 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark and Multi-Agent System for Instruction-driven Cinematic Video Compilation
Apr 12, 2026The surging demand for adapting long-form cinematic content into short videos has motivated the need for versatile automatic video compilation systems. However, existing compilation methods are limited to predefined tasks, and the community lacks a comprehensive benchmark to evaluate the cinematic compilation. To address this, we introduce CineBench, the first benchmark for instruction-driven cinematic video compilation, featuring diverse user instructions and high-quality ground-truth compilations annotated by professional editors. To overcome contextual collapse and temporal fragmentation, we present CineAgents, a multi-agent system that reformulates cinematic video compilation into ``design-and-compose'' paradigm. CineAgents performs script reverse-engineering to construct a hierarchical narrative memory to provide multi-level context and employs an iterative narrative planning process that refines a creative blueprint into a final compiled script. Extensive experiments demonstrate that CineAgents significantly outperforms existing methods, generating compilations with superior narrative coherence and logical coherence.
Learning Shape Priors by Pairwise Comparison for Robust Semantic Segmentation
Apr 23, 2022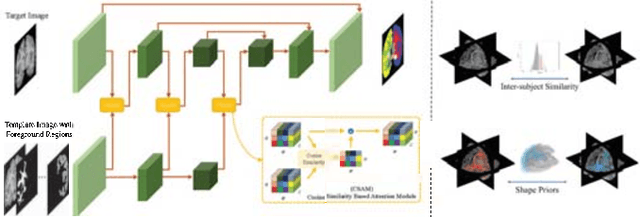
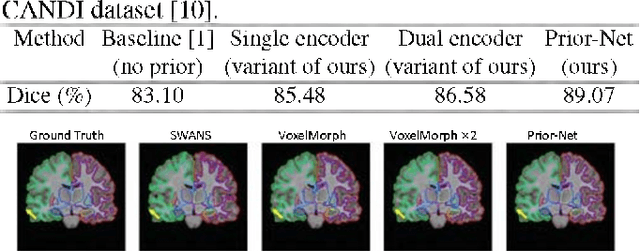
Semantic segmentation is important in medical image analysis. Inspired by the strong ability of traditional image analysis techniques in capturing shape priors and inter-subject similarity, many deep learning (DL) models have been recently proposed to exploit such prior information and achieved robust performance. However, these two types of important prior information are usually studied separately in existing models. In this paper, we propose a novel DL model to model both type of priors within a single framework. Specifically, we introduce an extra encoder into the classic encoder-decoder structure to form a Siamese structure for the encoders, where one of them takes a target image as input (the image-encoder), and the other concatenates a template image and its foreground regions as input (the template-encoder). The template-encoder encodes the shape priors and appearance characteristics of each foreground class in the template image. A cosine similarity based attention module is proposed to fuse the information from both encoders, to utilize both types of prior information encoded by the template-encoder and model the inter-subject similarity for each foreground class. Extensive experiments on two public datasets demonstrate that our proposed method can produce superior performance to competing methods.
