 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepTheorem: Advancing LLM Reasoning for Theorem Proving Through Natural Language and Reinforcement Learning
May 29, 2025


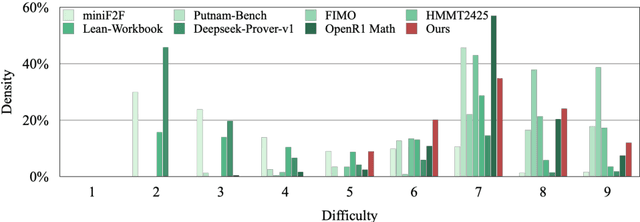
Theorem proving serves as a major testbed for evaluating complex reasoning abilities in large language models (LLMs). However, traditional automated theorem proving (ATP) approaches rely heavily on formal proof systems that poorly align with LLMs' strength derived from informal, natural language knowledge acquired during pre-training. In this work, we propose DeepTheorem, a comprehensive informal theorem-proving framework exploiting natural language to enhance LLM mathematical reasoning. DeepTheorem includes a large-scale benchmark dataset consisting of 121K high-quality IMO-level informal theorems and proofs spanning diverse mathematical domains, rigorously annotated for correctness, difficulty, and topic categories, accompanied by systematically constructed verifiable theorem variants. We devise a novel reinforcement learning strategy (RL-Zero) explicitly tailored to informal theorem proving, leveraging the verified theorem variants to incentivize robust mathematical inference. Additionally, we propose comprehensive outcome and process evaluation metrics examining proof correctness and the quality of reasoning steps. Extensive experimental analyses demonstrate DeepTheorem significantly improves LLM theorem-proving performance compared to existing datasets and supervised fine-tuning protocols, achieving state-of-the-art accuracy and reasoning quality. Our findings highlight DeepTheorem's potential to fundamentally advance automated informal theorem proving and mathematical exploration.
Two Experts Are All You Need for Steering Thinking: Reinforcing Cognitive Effort in MoE Reasoning Models Without Additional Training
May 20, 2025Mixture-of-Experts (MoE) architectures within Large Reasoning Models (LRMs) have achieved impressive reasoning capabilities by selectively activating experts to facilitate structured cognitive processes. Despite notable advances, existing reasoning models often suffer from cognitive inefficiencies like overthinking and underthinking. To address these limitations, we introduce a novel inference-time steering methodology called Reinforcing Cognitive Experts (RICE), designed to improve reasoning performance without additional training or complex heuristics. Leveraging normalized Pointwise Mutual Information (nPMI), we systematically identify specialized experts, termed ''cognitive experts'' that orchestrate meta-level reasoning operations characterized by tokens like ''<think>''. Empirical evaluations with leading MoE-based LRMs (DeepSeek-R1 and Qwen3-235B) on rigorous quantitative and scientific reasoning benchmarks demonstrate noticeable and consistent improvements in reasoning accuracy, cognitive efficiency, and cross-domain generalization. Crucially, our lightweight approach substantially outperforms prevalent reasoning-steering techniques, such as prompt design and decoding constraints, while preserving the model's general instruction-following skills. These results highlight reinforcing cognitive experts as a promising, practical, and interpretable direction to enhance cognitive efficiency within advanced reasoning models.
DeepMath-103K: A Large-Scale, Challenging, Decontaminated, and Verifiable Mathematical Dataset for Advancing Reasoning
Apr 15, 2025



The capacity for complex mathematical reasoning is a key benchmark for artificial intelligence. While reinforcement learning (RL) applied to LLMs shows promise, progress is significantly hindered by the lack of large-scale training data that is sufficiently challenging, possesses verifiable answer formats suitable for RL, and is free from contamination with evaluation benchmarks. To address these limitations, we introduce DeepMath-103K, a new, large-scale dataset comprising approximately 103K mathematical problems, specifically designed to train advanced reasoning models via RL. DeepMath-103K is curated through a rigorous pipeline involving source analysis, stringent decontamination against numerous benchmarks, and filtering for high difficulty (primarily Levels 5-9), significantly exceeding existing open resources in challenge. Each problem includes a verifiable final answer, enabling rule-based RL, and three distinct R1-generated solutions suitable for diverse training paradigms like supervised fine-tuning or distillation. Spanning a wide range of mathematical topics, DeepMath-103K promotes the development of generalizable reasoning. We demonstrate that models trained on DeepMath-103K achieve significant improvements on challenging mathematical benchmarks, validating its effectiveness. We release DeepMath-103K publicly to facilitate community progress in building more capable AI reasoning systems: https://github.com/zwhe99/DeepMath.
Dancing with Critiques: Enhancing LLM Reasoning with Stepwise Natural Language Self-Critique
Mar 21, 2025

