 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGTR-Bench: Evaluating Geo-Temporal Reasoning in Vision-Language Models
Oct 09, 2025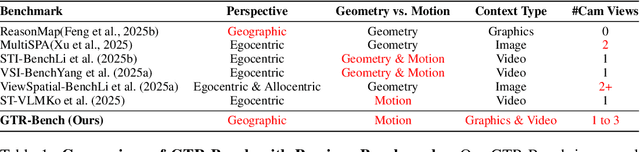
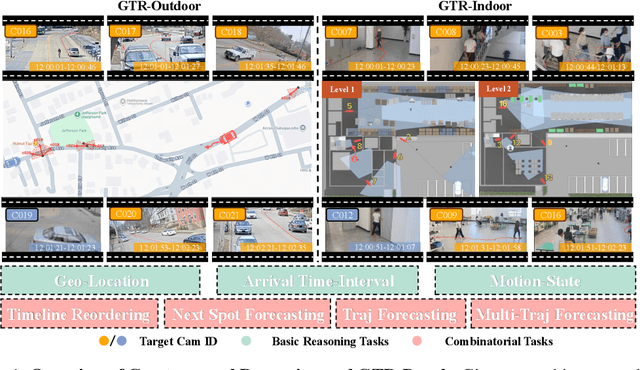
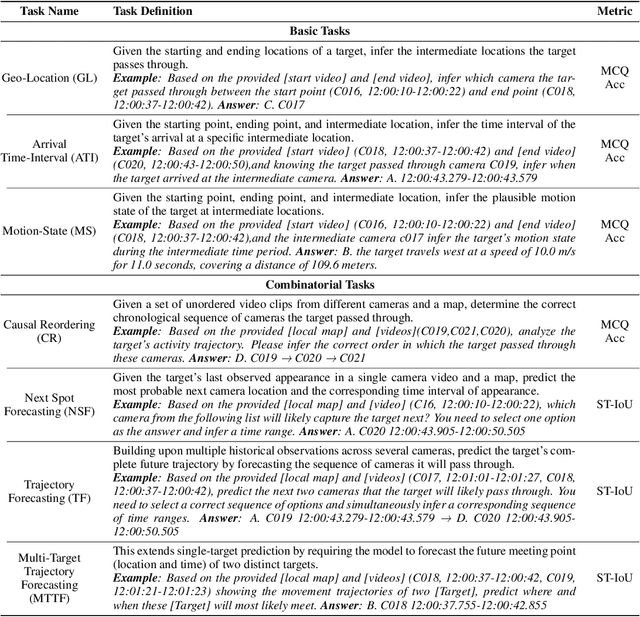
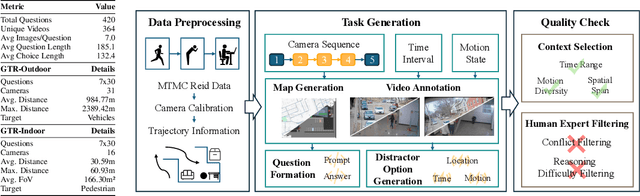
Recently spatial-temporal intelligence of Visual-Language Models (VLMs) has attracted much attention due to its importance for Autonomous Driving, Embodied AI and General Artificial Intelligence. Existing spatial-temporal benchmarks mainly focus on egocentric perspective reasoning with images/video context, or geographic perspective reasoning with graphics context (eg. a map), thus fail to assess VLMs' geographic spatial-temporal intelligence with both images/video and graphics context, which is important for areas like traffic management and emergency response. To address the gaps, we introduce Geo-Temporal Reasoning benchmark (GTR-Bench), a novel challenge for geographic temporal reasoning of moving targets in a large-scale camera network. GTR-Bench is more challenging as it requires multiple perspective switches between maps and videos, joint reasoning across multiple videos with non-overlapping fields of view, and inference over spatial-temporal regions that are unobserved by any video context. Evaluations of more than 10 popular VLMs on GTR-Bench demonstrate that even the best proprietary model, Gemini-2.5-Pro (34.9%), significantly lags behind human performance (78.61%) on geo-temporal reasoning. Moreover, our comprehensive analysis on GTR-Bench reveals three primary deficiencies of current models for geo-temporal reasoning. (1) VLMs' reasoning is impaired by an imbalanced utilization of spatial-temporal context. (2) VLMs are weak in temporal forecasting, which leads to worse performance on temporal-emphasized tasks than on spatial-emphasized tasks. (3) VLMs lack the proficiency to comprehend or align the map data with multi-view video inputs. We believe GTR-Bench offers valuable insights and opens up new opportunities for research and applications in spatial-temporal intelligence. Benchmark and code will be released at https://github.com/X-Luffy/GTR-Bench.