Generalized Organ Segmentation by Imitating One-shot Reasoning using Anatomical Correlation
Mar 30, 2021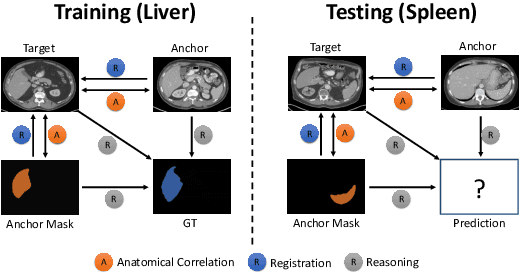
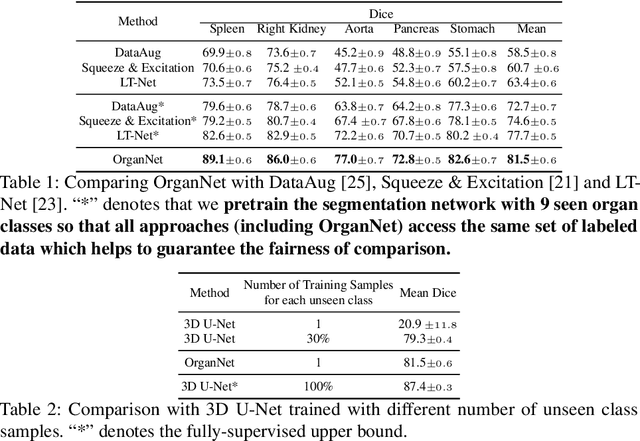
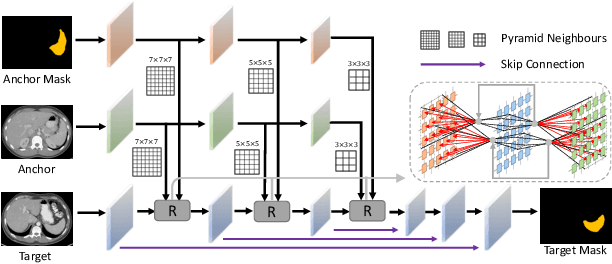
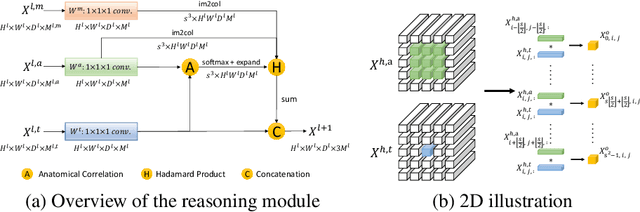
Learning by imitation is one of the most significant abilities of human beings and plays a vital role in human's computational neural system. In medical image analysis, given several exemplars (anchors), experienced radiologist has the ability to delineate unfamiliar organs by imitating the reasoning process learned from existing types of organs. Inspired by this observation, we propose OrganNet which learns a generalized organ concept from a set of annotated organ classes and then transfer this concept to unseen classes. In this paper, we show that such process can be integrated into the one-shot segmentation task which is a very challenging but meaningful topic. We propose pyramid reasoning modules (PRMs) to model the anatomical correlation between anchor and target volumes. In practice, the proposed module first computes a correlation matrix between target and anchor computerized tomography (CT) volumes. Then, this matrix is used to transform the feature representations of both anchor volume and its segmentation mask. Finally, OrganNet learns to fuse the representations from various inputs and predicts segmentation results for target volume. Extensive experiments show that OrganNet can effectively resist the wide variations in organ morphology and produce state-of-the-art results in one-shot segmentation task. Moreover, even when compared with fully-supervised segmentation models, OrganNet is still able to produce satisfying segmentation results.
An Industry Evaluation of Embedding-based Entity Alignment
Nov 07, 2020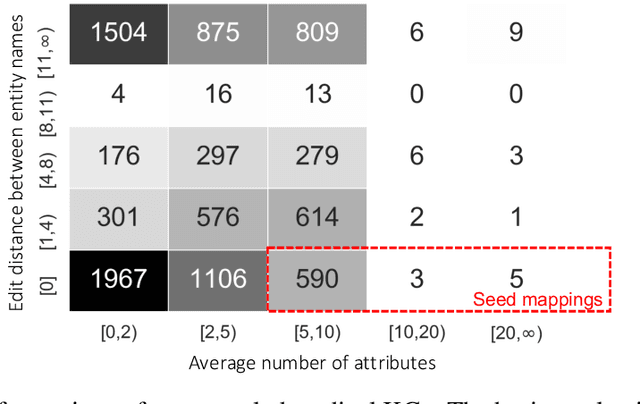

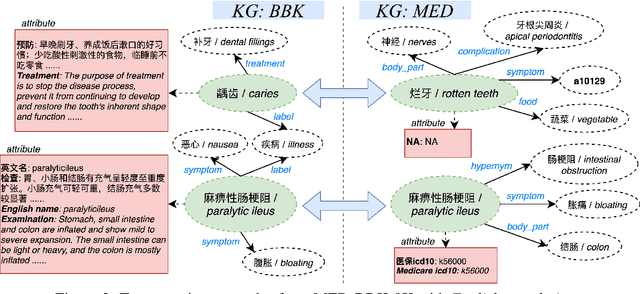
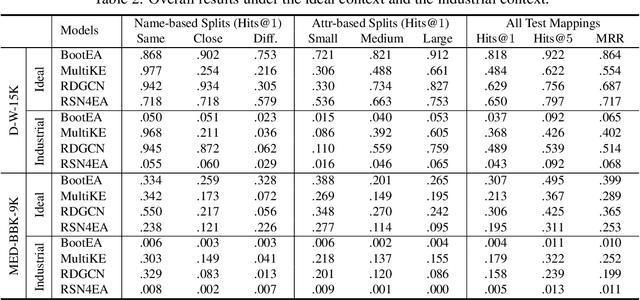
Embedding-based entity alignment has been widely investigated in recent years, but most proposed methods still rely on an ideal supervised learning setting with a large number of unbiased seed mappings for training and validation, which significantly limits their usage. In this study, we evaluate those state-of-the-art methods in an industrial context, where the impact of seed mappings with different sizes and different biases is explored. Besides the popular benchmarks from DBpedia and Wikidata, we contribute and evaluate a new industrial benchmark that is extracted from two heterogeneous knowledge graphs (KGs) under deployment for medical applications. The experimental results enable the analysis of the advantages and disadvantages of these alignment methods and the further discussion of suitable strategies for their industrial deployment.