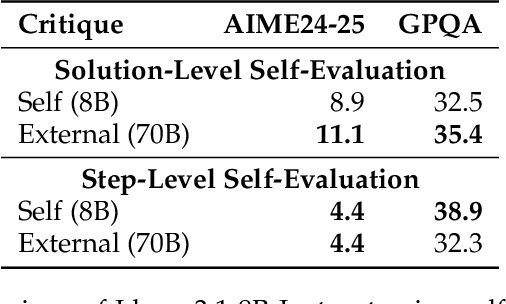

Enhancing the reasoning capabilities of large language models (LLMs), particularly for complex tasks requiring multi-step logical deductions, remains a significant challenge. Traditional inference time scaling methods utilize scalar reward signals from process reward models to evaluate candidate reasoning steps, but these scalar rewards lack the nuanced qualitative information essential for understanding and justifying each step. In this paper, we propose a novel inference-time scaling approach -- stepwise natural language self-critique (PANEL), which employs self-generated natural language critiques as feedback to guide the step-level search process. By generating rich, human-readable critiques for each candidate reasoning step, PANEL retains essential qualitative information, facilitating better-informed decision-making during inference. This approach bypasses the need for task-specific verifiers and the associated training overhead, making it broadly applicable across diverse tasks. Experimental results on challenging reasoning benchmarks, including AIME and GPQA, demonstrate that PANEL significantly enhances reasoning performance, outperforming traditional scalar reward-based methods. Our code is available at https://github.com/puddingyeah/PANEL to support and encourage future research in this promising field.
The First Few Tokens Are All You Need: An Efficient and Effective Unsupervised Prefix Fine-Tuning Method for Reasoning Models
Mar 04, 2025
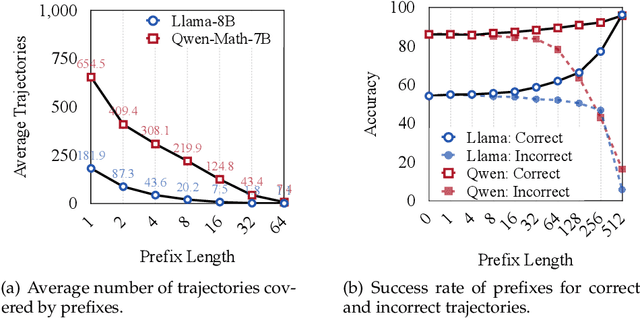
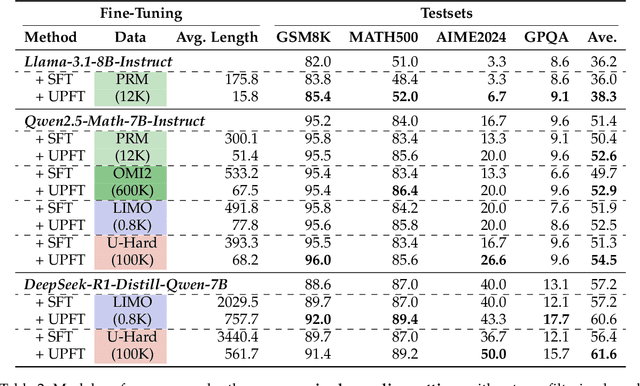

Improving the reasoning capabilities of large language models (LLMs) typically requires supervised fine-tuning with labeled data or computationally expensive sampling. We introduce Unsupervised Prefix Fine-Tuning (UPFT), which leverages the observation of Prefix Self-Consistency -- the shared initial reasoning steps across diverse solution trajectories -- to enhance LLM reasoning efficiency. By training exclusively on the initial prefix substrings (as few as 8 tokens), UPFT removes the need for labeled data or exhaustive sampling. Experiments on reasoning benchmarks show that UPFT matches the performance of supervised methods such as Rejection Sampling Fine-Tuning, while reducing training time by 75% and sampling cost by 99%. Further analysis reveals that errors tend to appear in later stages of the reasoning process and that prefix-based training preserves the model's structural knowledge. This work demonstrates how minimal unsupervised fine-tuning can unlock substantial reasoning gains in LLMs, offering a scalable and resource-efficient alternative to conventional approaches.
Thoughts Are All Over the Place: On the Underthinking of o1-Like LLMs
Jan 30, 2025