Re-Aligning Language to Visual Objects with an Agentic Workflow
Mar 30, 2025Language-based object detection (LOD) aims to align visual objects with language expressions. A large amount of paired data is utilized to improve LOD model generalizations. During the training process, recent studies leverage vision-language models (VLMs) to automatically generate human-like expressions for visual objects, facilitating training data scaling up. In this process, we observe that VLM hallucinations bring inaccurate object descriptions (e.g., object name, color, and shape) to deteriorate VL alignment quality. To reduce VLM hallucinations, we propose an agentic workflow controlled by an LLM to re-align language to visual objects via adaptively adjusting image and text prompts. We name this workflow Real-LOD, which includes planning, tool use, and reflection steps. Given an image with detected objects and VLM raw language expressions, Real-LOD reasons its state automatically and arranges action based on our neural symbolic designs (i.e., planning). The action will adaptively adjust the image and text prompts and send them to VLMs for object re-description (i.e., tool use). Then, we use another LLM to analyze these refined expressions for feedback (i.e., reflection). These steps are conducted in a cyclic form to gradually improve language descriptions for re-aligning to visual objects. We construct a dataset that contains a tiny amount of 0.18M images with re-aligned language expression and train a prevalent LOD model to surpass existing LOD methods by around 50% on the standard benchmarks. Our Real-LOD workflow, with automatic VL refinement, reveals a potential to preserve data quality along with scaling up data quantity, which further improves LOD performance from a data-alignment perspective.
InstructDET: Diversifying Referring Object Detection with Generalized Instructions
Oct 17, 2023We propose InstructDET, a data-centric method for referring object detection (ROD) that localizes target objects based on user instructions. While deriving from referring expressions (REC), the instructions we leverage are greatly diversified to encompass common user intentions related to object detection. For one image, we produce tremendous instructions that refer to every single object and different combinations of multiple objects. Each instruction and its corresponding object bounding boxes (bbxs) constitute one training data pair. In order to encompass common detection expressions, we involve emerging vision-language model (VLM) and large language model (LLM) to generate instructions guided by text prompts and object bbxs, as the generalizations of foundation models are effective to produce human-like expressions (e.g., describing object property, category, and relationship). We name our constructed dataset as InDET. It contains images, bbxs and generalized instructions that are from foundation models. Our InDET is developed from existing REC datasets and object detection datasets, with the expanding potential that any image with object bbxs can be incorporated through using our InstructDET method. By using our InDET dataset, we show that a conventional ROD model surpasses existing methods on standard REC datasets and our InDET test set. Our data-centric method InstructDET, with automatic data expansion by leveraging foundation models, directs a promising field that ROD can be greatly diversified to execute common object detection instructions.
