 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Tool Use via Fission-GRPO: Learning to Recover from Execution Errors
Jan 22, 2026Large language models (LLMs) can call tools effectively, yet they remain brittle in multi-turn execution: following a tool call error, smaller models often degenerate into repetitive invalid re-invocations, failing to interpret error feedback and self-correct. This brittleness hinders reliable real-world deployment, where the execution errors are inherently inevitable during tool interaction procedures. We identify a key limitation of current approaches: standard reinforcement learning (RL) treats errors as sparse negative rewards, providing no guidance on how to recover, while pre-collected synthetic error-correction datasets suffer from distribution mismatch with the model's on-policy error modes. To bridge this gap, we propose Fission-GRPO, a framework that converts execution errors into corrective supervision within the RL training loop. Our core mechanism fissions each failed trajectory into a new training instance by augmenting it with diagnostic feedback from a finetuned Error Simulator, then resampling recovery rollouts on-policy. This enables the model to learn from the precise errors it makes during exploration, rather than from static, pre-collected error cases. On the BFCL v4 Multi-Turn, Fission-GRPO improves the error recovery rate of Qwen3-8B by 5.7% absolute, crucially, yielding a 4% overall accuracy gain (42.75% to 46.75%) over GRPO and outperforming specialized tool-use agents.
Memory-T1: Reinforcement Learning for Temporal Reasoning in Multi-session Agents
Dec 23, 2025Temporal reasoning over long, multi-session dialogues is a critical capability for conversational agents. However, existing works and our pilot study have shown that as dialogue histories grow in length and accumulate noise, current long-context models struggle to accurately identify temporally pertinent information, significantly impairing reasoning performance. To address this, we introduce Memory-T1, a framework that learns a time-aware memory selection policy using reinforcement learning (RL). It employs a coarse-to-fine strategy, first pruning the dialogue history into a candidate set using temporal and relevance filters, followed by an RL agent that selects the precise evidence sessions. The RL training is guided by a multi-level reward function optimizing (i) answer accuracy, (ii) evidence grounding, and (iii) temporal consistency. In particular, the temporal consistency reward provides a dense signal by evaluating alignment with the query time scope at both the session-level (chronological proximity) and the utterance-level (chronological fidelity), enabling the agent to resolve subtle chronological ambiguities. On the Time-Dialog benchmark, Memory-T1 boosts a 7B model to an overall score of 67.0\%, establishing a new state-of-the-art performance for open-source models and outperforming a 14B baseline by 10.2\%. Ablation studies show temporal consistency and evidence grounding rewards jointly contribute to a 15.0\% performance gain. Moreover, Memory-T1 maintains robustness up to 128k tokens, where baseline models collapse, proving effectiveness against noise in extensive dialogue histories. The code and datasets are publicly available at https://github.com/Elvin-Yiming-Du/Memory-T1/
Dual-Density Inference for Efficient Language Model Reasoning
Dec 17, 2025
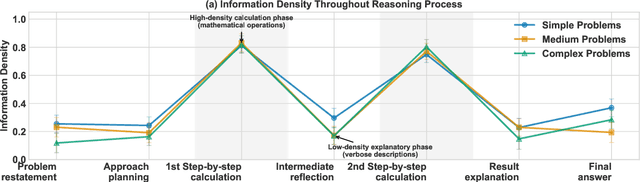
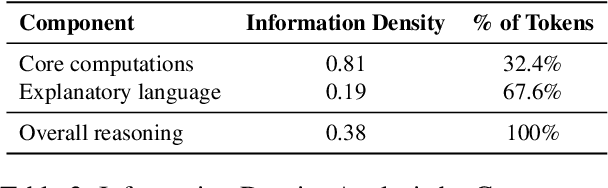
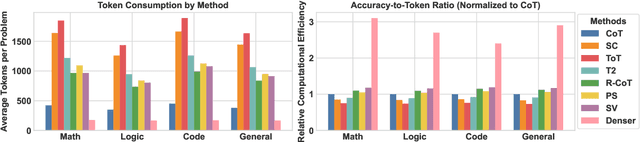
Large Language Models (LLMs) have shown impressive capabilities in complex reasoning tasks. However, current approaches employ uniform language density for both intermediate reasoning and final answers, leading to computational inefficiency. Our observation found that reasoning process serves a computational function for the model itself, while answering serves a communicative function for human understanding. This distinction enables the use of compressed, symbol-rich language for intermediate computations while maintaining human-readable final explanations. To address this inefficiency, we present Denser: \underline{D}ual-d\underline{ens}ity inf\underline{er}ence, a novel framework that optimizes information density separately for reasoning and answering phases. Our framework implements this through three components: a query processing module that analyzes input problems, a high-density compressed reasoning mechanism for efficient intermediate computations, and an answer generation component that translates compressed reasoning into human-readable solutions. Experimental evaluation across multiple reasoning question answering benchmarks demonstrates that Denser reduces token consumption by up to 62\% compared to standard Chain-of-Thought methods while preserving or improving accuracy. These efficiency gains are particularly significant for complex multi-step reasoning problems where traditional methods generate extensive explanations.
