 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegionReasoner: Region-Grounded Multi-Round Visual Reasoning
Feb 03, 2026Large vision-language models have achieved remarkable progress in visual reasoning, yet most existing systems rely on single-step or text-only reasoning, limiting their ability to iteratively refine understanding across multiple visual contexts. To address this limitation, we introduce a new multi-round visual reasoning benchmark with training and test sets spanning both detection and segmentation tasks, enabling systematic evaluation under iterative reasoning scenarios. We further propose RegionReasoner, a reinforcement learning framework that enforces grounded reasoning by requiring each reasoning trace to explicitly cite the corresponding reference bounding boxes, while maintaining semantic coherence via a global-local consistency reward. This reward extracts key objects and nouns from both global scene captions and region-level captions, aligning them with the reasoning trace to ensure consistency across reasoning steps. RegionReasoner is optimized with structured rewards combining grounding fidelity and global-local semantic alignment. Experiments on detection and segmentation tasks show that RegionReasoner-7B, together with our newly introduced benchmark RegionDial-Bench, considerably improves multi-round reasoning accuracy, spatial grounding precision, and global-local consistency, establishing a strong baseline for this emerging research direction.
Attention Needs to Focus: A Unified Perspective on Attention Allocation
Jan 07, 2026The Transformer architecture, a cornerstone of modern Large Language Models (LLMs), has achieved extraordinary success in sequence modeling, primarily due to its attention mechanism. However, despite its power, the standard attention mechanism is plagued by well-documented issues: representational collapse and attention sink. Although prior work has proposed approaches for these issues, they are often studied in isolation, obscuring their deeper connection. In this paper, we present a unified perspective, arguing that both can be traced to a common root -- improper attention allocation. We identify two failure modes: 1) Attention Overload, where tokens receive comparable high weights, blurring semantic features that lead to representational collapse; 2) Attention Underload, where no token is semantically relevant, yet attention is still forced to distribute, resulting in spurious focus such as attention sink. Building on this insight, we introduce Lazy Attention, a novel mechanism designed for a more focused attention distribution. To mitigate overload, it employs positional discrimination across both heads and dimensions to sharpen token distinctions. To counteract underload, it incorporates Elastic-Softmax, a modified normalization function that relaxes the standard softmax constraint to suppress attention on irrelevant tokens. Experiments on the FineWeb-Edu corpus, evaluated across nine diverse benchmarks, demonstrate that Lazy Attention successfully mitigates attention sink and achieves competitive performance compared to both standard attention and modern architectures, while reaching up to 59.58% attention sparsity.
Unveiling and Bridging the Functional Perception Gap in MLLMs: Atomic Visual Alignment and Hierarchical Evaluation via PET-Bench
Jan 06, 2026While Multimodal Large Language Models (MLLMs) have demonstrated remarkable proficiency in tasks such as abnormality detection and report generation for anatomical modalities, their capability in functional imaging remains largely unexplored. In this work, we identify and quantify a fundamental functional perception gap: the inability of current vision encoders to decode functional tracer biodistribution independent of morphological priors. Identifying Positron Emission Tomography (PET) as the quintessential modality to investigate this disconnect, we introduce PET-Bench, the first large-scale functional imaging benchmark comprising 52,308 hierarchical QA pairs from 9,732 multi-site, multi-tracer PET studies. Extensive evaluation of 19 state-of-the-art MLLMs reveals a critical safety hazard termed the Chain-of-Thought (CoT) hallucination trap. We observe that standard CoT prompting, widely considered to enhance reasoning, paradoxically decouples linguistic generation from visual evidence in PET, producing clinically fluent but factually ungrounded diagnoses. To resolve this, we propose Atomic Visual Alignment (AVA), a simple fine-tuning strategy that enforces the mastery of low-level functional perception prior to high-level diagnostic reasoning. Our results demonstrate that AVA effectively bridges the perception gap, transforming CoT from a source of hallucination into a robust inference tool and improving diagnostic accuracy by up to 14.83%. Code and data are available at https://github.com/yezanting/PET-Bench.
VPTracker: Global Vision-Language Tracking via Visual Prompt and MLLM
Dec 28, 2025Vision-Language Tracking aims to continuously localize objects described by a visual template and a language description. Existing methods, however, are typically limited to local search, making them prone to failures under viewpoint changes, occlusions, and rapid target movements. In this work, we introduce the first global tracking framework based on Multimodal Large Language Models (VPTracker), exploiting their powerful semantic reasoning to locate targets across the entire image space. While global search improves robustness and reduces drift, it also introduces distractions from visually or semantically similar objects. To address this, we propose a location-aware visual prompting mechanism that incorporates spatial priors into the MLLM. Specifically, we construct a region-level prompt based on the target's previous location, enabling the model to prioritize region-level recognition and resort to global inference only when necessary. This design retains the advantages of global tracking while effectively suppressing interference from distracting visual content. Extensive experiments show that our approach significantly enhances tracking stability and target disambiguation under challenging scenarios, opening a new avenue for integrating MLLMs into visual tracking. Code is available at https://github.com/jcwang0602/VPTracker.
