 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Short and Unified Convergence Analysis of the SAG, SAGA, and IAG Algorithms
Feb 05, 2026Stochastic variance-reduced algorithms such as Stochastic Average Gradient (SAG) and SAGA, and their deterministic counterparts like the Incremental Aggregated Gradient (IAG) method, have been extensively studied in large-scale machine learning. Despite their popularity, existing analyses for these algorithms are disparate, relying on different proof techniques tailored to each method. Furthermore, the original proof of SAG is known to be notoriously involved, requiring computer-aided analysis. Focusing on finite-sum optimization with smooth and strongly convex objective functions, our main contribution is to develop a single unified convergence analysis that applies to all three algorithms: SAG, SAGA, and IAG. Our analysis features two key steps: (i) establishing a bound on delays due to stochastic sub-sampling using simple concentration tools, and (ii) carefully designing a novel Lyapunov function that accounts for such delays. The resulting proof is short and modular, providing the first high-probability bounds for SAG and SAGA that can be seamlessly extended to non-convex objectives and Markov sampling. As an immediate byproduct of our new analysis technique, we obtain the best known rates for the IAG algorithm, significantly improving upon prior bounds.
From Confounding to Learning: Dynamic Service Fee Pricing on Third-Party Platforms
Dec 28, 2025We study the pricing behavior of third-party platforms facing strategic agents. Assuming the platform is a revenue maximizer, it observes market features that generally affect demand. Since only the equilibrium price and quantity are observable, this presents a general demand learning problem under confounding. Mathematically, we develop an algorithm with optimal regret of $\Tilde{\cO}(\sqrt{T}\wedgeσ_S^{-2})$. Our results reveal that supply-side noise fundamentally affects the learnability of demand, leading to a phase transition in regret. Technically, we show that non-i.i.d. actions can serve as instrumental variables for learning demand. We also propose a novel homeomorphic construction that allows us to establish estimation bounds without assuming star-shapedness, providing the first efficiency guarantee for learning demand with deep neural networks. Finally, we demonstrate the practical applicability of our approach through simulations and real-world data from Zomato and Lyft.
GTR-Bench: Evaluating Geo-Temporal Reasoning in Vision-Language Models
Oct 09, 2025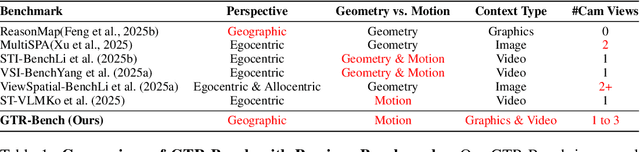
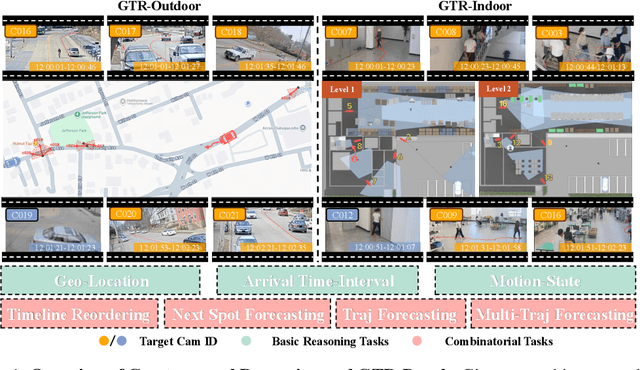
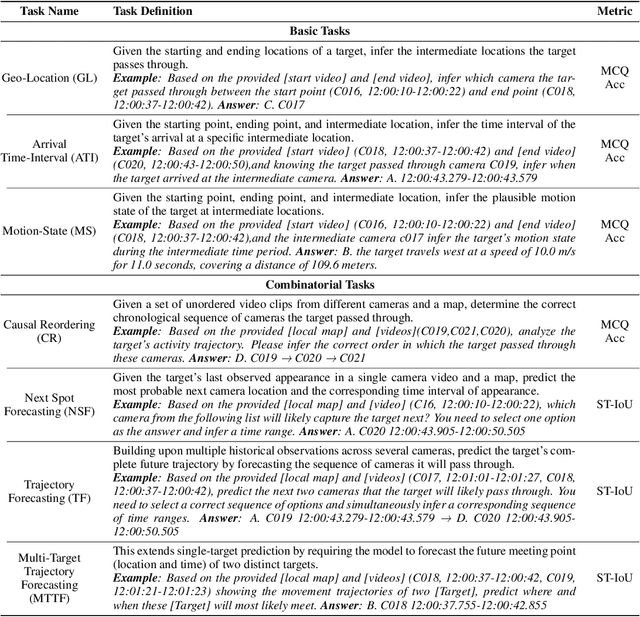
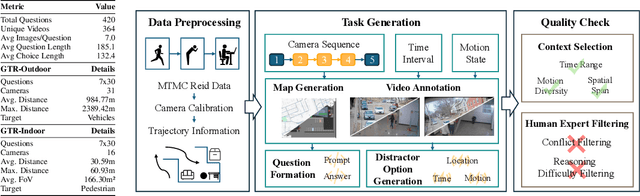