Hybrid Attribution Priors for Explainable and Robust Model Training
Dec 09, 2025Small language models (SLMs) are widely used in tasks that require low latency and lightweight deployment, particularly classification. As interpretability and robustness gain increasing importance, explanation-guided learning has emerged as an effective framework by introducing attribution-based supervision during training; however, deriving general and reliable attribution priors remains a significant challenge. Through an analysis of representative attribution methods in classification settings, we find that although these methods can reliably highlight class-relevant tokens, they often focus on common keywords shared by semantically similar classes. Because such classes are already difficult to distinguish under standard training, these attributions provide insufficient discriminative cues, limiting their ability to improve model differentiation. To overcome this limitation, we propose Class-Aware Attribution Prior (CAP), a novel attribution prior extraction framework that guides language models toward capturing fine-grained class distinctions and producing more salient, discriminative attribution priors. Building on this idea, we further introduce CAP Hybrid, which combines priors from CAP with those from existing attribution techniques to form a more comprehensive and balanced supervisory signal. By aligning a model's self-attribution with these enriched priors, our approach encourages the learning of diverse, decision-relevant features. Extensive experiments in full-data, few-shot, and adversarial scenarios demonstrate that our method consistently enhances both interpretability and robustness.
Explore to Evolve: Scaling Evolved Aggregation Logic via Proactive Online Exploration for Deep Research Agents
Oct 16, 2025Deep research web agents not only retrieve information from diverse sources such as web environments, files, and multimodal inputs, but more importantly, they need to rigorously analyze and aggregate knowledge for insightful research. However, existing open-source deep research agents predominantly focus on enhancing information-seeking capabilities of web agents to locate specific information, while overlooking the essential need for information aggregation, which would limit their ability to support in-depth research. We propose an Explore to Evolve paradigm to scalably construct verifiable training data for web agents. Begins with proactive online exploration, an agent sources grounded information by exploring the real web. Using the collected evidence, the agent then self-evolves an aggregation program by selecting, composing, and refining operations from 12 high-level logical types to synthesize a verifiable QA pair. This evolution from high-level guidance to concrete operations allowed us to scalably produce WebAggregatorQA, a dataset of 10K samples across 50K websites and 11 domains. Based on an open-source agent framework, SmolAgents, we collect supervised fine-tuning trajectories to develop a series of foundation models, WebAggregator. WebAggregator-8B matches the performance of GPT-4.1, while the 32B variant surpasses GPT-4.1 by more than 10% on GAIA-text and closely approaches Claude-3.7-sonnet. Moreover, given the limited availability of benchmarks that evaluate web agents' information aggregation abilities, we construct a human-annotated evaluation split of WebAggregatorQA as a challenging test set. On this benchmark, Claude-3.7-sonnet only achieves 28%, and GPT-4.1 scores 25.8%. Even when agents manage to retrieve all references, they still struggle on WebAggregatorQA, highlighting the need to strengthen the information aggregation capabilities of web agent foundations.
Beyond Two-Stage Training: Cooperative SFT and RL for LLM Reasoning
Sep 08, 2025Reinforcement learning (RL) has proven effective in incentivizing the reasoning abilities of large language models (LLMs), but suffers from severe efficiency challenges due to its trial-and-error nature. While the common practice employs supervised fine-tuning (SFT) as a warm-up stage for RL, this decoupled two-stage approach limits interaction between SFT and RL, thereby constraining overall effectiveness. This study introduces a novel method for learning reasoning models that employs bilevel optimization to facilitate better cooperation between these training paradigms. By conditioning the SFT objective on the optimal RL policy, our approach enables SFT to meta-learn how to guide RL's optimization process. During training, the lower level performs RL updates while simultaneously receiving SFT supervision, and the upper level explicitly maximizes the cooperative gain-the performance advantage of joint SFT-RL training over RL alone. Empirical evaluations on five reasoning benchmarks demonstrate that our method consistently outperforms baselines and achieves a better balance between effectiveness and efficiency.