Stabilized Medical Image Attacks
Mar 09, 2021

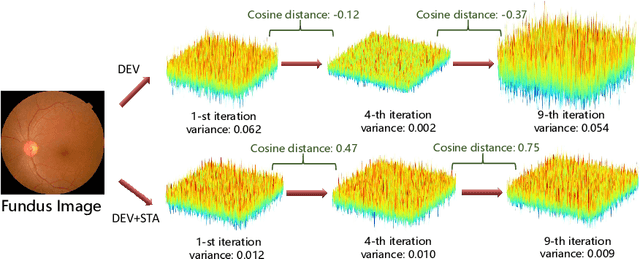
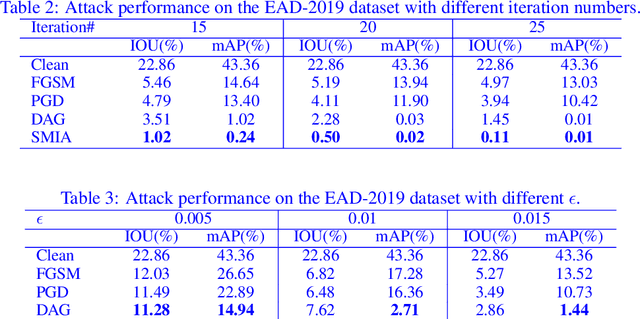
Convolutional Neural Networks (CNNs) have advanced existing medical systems for automatic disease diagnosis. However, a threat to these systems arises that adversarial attacks make CNNs vulnerable. Inaccurate diagnosis results make a negative influence on human healthcare. There is a need to investigate potential adversarial attacks to robustify deep medical diagnosis systems. On the other side, there are several modalities of medical images (e.g., CT, fundus, and endoscopic image) of which each type is significantly different from others. It is more challenging to generate adversarial perturbations for different types of medical images. In this paper, we propose an image-based medical adversarial attack method to consistently produce adversarial perturbations on medical images. The objective function of our method consists of a loss deviation term and a loss stabilization term. The loss deviation term increases the divergence between the CNN prediction of an adversarial example and its ground truth label. Meanwhile, the loss stabilization term ensures similar CNN predictions of this example and its smoothed input. From the perspective of the whole iterations for perturbation generation, the proposed loss stabilization term exhaustively searches the perturbation space to smooth the single spot for local optimum escape. We further analyze the KL-divergence of the proposed loss function and find that the loss stabilization term makes the perturbations updated towards a fixed objective spot while deviating from the ground truth. This stabilization ensures the proposed medical attack effective for different types of medical images while producing perturbations in small variance. Experiments on several medical image analysis benchmarks including the recent COVID-19 dataset show the stability of the proposed method.
GREEN: a Graph REsidual rE-ranking Network for Grading Diabetic Retinopathy
Jul 21, 2020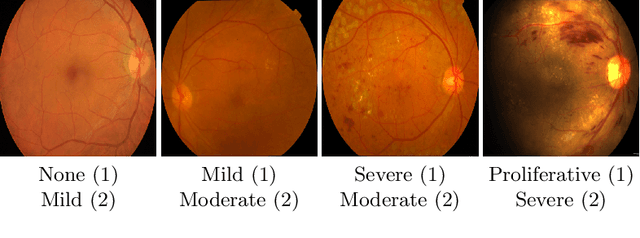
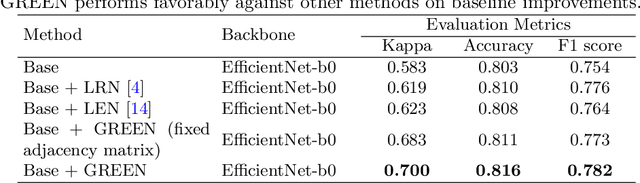
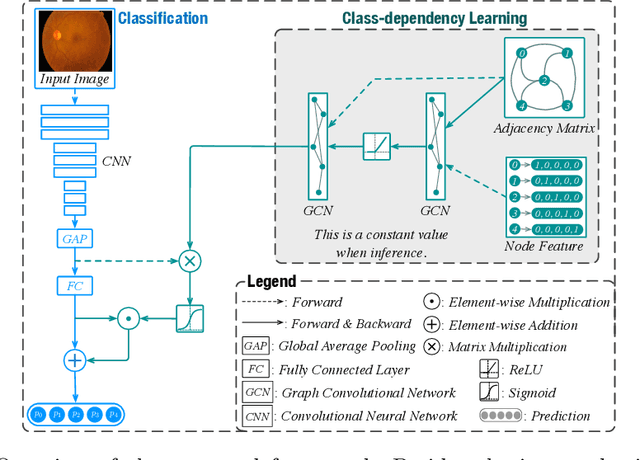
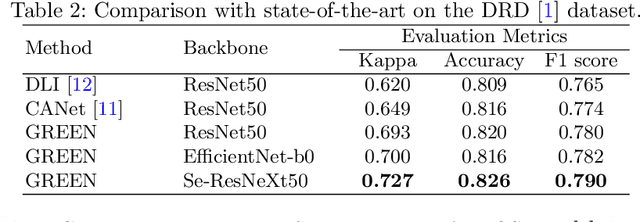
The automatic grading of diabetic retinopathy (DR) facilitates medical diagnosis for both patients and physicians. Existing researches formulate DR grading as an image classification problem. As the stages/categories of DR correlate with each other, the relationship between different classes cannot be explicitly described via a one-hot label because it is empirically estimated by different physicians with different outcomes. This class correlation limits existing networks to achieve effective classification. In this paper, we propose a Graph REsidual rE-ranking Network (GREEN) to introduce a class dependency prior into the original image classification network. The class dependency prior is represented by a graph convolutional network with an adjacency matrix. This prior augments image classification pipeline by re-ranking classification results in a residual aggregation manner. Experiments on the standard benchmarks have shown that GREEN performs favorably against state-of-the-art approaches.