Recently spatial-temporal intelligence of Visual-Language Models (VLMs) has attracted much attention due to its importance for Autonomous Driving, Embodied AI and General Artificial Intelligence. Existing spatial-temporal benchmarks mainly focus on egocentric perspective reasoning with images/video context, or geographic perspective reasoning with graphics context (eg. a map), thus fail to assess VLMs' geographic spatial-temporal intelligence with both images/video and graphics context, which is important for areas like traffic management and emergency response. To address the gaps, we introduce Geo-Temporal Reasoning benchmark (GTR-Bench), a novel challenge for geographic temporal reasoning of moving targets in a large-scale camera network. GTR-Bench is more challenging as it requires multiple perspective switches between maps and videos, joint reasoning across multiple videos with non-overlapping fields of view, and inference over spatial-temporal regions that are unobserved by any video context. Evaluations of more than 10 popular VLMs on GTR-Bench demonstrate that even the best proprietary model, Gemini-2.5-Pro (34.9%), significantly lags behind human performance (78.61%) on geo-temporal reasoning. Moreover, our comprehensive analysis on GTR-Bench reveals three primary deficiencies of current models for geo-temporal reasoning. (1) VLMs' reasoning is impaired by an imbalanced utilization of spatial-temporal context. (2) VLMs are weak in temporal forecasting, which leads to worse performance on temporal-emphasized tasks than on spatial-emphasized tasks. (3) VLMs lack the proficiency to comprehend or align the map data with multi-view video inputs. We believe GTR-Bench offers valuable insights and opens up new opportunities for research and applications in spatial-temporal intelligence. Benchmark and code will be released at https://github.com/X-Luffy/GTR-Bench.
Ring-lite: Scalable Reasoning via C3PO-Stabilized Reinforcement Learning for LLMs
Jun 18, 2025We present Ring-lite, a Mixture-of-Experts (MoE)-based large language model optimized via reinforcement learning (RL) to achieve efficient and robust reasoning capabilities. Built upon the publicly available Ling-lite model, a 16.8 billion parameter model with 2.75 billion activated parameters, our approach matches the performance of state-of-the-art (SOTA) small-scale reasoning models on challenging benchmarks (e.g., AIME, LiveCodeBench, GPQA-Diamond) while activating only one-third of the parameters required by comparable models. To accomplish this, we introduce a joint training pipeline integrating distillation with RL, revealing undocumented challenges in MoE RL training. First, we identify optimization instability during RL training, and we propose Constrained Contextual Computation Policy Optimization(C3PO), a novel approach that enhances training stability and improves computational throughput via algorithm-system co-design methodology. Second, we empirically demonstrate that selecting distillation checkpoints based on entropy loss for RL training, rather than validation metrics, yields superior performance-efficiency trade-offs in subsequent RL training. Finally, we develop a two-stage training paradigm to harmonize multi-domain data integration, addressing domain conflicts that arise in training with mixed dataset. We will release the model, dataset, and code.