ReSURE: Regularizing Supervision Unreliability for Multi-turn Dialogue Fine-tuning
Aug 27, 2025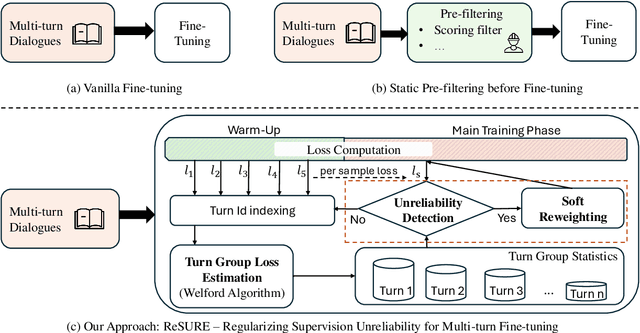
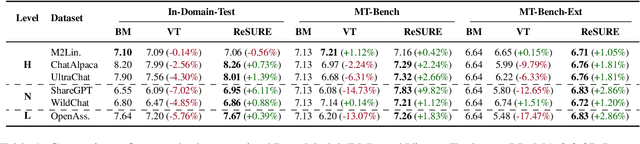
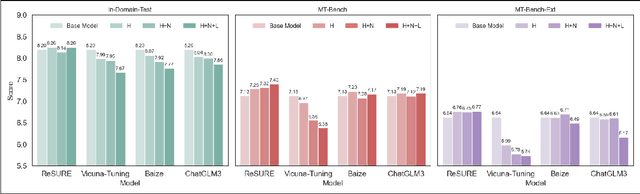
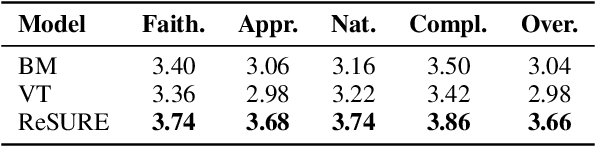
Fine-tuning multi-turn dialogue systems requires high-quality supervision but often suffers from degraded performance when exposed to low-quality data. Supervision errors in early turns can propagate across subsequent turns, undermining coherence and response quality. Existing methods typically address data quality via static prefiltering, which decouples quality control from training and fails to mitigate turn-level error propagation. In this context, we propose ReSURE (Regularizing Supervision UnREliability), an adaptive learning method that dynamically down-weights unreliable supervision without explicit filtering. ReSURE estimates per-turn loss distributions using Welford's online statistics and reweights sample losses on the fly accordingly. Experiments on both single-source and mixed-quality datasets show improved stability and response quality. Notably, ReSURE enjoys positive Spearman correlations (0.21 ~ 1.0 across multiple benchmarks) between response scores and number of samples regardless of data quality, which potentially paves the way for utilizing large-scale data effectively. Code is publicly available at https://github.com/Elvin-Yiming-Du/ReSURE_Multi_Turn_Training.
Vulnerability-Aware Alignment: Mitigating Uneven Forgetting in Harmful Fine-Tuning
Jun 04, 2025Harmful fine-tuning (HFT), performed directly on open-source LLMs or through Fine-tuning-as-a-Service, breaks safety alignment and poses significant threats. Existing methods aim to mitigate HFT risks by learning robust representation on alignment data or making harmful data unlearnable, but they treat each data sample equally, leaving data vulnerability patterns understudied. In this work, we reveal that certain subsets of alignment data are consistently more prone to forgetting during HFT across different fine-tuning tasks. Inspired by these findings, we propose Vulnerability-Aware Alignment (VAA), which estimates data vulnerability, partitions data into "vulnerable" and "invulnerable" groups, and encourages balanced learning using a group distributionally robust optimization (Group DRO) framework. Specifically, VAA learns an adversarial sampler that samples examples from the currently underperforming group and then applies group-dependent adversarial perturbations to the data during training, aiming to encourage a balanced learning process across groups. Experiments across four fine-tuning tasks demonstrate that VAA significantly reduces harmful scores while preserving downstream task performance, outperforming state-of-the-art baselines.
MiniMax-Remover: Taming Bad Noise Helps Video Object Removal
May 30, 2025Recent advances in video diffusion models have driven rapid progress in video editing techniques. However, video object removal, a critical subtask of video editing, remains challenging due to issues such as hallucinated objects and visual artifacts. Furthermore, existing methods often rely on computationally expensive sampling procedures and classifier-free guidance (CFG), resulting in slow inference. To address these limitations, we propose MiniMax-Remover, a novel two-stage video object removal approach. Motivated by the observation that text condition is not best suited for this task, we simplify the pretrained video generation model by removing textual input and cross-attention layers, resulting in a more lightweight and efficient model architecture in the first stage. In the second stage, we distilled our remover on successful videos produced by the stage-1 model and curated by human annotators, using a minimax optimization strategy to further improve editing quality and inference speed. Specifically, the inner maximization identifies adversarial input noise ("bad noise") that makes failure removals, while the outer minimization step trains the model to generate high-quality removal results even under such challenging conditions. As a result, our method achieves a state-of-the-art video object removal results with as few as 6 sampling steps and doesn't rely on CFG, significantly improving inference efficiency. Extensive experiments demonstrate the effectiveness and superiority of MiniMax-Remover compared to existing methods. Codes and Videos are available at: https://minimax-remover.github.io.