X-ray Insights Unleashed: Pioneering the Enhancement of Multi-Label Long-Tail Data
Dec 24, 2025Long-tailed pulmonary anomalies in chest radiography present formidable diagnostic challenges. Despite the recent strides in diffusion-based methods for enhancing the representation of tailed lesions, the paucity of rare lesion exemplars curtails the generative capabilities of these approaches, thereby leaving the diagnostic precision less than optimal. In this paper, we propose a novel data synthesis pipeline designed to augment tail lesions utilizing a copious supply of conventional normal X-rays. Specifically, a sufficient quantity of normal samples is amassed to train a diffusion model capable of generating normal X-ray images. This pre-trained diffusion model is subsequently utilized to inpaint the head lesions present in the diseased X-rays, thereby preserving the tail classes as augmented training data. Additionally, we propose the integration of a Large Language Model Knowledge Guidance (LKG) module alongside a Progressive Incremental Learning (PIL) strategy to stabilize the inpainting fine-tuning process. Comprehensive evaluations conducted on the public lung datasets MIMIC and CheXpert demonstrate that the proposed method sets a new benchmark in performance.
Learning Representation and Synergy Invariances: A Povable Framework for Generalized Multimodal Face Anti-Spoofing
Nov 18, 2025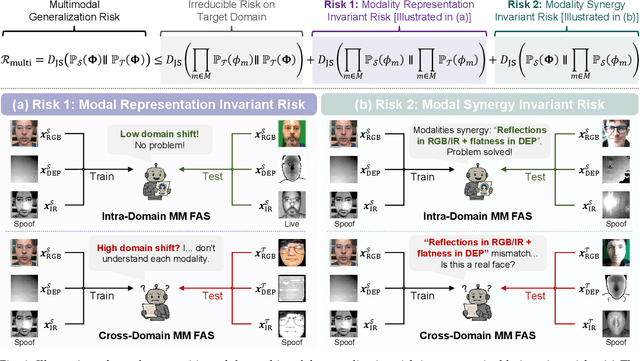

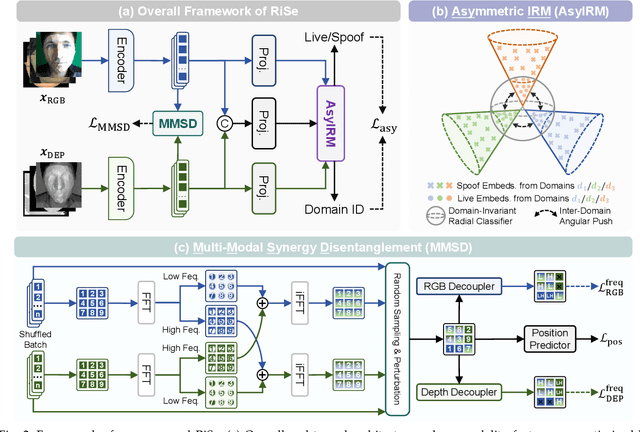
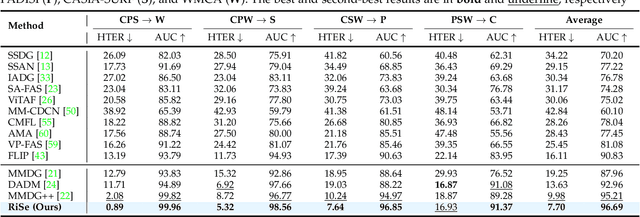
Multimodal Face Anti-Spoofing (FAS) methods, which integrate multiple visual modalities, often suffer even more severe performance degradation than unimodal FAS when deployed in unseen domains. This is mainly due to two overlooked risks that affect cross-domain multimodal generalization. The first is the modal representation invariant risk, i.e., whether representations remain generalizable under domain shift. We theoretically show that the inherent class asymmetry in FAS (diverse spoofs vs. compact reals) enlarges the upper bound of generalization error, and this effect is further amplified in multimodal settings. The second is the modal synergy invariant risk, where models overfit to domain-specific inter-modal correlations. Such spurious synergy cannot generalize to unseen attacks in target domains, leading to performance drops. To solve these issues, we propose a provable framework, namely Multimodal Representation and Synergy Invariance Learning (RiSe). For representation risk, RiSe introduces Asymmetric Invariant Risk Minimization (AsyIRM), which learns an invariant spherical decision boundary in radial space to fit asymmetric distributions, while preserving domain cues in angular space. For synergy risk, RiSe employs Multimodal Synergy Disentanglement (MMSD), a self-supervised task enhancing intrinsic, generalizable modal features via cross-sample mixing and disentanglement. Theoretical analysis and experiments verify RiSe, which achieves state-of-the-art cross-domain performance.