Distractor-Aware Neuron Intrinsic Learning for Generic 2D Medical Image Classifications
Jul 21, 2020



Medical image analysis benefits Computer Aided Diagnosis (CADx). A fundamental analyzing approach is the classification of medical images, which serves for skin lesion diagnosis, diabetic retinopathy grading, and cancer classification on histological images. When learning these discriminative classifiers, we observe that the convolutional neural networks (CNNs) are vulnerable to distractor interference. This is due to the similar sample appearances from different categories (i.e., small inter-class distance). Existing attempts select distractors from input images by empirically estimating their potential effects to the classifier. The essences of how these distractors affect CNN classification are not known. In this paper, we explore distractors from the CNN feature space via proposing a neuron intrinsic learning method. We formulate a novel distractor-aware loss that encourages large distance between the original image and its distractor in the feature space. The novel loss is combined with the original classification loss to update network parameters by back-propagation. Neuron intrinsic learning first explores distractors crucial to the deep classifier and then uses them to robustify CNN inherently. Extensive experiments on medical image benchmark datasets indicate that the proposed method performs favorably against the state-of-the-art approaches.
Attentive CT Lesion Detection Using Deep Pyramid Inference with Multi-Scale Booster
Jul 09, 2019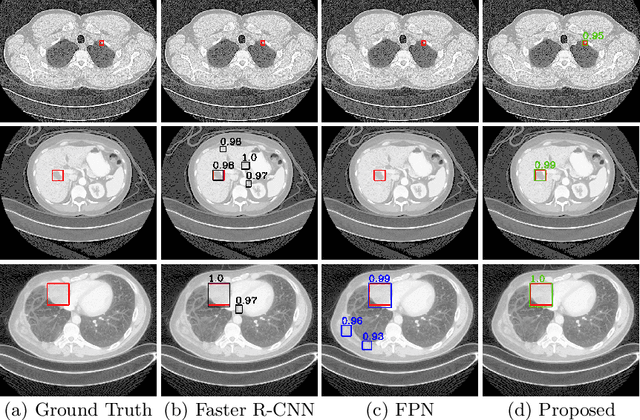
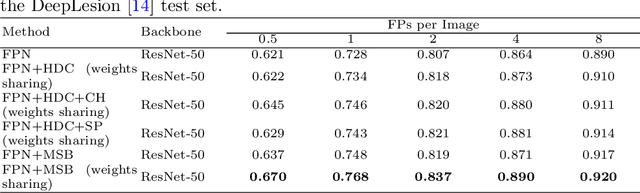
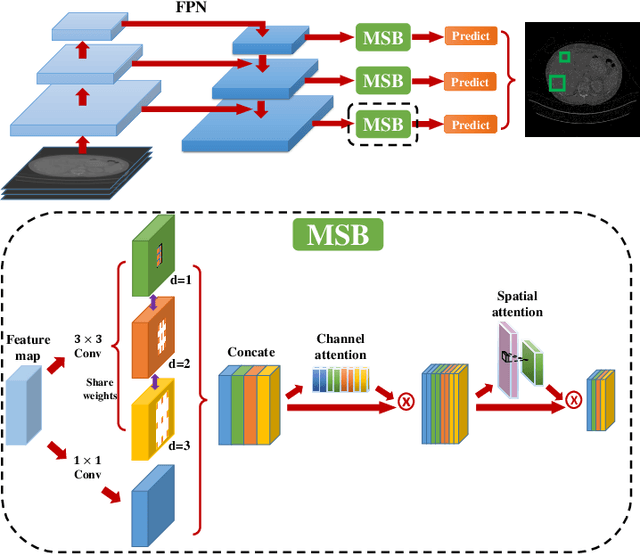
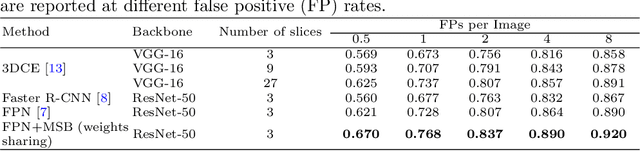
Accurate lesion detection in computer tomography (CT) slices benefits pathologic organ analysis in the medical diagnosis process. More recently, it has been tackled as an object detection problem using the Convolutional Neural Networks (CNNs). Despite the achievements from off-the-shelf CNN models, the current detection accuracy is limited by the inability of CNNs on lesions at vastly different scales. In this paper, we propose a Multi-Scale Booster (MSB) with channel and spatial attention integrated into the backbone Feature Pyramid Network (FPN). In each pyramid level, the proposed MSB captures fine-grained scale variations by using Hierarchically Dilated Convolutions (HDC). Meanwhile, the proposed channel and spatial attention modules increase the network's capability of selecting relevant features response for lesion detection. Extensive experiments on the DeepLesion benchmark dataset demonstrate that the proposed method performs superiorly against state-of-the-art approaches.