SORCE: Small Object Retrieval in Complex Environments
May 30, 2025Text-to-Image Retrieval (T2IR) is a highly valuable task that aims to match a given textual query to images in a gallery. Existing benchmarks primarily focus on textual queries describing overall image semantics or foreground salient objects, possibly overlooking inconspicuous small objects, especially in complex environments. Such small object retrieval is crucial, as in real-world applications, the targets of interest are not always prominent in the image. Thus, we introduce SORCE (Small Object Retrieval in Complex Environments), a new subfield of T2IR, focusing on retrieving small objects in complex images with textual queries. We propose a new benchmark, SORCE-1K, consisting of images with complex environments and textual queries describing less conspicuous small objects with minimal contextual cues from other salient objects. Preliminary analysis on SORCE-1K finds that existing T2IR methods struggle to capture small objects and encode all the semantics into a single embedding, leading to poor retrieval performance on SORCE-1K. Therefore, we propose to represent each image with multiple distinctive embeddings. We leverage Multimodal Large Language Models (MLLMs) to extract multiple embeddings for each image instructed by a set of Regional Prompts (ReP). Experimental results show that our multi-embedding approach through MLLM and ReP significantly outperforms existing T2IR methods on SORCE-1K. Our experiments validate the effectiveness of SORCE-1K for benchmarking SORCE performances, highlighting the potential of multi-embedding representation and text-customized MLLM features for addressing this task.
Causal-Invariant Cross-Domain Out-of-Distribution Recommendation
May 22, 2025Cross-Domain Recommendation (CDR) aims to leverage knowledge from a relatively data-richer source domain to address the data sparsity problem in a relatively data-sparser target domain. While CDR methods need to address the distribution shifts between different domains, i.e., cross-domain distribution shifts (CDDS), they typically assume independent and identical distribution (IID) between training and testing data within the target domain. However, this IID assumption rarely holds in real-world scenarios due to single-domain distribution shift (SDDS). The above two co-existing distribution shifts lead to out-of-distribution (OOD) environments that hinder effective knowledge transfer and generalization, ultimately degrading recommendation performance in CDR. To address these co-existing distribution shifts, we propose a novel Causal-Invariant Cross-Domain Out-of-distribution Recommendation framework, called CICDOR. In CICDOR, we first learn dual-level causal structures to infer domain-specific and domain-shared causal-invariant user preferences for tackling both CDDS and SDDS under OOD environments in CDR. Then, we propose an LLM-guided confounder discovery module that seamlessly integrates LLMs with a conventional causal discovery method to extract observed confounders for effective deconfounding, thereby enabling accurate causal-invariant preference inference. Extensive experiments on two real-world datasets demonstrate the superior recommendation accuracy of CICDOR over state-of-the-art methods across various OOD scenarios.
MAAM: A Lightweight Multi-Agent Aggregation Module for Efficient Image Classification Based on the MindSpore Framework
Apr 18, 2025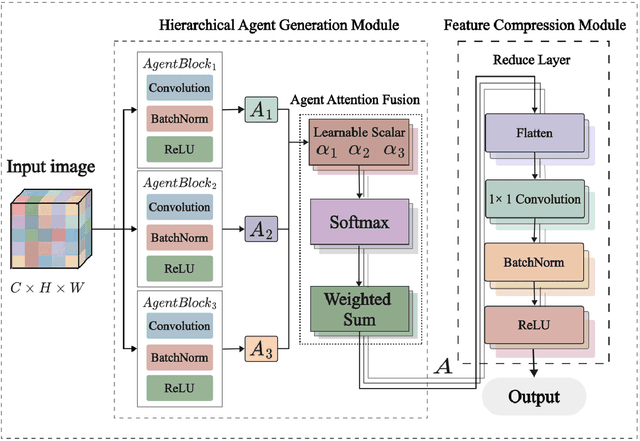