Unlocking the Potential of MLLMs in Referring Expression Segmentation via a Light-weight Mask Decode
Aug 06, 2025Reference Expression Segmentation (RES) aims to segment image regions specified by referring expressions and has become popular with the rise of multimodal large models (MLLMs). While MLLMs excel in semantic understanding, their token-generation paradigm struggles with pixel-level dense prediction. Existing RES methods either couple MLLMs with the parameter-heavy Segment Anything Model (SAM) with 632M network parameters or adopt SAM-free lightweight pipelines that sacrifice accuracy. To address the trade-off between performance and cost, we specifically propose MLLMSeg, a novel framework that fully exploits the inherent visual detail features encoded in the MLLM vision encoder without introducing an extra visual encoder. Besides, we propose a detail-enhanced and semantic-consistent feature fusion module (DSFF) that fully integrates the detail-related visual feature with the semantic-related feature output by the large language model (LLM) of MLLM. Finally, we establish a light-weight mask decoder with only 34M network parameters that optimally leverages detailed spatial features from the visual encoder and semantic features from the LLM to achieve precise mask prediction. Extensive experiments demonstrate that our method generally surpasses both SAM-based and SAM-free competitors, striking a better balance between performance and cost. Code is available at https://github.com/jcwang0602/MLLMSeg.
A Multi-Expert Structural-Semantic Hybrid Framework for Unveiling Historical Patterns in Temporal Knowledge Graphs
Jun 17, 2025Temporal knowledge graph reasoning aims to predict future events with knowledge of existing facts and plays a key role in various downstream tasks. Previous methods focused on either graph structure learning or semantic reasoning, failing to integrate dual reasoning perspectives to handle different prediction scenarios. Moreover, they lack the capability to capture the inherent differences between historical and non-historical events, which limits their generalization across different temporal contexts. To this end, we propose a Multi-Expert Structural-Semantic Hybrid (MESH) framework that employs three kinds of expert modules to integrate both structural and semantic information, guiding the reasoning process for different events. Extensive experiments on three datasets demonstrate the effectiveness of our approach.
Training-free LLM Merging for Multi-task Learning
Jun 14, 2025



Large Language Models (LLMs) have demonstrated exceptional capabilities across diverse natural language processing (NLP) tasks. The release of open-source LLMs like LLaMA and Qwen has triggered the development of numerous fine-tuned models tailored for various tasks and languages. In this paper, we explore an important question: is it possible to combine these specialized models to create a unified model with multi-task capabilities. We introduces Hierarchical Iterative Merging (Hi-Merging), a training-free method for unifying different specialized LLMs into a single model. Specifically, Hi-Merging employs model-wise and layer-wise pruning and scaling, guided by contribution analysis, to mitigate parameter conflicts. Extensive experiments on multiple-choice and question-answering tasks in both Chinese and English validate Hi-Merging's ability for multi-task learning. The results demonstrate that Hi-Merging consistently outperforms existing merging techniques and surpasses the performance of models fine-tuned on combined datasets in most scenarios. Code is available at: https://github.com/Applied-Machine-Learning-Lab/Hi-Merging.
* 14 pages, 6 figures
Model Merging for Knowledge Editing
Jun 14, 2025Large Language Models (LLMs) require continuous updates to maintain accurate and current knowledge as the world evolves. While existing knowledge editing approaches offer various solutions for knowledge updating, they often struggle with sequential editing scenarios and harm the general capabilities of the model, thereby significantly hampering their practical applicability. This paper proposes a two-stage framework combining robust supervised fine-tuning (R-SFT) with model merging for knowledge editing. Our method first fine-tunes the LLM to internalize new knowledge fully, then merges the fine-tuned model with the original foundation model to preserve newly acquired knowledge and general capabilities. Experimental results demonstrate that our approach significantly outperforms existing methods in sequential editing while better preserving the original performance of the model, all without requiring any architectural changes. Code is available at: https://github.com/Applied-Machine-Learning-Lab/MM4KE.
* 11 pages, 3 figures