Joint Face Hallucination and Deblurring via Structure Generation and Detail Enhancement
Nov 22, 2018



We address the problem of restoring a high-resolution face image from a blurry low-resolution input. This problem is difficult as super-resolution and deblurring need to be tackled simultaneously. Moreover, existing algorithms cannot handle face images well as low-resolution face images do not have much texture which is especially critical for deblurring. In this paper, we propose an effective algorithm by utilizing the domain-specific knowledge of human faces to recover high-quality faces. We first propose a facial component guided deep Convolutional Neural Network (CNN) to restore a coarse face image, which is denoted as the base image where the facial component is automatically generated from the input face image. However, the CNN based method cannot handle image details well. We further develop a novel exemplar-based detail enhancement algorithm via facial component matching. Extensive experiments show that the proposed method outperforms the state-of-the-art algorithms both quantitatively and qualitatively.
VITAL: VIsual Tracking via Adversarial Learning
Apr 12, 2018
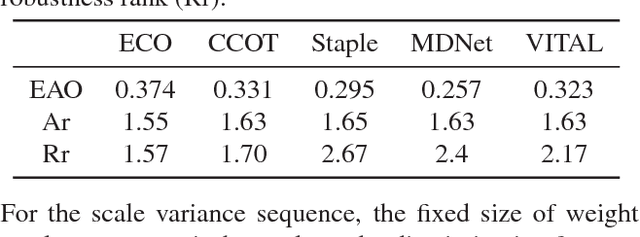

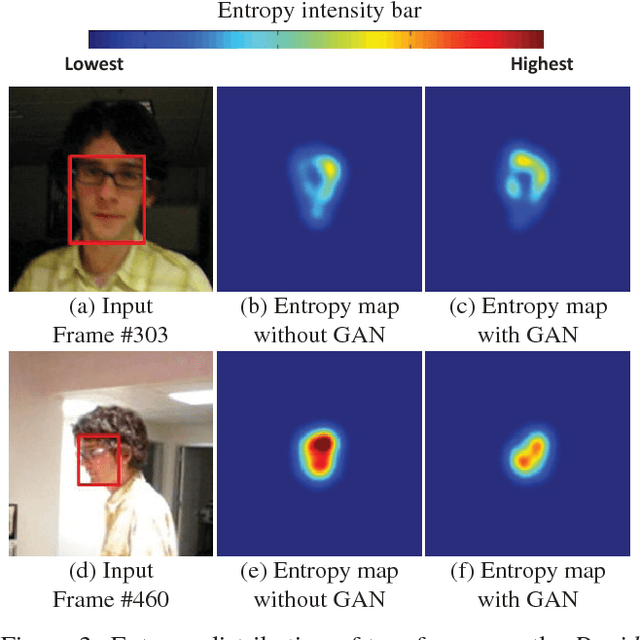
The tracking-by-detection framework consists of two stages, i.e., drawing samples around the target object in the first stage and classifying each sample as the target object or as background in the second stage. The performance of existing trackers using deep classification networks is limited by two aspects. First, the positive samples in each frame are highly spatially overlapped, and they fail to capture rich appearance variations. Second, there exists extreme class imbalance between positive and negative samples. This paper presents the VITAL algorithm to address these two problems via adversarial learning. To augment positive samples, we use a generative network to randomly generate masks, which are applied to adaptively dropout input features to capture a variety of appearance changes. With the use of adversarial learning, our network identifies the mask that maintains the most robust features of the target objects over a long temporal span. In addition, to handle the issue of class imbalance, we propose a high-order cost sensitive loss to decrease the effect of easy negative samples to facilitate training the classification network. Extensive experiments on benchmark datasets demonstrate that the proposed tracker performs favorably against state-of-the-art approaches.