Bridging the Long-Term Gap: A Memory-Active Policy for Multi-Session Task-Oriented Dialogue
May 26, 2025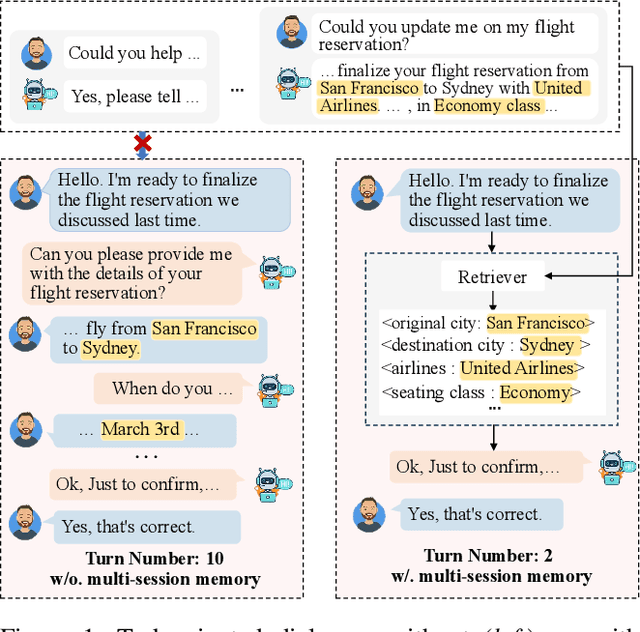
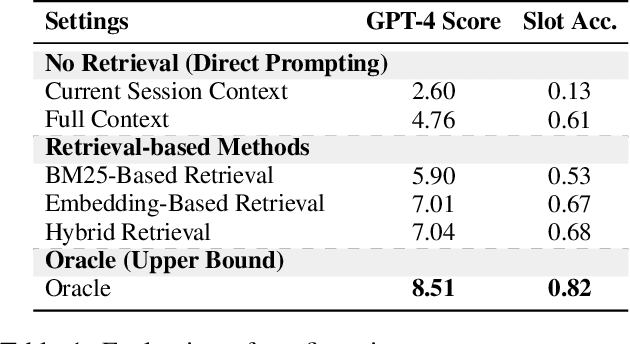
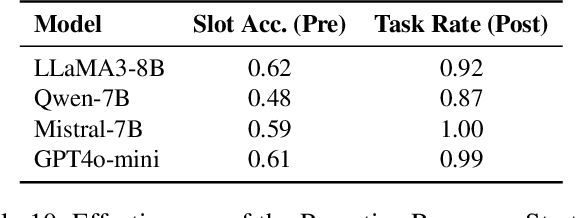
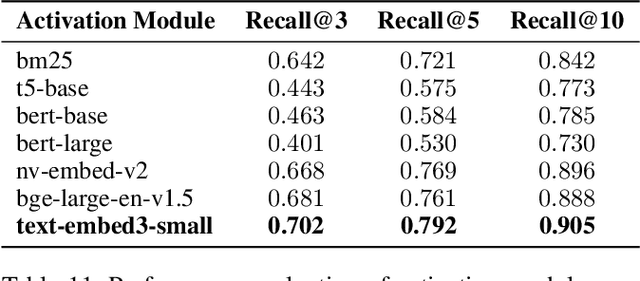
Existing Task-Oriented Dialogue (TOD) systems primarily focus on single-session dialogues, limiting their effectiveness in long-term memory augmentation. To address this challenge, we introduce a MS-TOD dataset, the first multi-session TOD dataset designed to retain long-term memory across sessions, enabling fewer turns and more efficient task completion. This defines a new benchmark task for evaluating long-term memory in multi-session TOD. Based on this new dataset, we propose a Memory-Active Policy (MAP) that improves multi-session dialogue efficiency through a two-stage approach. 1) Memory-Guided Dialogue Planning retrieves intent-aligned history, identifies key QA units via a memory judger, refines them by removing redundant questions, and generates responses based on the reconstructed memory. 2) Proactive Response Strategy detects and correct errors or omissions, ensuring efficient and accurate task completion. We evaluate MAP on MS-TOD dataset, focusing on response quality and effectiveness of the proactive strategy. Experiments on MS-TOD demonstrate that MAP significantly improves task success and turn efficiency in multi-session scenarios, while maintaining competitive performance on conventional single-session tasks.