Attentive CT Lesion Detection Using Deep Pyramid Inference with Multi-Scale Booster
Jul 09, 2019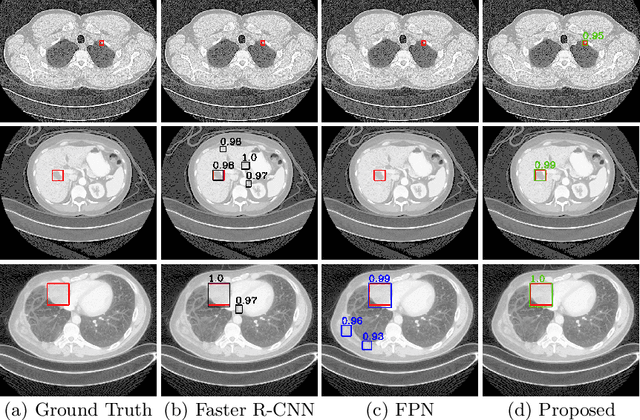
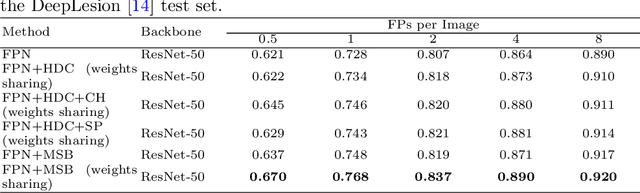
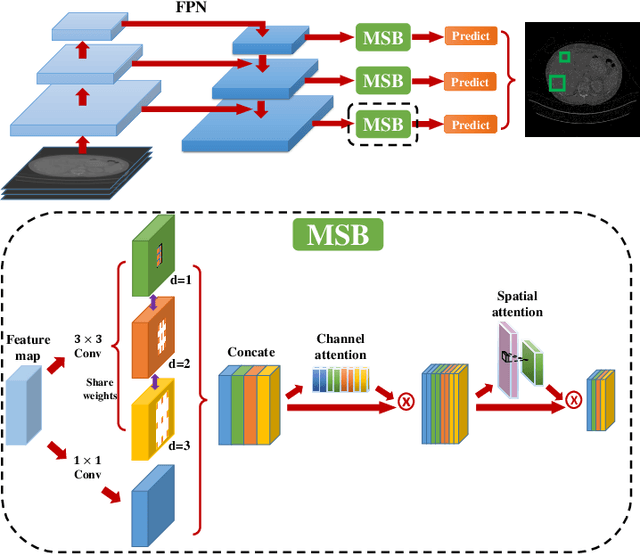
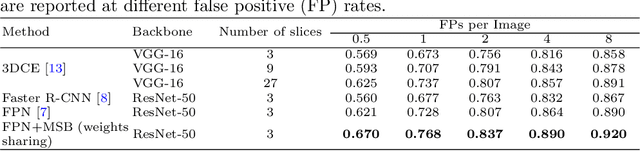
Accurate lesion detection in computer tomography (CT) slices benefits pathologic organ analysis in the medical diagnosis process. More recently, it has been tackled as an object detection problem using the Convolutional Neural Networks (CNNs). Despite the achievements from off-the-shelf CNN models, the current detection accuracy is limited by the inability of CNNs on lesions at vastly different scales. In this paper, we propose a Multi-Scale Booster (MSB) with channel and spatial attention integrated into the backbone Feature Pyramid Network (FPN). In each pyramid level, the proposed MSB captures fine-grained scale variations by using Hierarchically Dilated Convolutions (HDC). Meanwhile, the proposed channel and spatial attention modules increase the network's capability of selecting relevant features response for lesion detection. Extensive experiments on the DeepLesion benchmark dataset demonstrate that the proposed method performs superiorly against state-of-the-art approaches.