CREST: Convolutional Residual Learning for Visual Tracking
Aug 01, 2017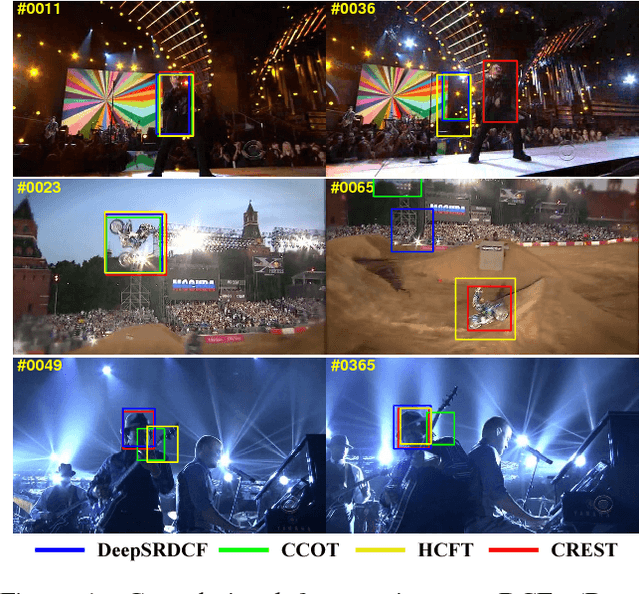
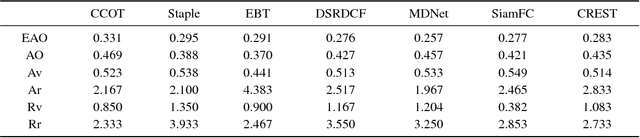
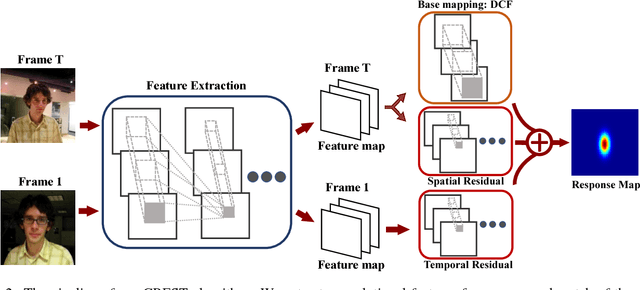
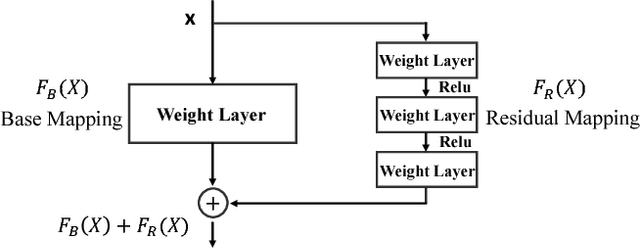
Discriminative correlation filters (DCFs) have been shown to perform superiorly in visual tracking. They only need a small set of training samples from the initial frame to generate an appearance model. However, existing DCFs learn the filters separately from feature extraction, and update these filters using a moving average operation with an empirical weight. These DCF trackers hardly benefit from the end-to-end training. In this paper, we propose the CREST algorithm to reformulate DCFs as a one-layer convolutional neural network. Our method integrates feature extraction, response map generation as well as model update into the neural networks for an end-to-end training. To reduce model degradation during online update, we apply residual learning to take appearance changes into account. Extensive experiments on the benchmark datasets demonstrate that our CREST tracker performs favorably against state-of-the-art trackers.