 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing the Reasoning Economy: A Survey of Efficient Reasoning for Large Language Models
Mar 31, 2025Recent advancements in Large Language Models (LLMs) have significantly enhanced their ability to perform complex reasoning tasks, transitioning from fast and intuitive thinking (System 1) to slow and deep reasoning (System 2). While System 2 reasoning improves task accuracy, it often incurs substantial computational costs due to its slow thinking nature and inefficient or unnecessary reasoning behaviors. In contrast, System 1 reasoning is computationally efficient but leads to suboptimal performance. Consequently, it is critical to balance the trade-off between performance (benefits) and computational costs (budgets), giving rise to the concept of reasoning economy. In this survey, we provide a comprehensive analysis of reasoning economy in both the post-training and test-time inference stages of LLMs, encompassing i) the cause of reasoning inefficiency, ii) behavior analysis of different reasoning patterns, and iii) potential solutions to achieve reasoning economy. By offering actionable insights and highlighting open challenges, we aim to shed light on strategies for improving the reasoning economy of LLMs, thereby serving as a valuable resource for advancing research in this evolving area. We also provide a public repository to continually track developments in this fast-evolving field.
Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
Dec 30, 2024The remarkable performance of models like the OpenAI o1 can be attributed to their ability to emulate human-like long-time thinking during inference. These models employ extended chain-of-thought (CoT) processes, exploring multiple strategies to enhance problem-solving capabilities. However, a critical question remains: How to intelligently and efficiently scale computational resources during testing. This paper presents the first comprehensive study on the prevalent issue of overthinking in these models, where excessive computational resources are allocated for simple problems with minimal benefit. We introduce novel efficiency metrics from both outcome and process perspectives to evaluate the rational use of computational resources by o1-like models. Using a self-training paradigm, we propose strategies to mitigate overthinking, streamlining reasoning processes without compromising accuracy. Experimental results show that our approach successfully reduces computational overhead while preserving model performance across a range of testsets with varying difficulty levels, such as GSM8K, MATH500, GPQA, and AIME.
Anchor-based Large Language Models
Feb 16, 2024Large language models (LLMs) predominantly employ decoder-only transformer architectures, necessitating the retention of keys/values information for historical tokens to provide contextual information and avoid redundant computation. However, the substantial size and parameter volume of these LLMs require massive GPU memory. This memory demand increases with the length of the input text, leading to an urgent need for more efficient methods of information storage and processing. This study introduces Anchor-based LLMs (AnLLMs), which utilize an innovative anchor-based self-attention network (AnSAN) and also an anchor-based inference strategy. This approach enables LLMs to compress sequence information into an anchor token, reducing the keys/values cache and enhancing inference efficiency. Experiments on question-answering benchmarks reveal that AnLLMs maintain similar accuracy levels while achieving up to 99% keys/values cache reduction and up to 3.5 times faster inference. Despite a minor compromise in accuracy, the substantial enhancements of AnLLMs employing the AnSAN technique in resource utilization and computational efficiency underscore their potential for practical LLM applications.
Benchmarking LLMs via Uncertainty Quantification
Jan 23, 2024



The proliferation of open-source Large Language Models (LLMs) from various institutions has highlighted the urgent need for comprehensive evaluation methods. However, current evaluation platforms, such as the widely recognized HuggingFace open LLM leaderboard, neglect a crucial aspect -- uncertainty, which is vital for thoroughly assessing LLMs. To bridge this gap, we introduce a new benchmarking approach for LLMs that integrates uncertainty quantification. Our examination involves eight LLMs (LLM series) spanning five representative natural language processing tasks. Additionally, we introduce an uncertainty-aware evaluation metric, UAcc, which takes into account both prediction accuracy and prediction uncertainty. Our findings reveal that: I) LLMs with higher accuracy may exhibit lower certainty; II) Larger-scale LLMs may display greater uncertainty compared to their smaller counterparts; and III) Instruction-finetuning tends to increase the uncertainty of LLMs. By taking uncertainty into account, our new UAcc metric can either amplify or diminish the relative improvement of one LLM over another and may even change the relative ranking of two LLMs. These results underscore the significance of incorporating uncertainty in the evaluation of LLMs.
Salute the Classic: Revisiting Challenges of Machine Translation in the Age of Large Language Models
Jan 17, 2024
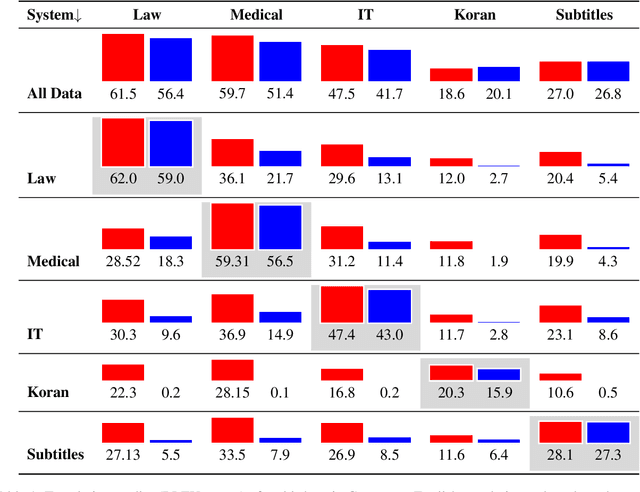

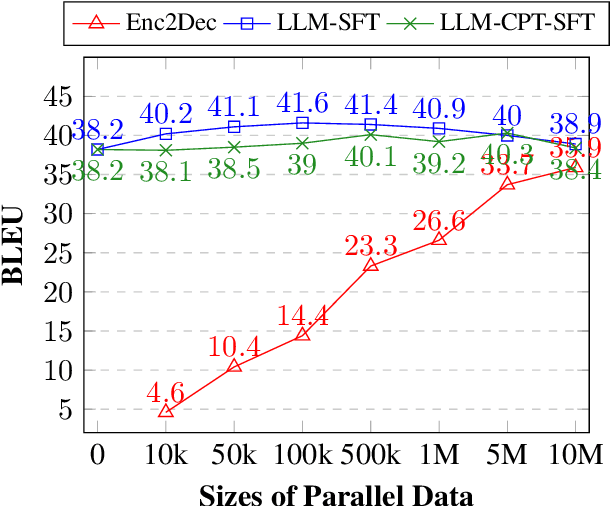
The evolution of Neural Machine Translation (NMT) has been significantly influenced by six core challenges (Koehn and Knowles, 2017), which have acted as benchmarks for progress in this field. This study revisits these challenges, offering insights into their ongoing relevance in the context of advanced Large Language Models (LLMs): domain mismatch, amount of parallel data, rare word prediction, translation of long sentences, attention model as word alignment, and sub-optimal beam search. Our empirical findings indicate that LLMs effectively lessen the reliance on parallel data for major languages in the pretraining phase. Additionally, the LLM-based translation system significantly enhances the translation of long sentences that contain approximately 80 words and shows the capability to translate documents of up to 512 words. However, despite these significant improvements, the challenges of domain mismatch and prediction of rare words persist. While the challenges of word alignment and beam search, specifically associated with NMT, may not apply to LLMs, we identify three new challenges for LLMs in translation tasks: inference efficiency, translation of low-resource languages in the pretraining phase, and human-aligned evaluation. The datasets and models are released at https://github.com/pangjh3/LLM4MT.