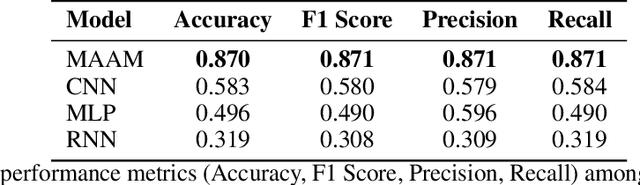
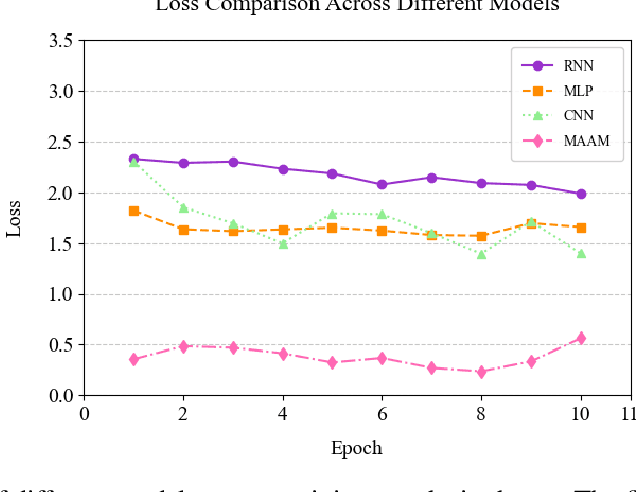
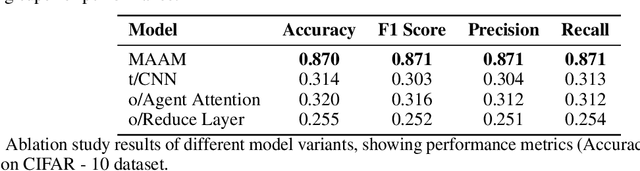
The demand for lightweight models in image classification tasks under resource-constrained environments necessitates a balance between computational efficiency and robust feature representation. Traditional attention mechanisms, despite their strong feature modeling capability, often struggle with high computational complexity and structural rigidity, limiting their applicability in scenarios with limited computational resources (e.g., edge devices or real-time systems). To address this, we propose the Multi-Agent Aggregation Module (MAAM), a lightweight attention architecture integrated with the MindSpore framework. MAAM employs three parallel agent branches with independently parameterized operations to extract heterogeneous features, adaptively fused via learnable scalar weights, and refined through a convolutional compression layer. Leveraging MindSpore's dynamic computational graph and operator fusion, MAAM achieves 87.0% accuracy on the CIFAR-10 dataset, significantly outperforming conventional CNN (58.3%) and MLP (49.6%) models, while improving training efficiency by 30%. Ablation studies confirm the critical role of agent attention (accuracy drops to 32.0% if removed) and compression modules (25.5% if omitted), validating their necessity for maintaining discriminative feature learning. The framework's hardware acceleration capabilities and minimal memory footprint further demonstrate its practicality, offering a deployable solution for image classification in resource-constrained scenarios without compromising accuracy.
Achieving Tighter Finite-Time Rates for Heterogeneous Federated Stochastic Approximation under Markovian Sampling
Apr 15, 2025Motivated by collaborative reinforcement learning (RL) and optimization with time-correlated data, we study a generic federated stochastic approximation problem involving $M$ agents, where each agent is characterized by an agent-specific (potentially nonlinear) local operator. The goal is for the agents to communicate intermittently via a server to find the root of the average of the agents' local operators. The generality of our setting stems from allowing for (i) Markovian data at each agent and (ii) heterogeneity in the roots of the agents' local operators. The limited recent work that has accounted for both these features in a federated setting fails to guarantee convergence to the desired point or to show any benefit of collaboration; furthermore, they rely on projection steps in their algorithms to guarantee bounded iterates. Our work overcomes each of these limitations. We develop a novel algorithm titled \texttt{FedHSA}, and prove that it guarantees convergence to the correct point, while enjoying an $M$-fold linear speedup in sample-complexity due to collaboration. To our knowledge, \emph{this is the first finite-time result of its kind}, and establishing it (without relying on a projection step) entails a fairly intricate argument that accounts for the interplay between complex temporal correlations due to Markovian sampling, multiple local steps to save communication, and the drift-effects induced by heterogeneous local operators. Our results have implications for a broad class of heterogeneous federated RL problems (e.g., policy evaluation and control) with function approximation, where the agents' Markov decision processes can differ in their probability transition kernels and reward functions.
