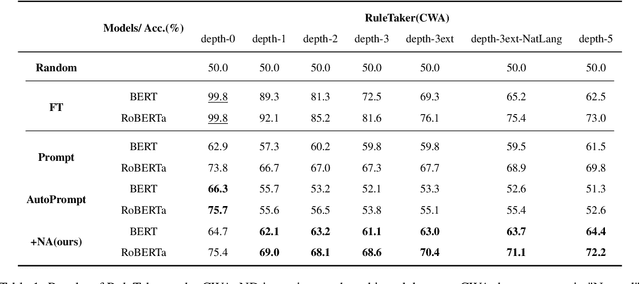
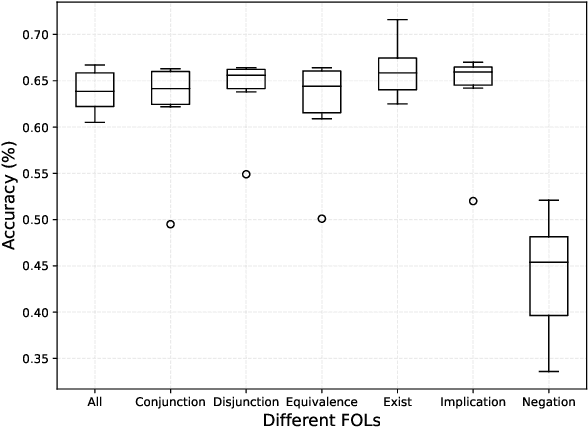
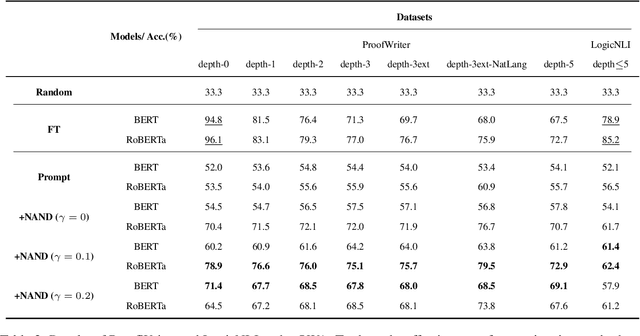
Prompt-based methods have gained increasing attention on NLP and shown validity on many downstream tasks. Many works have focused on mining these methods' potential for knowledge extraction, but few explore their ability to make logical reasoning. In this work, we focus on the effectiveness of the prompt-based methods on first-order logical reasoning and find that the bottleneck lies in logical negation. Based on our analysis, logical negation tends to result in spurious correlations to negative answers, while propositions without logical negation correlate to positive answers. To solve the problem, we propose a simple but effective method, Negation Augmenting and Negation Debiasing (NAND), which introduces negative propositions to prompt-based methods without updating parameters. Specifically, these negative propositions can counteract spurious correlations by providing "not" for all instances so that models cannot make decisions only by whether expressions contain a logical negation. Experiments on three datasets show that NAND not only solves the problem of calibrating logical negation but also significantly enhances prompt-based methods of logical reasoning without model retraining.
UAlign: Pushing the Limit of Template-free Retrosynthesis Prediction with Unsupervised SMILES Alignment
Mar 25, 2024Retrosynthesis planning poses a formidable challenge in the organic chemical industry, particularly in pharmaceuticals. Single-step retrosynthesis prediction, a crucial step in the planning process, has witnessed a surge in interest in recent years due to advancements in AI for science. Various deep learning-based methods have been proposed for this task in recent years, incorporating diverse levels of additional chemical knowledge dependency. This paper introduces UAlign, a template-free graph-to-sequence pipeline for retrosynthesis prediction. By combining graph neural networks and Transformers, our method can more effectively leverage the inherent graph structure of molecules. Based on the fact that the majority of molecule structures remain unchanged during a chemical reaction, we propose a simple yet effective SMILES alignment technique to facilitate the reuse of unchanged structures for reactant generation. Extensive experiments show that our method substantially outperforms state-of-the-art template-free and semi-template-based approaches. Importantly, Our template-free method achieves effectiveness comparable to, or even surpasses, established powerful template-based methods. Scientific contribution: We present a novel graph-to-sequence template-free retrosynthesis prediction pipeline that overcomes the limitations of Transformer-based methods in molecular representation learning and insufficient utilization of chemical information. We propose an unsupervised learning mechanism for establishing product-atom correspondence with reactant SMILES tokens, achieving even better results than supervised SMILES alignment methods. Extensive experiments demonstrate that UAlign significantly outperforms state-of-the-art template-free methods and rivals or surpasses template-based approaches, with up to 5\% (top-5) and 5.4\% (top-10) increased accuracy over the strongest baseline.