On the Suitability of Reinforcement Fine-Tuning to Visual Tasks
Apr 08, 2025
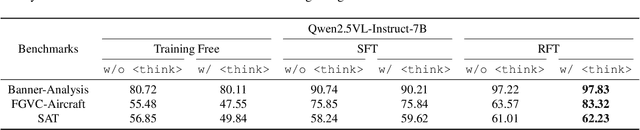
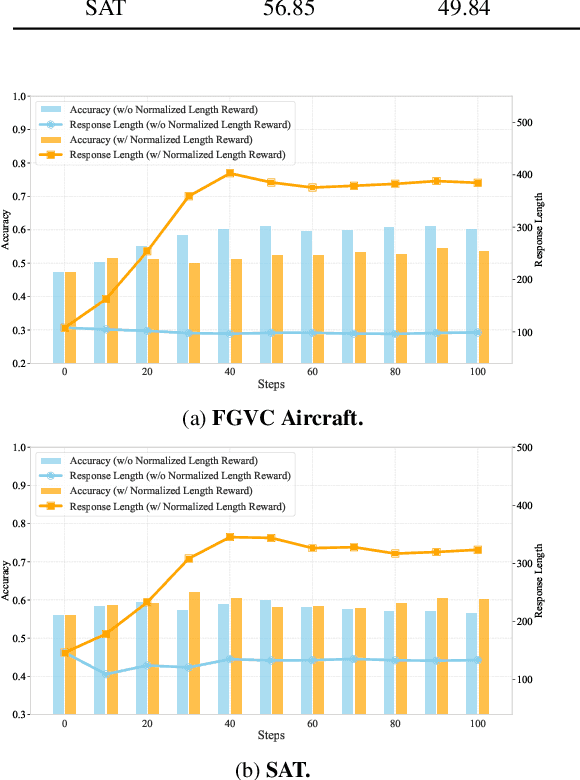
Reinforcement Fine-Tuning (RFT) is proved to be greatly valuable for enhancing the reasoning ability of LLMs. Researchers have been starting to apply RFT to MLLMs, hoping it will also enhance the capabilities of visual understanding. However, these works are at a very early stage and have not examined how suitable RFT actually is for visual tasks. In this work, we endeavor to understand the suitabilities and limitations of RFT for visual tasks, through experimental analysis and observations. We start by quantitative comparisons on various tasks, which shows RFT is generally better than SFT on visual tasks. %especially when the number of training samples are limited. To check whether such advantages are brought up by the reasoning process, we design a new reward that encourages the model to ``think'' more, whose results show more thinking can be beneficial for complicated tasks but harmful for simple tasks. We hope this study can provide more insight for the rapid advancements on this topic.
Re-Aligning Language to Visual Objects with an Agentic Workflow
Mar 30, 2025Language-based object detection (LOD) aims to align visual objects with language expressions. A large amount of paired data is utilized to improve LOD model generalizations. During the training process, recent studies leverage vision-language models (VLMs) to automatically generate human-like expressions for visual objects, facilitating training data scaling up. In this process, we observe that VLM hallucinations bring inaccurate object descriptions (e.g., object name, color, and shape) to deteriorate VL alignment quality. To reduce VLM hallucinations, we propose an agentic workflow controlled by an LLM to re-align language to visual objects via adaptively adjusting image and text prompts. We name this workflow Real-LOD, which includes planning, tool use, and reflection steps. Given an image with detected objects and VLM raw language expressions, Real-LOD reasons its state automatically and arranges action based on our neural symbolic designs (i.e., planning). The action will adaptively adjust the image and text prompts and send them to VLMs for object re-description (i.e., tool use). Then, we use another LLM to analyze these refined expressions for feedback (i.e., reflection). These steps are conducted in a cyclic form to gradually improve language descriptions for re-aligning to visual objects. We construct a dataset that contains a tiny amount of 0.18M images with re-aligned language expression and train a prevalent LOD model to surpass existing LOD methods by around 50% on the standard benchmarks. Our Real-LOD workflow, with automatic VL refinement, reveals a potential to preserve data quality along with scaling up data quantity, which further improves LOD performance from a data-alignment perspective.