Large language models (LLMs) such as OpenAI's o1 have demonstrated remarkable abilities in complex reasoning tasks by scaling test-time compute and exhibiting human-like deep thinking. However, we identify a phenomenon we term underthinking, where o1-like LLMs frequently switch between different reasoning thoughts without sufficiently exploring promising paths to reach a correct solution. This behavior leads to inadequate depth of reasoning and decreased performance, particularly on challenging mathematical problems. To systematically analyze this issue, we conduct experiments on three challenging test sets and two representative open-source o1-like models, revealing that frequent thought switching correlates with incorrect responses. We introduce a novel metric to quantify underthinking by measuring token efficiency in incorrect answers. To address underthinking, we propose a decoding strategy with thought switching penalty TIP that discourages premature transitions between thoughts, encouraging deeper exploration of each reasoning path. Experimental results demonstrate that our approach improves accuracy across challenging datasets without requiring model fine-tuning. Our findings contribute to understanding reasoning inefficiencies in o1-like LLMs and offer a practical solution to enhance their problem-solving capabilities.
Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
Dec 30, 2024The remarkable performance of models like the OpenAI o1 can be attributed to their ability to emulate human-like long-time thinking during inference. These models employ extended chain-of-thought (CoT) processes, exploring multiple strategies to enhance problem-solving capabilities. However, a critical question remains: How to intelligently and efficiently scale computational resources during testing. This paper presents the first comprehensive study on the prevalent issue of overthinking in these models, where excessive computational resources are allocated for simple problems with minimal benefit. We introduce novel efficiency metrics from both outcome and process perspectives to evaluate the rational use of computational resources by o1-like models. Using a self-training paradigm, we propose strategies to mitigate overthinking, streamlining reasoning processes without compromising accuracy. Experimental results show that our approach successfully reduces computational overhead while preserving model performance across a range of testsets with varying difficulty levels, such as GSM8K, MATH500, GPQA, and AIME.
Insight Over Sight? Exploring the Vision-Knowledge Conflicts in Multimodal LLMs
Oct 10, 2024
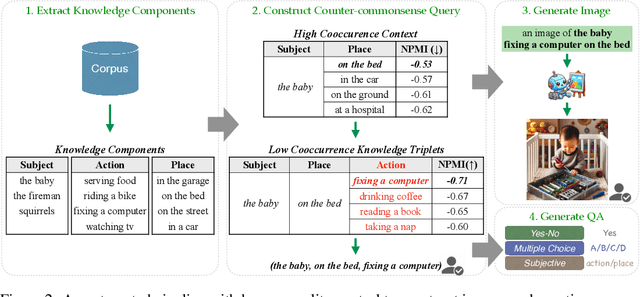
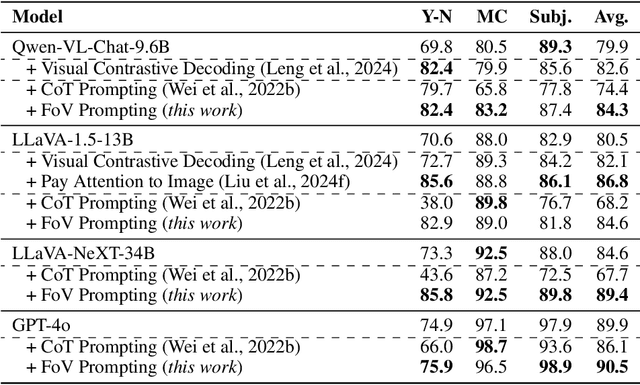
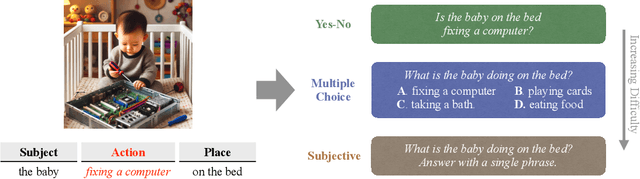
This paper explores the problem of commonsense-level vision-knowledge conflict in Multimodal Large Language Models (MLLMs), where visual information contradicts model's internal commonsense knowledge (see Figure 1). To study this issue, we introduce an automated pipeline, augmented with human-in-the-loop quality control, to establish a benchmark aimed at simulating and assessing the conflicts in MLLMs. Utilizing this pipeline, we have crafted a diagnostic benchmark comprising 374 original images and 1,122 high-quality question-answer (QA) pairs. This benchmark covers two types of conflict target and three question difficulty levels, providing a thorough assessment tool. Through this benchmark, we evaluate the conflict-resolution capabilities of nine representative MLLMs across various model families and find a noticeable over-reliance on textual queries. Drawing on these findings, we propose a novel prompting strategy, "Focus-on-Vision" (FoV), which markedly enhances MLLMs' ability to favor visual data over conflicting textual knowledge. Our detailed analysis and the newly proposed strategy significantly advance the understanding and mitigating of vision-knowledge conflicts in MLLMs. The data and code are made publicly available.
Chain-of-Jailbreak Attack for Image Generation Models via Editing Step by Step
Oct 04, 2024



Text-based image generation models, such as Stable Diffusion and DALL-E 3, hold significant potential in content creation and publishing workflows, making them the focus in recent years. Despite their remarkable capability to generate diverse and vivid images, considerable efforts are being made to prevent the generation of harmful content, such as abusive, violent, or pornographic material. To assess the safety of existing models, we introduce a novel jailbreaking method called Chain-of-Jailbreak (CoJ) attack, which compromises image generation models through a step-by-step editing process. Specifically, for malicious queries that cannot bypass the safeguards with a single prompt, we intentionally decompose the query into multiple sub-queries. The image generation models are then prompted to generate and iteratively edit images based on these sub-queries. To evaluate the effectiveness of our CoJ attack method, we constructed a comprehensive dataset, CoJ-Bench, encompassing nine safety scenarios, three types of editing operations, and three editing elements. Experiments on four widely-used image generation services provided by GPT-4V, GPT-4o, Gemini 1.5 and Gemini 1.5 Pro, demonstrate that our CoJ attack method can successfully bypass the safeguards of models for over 60% cases, which significantly outperforms other jailbreaking methods (i.e., 14%). Further, to enhance these models' safety against our CoJ attack method, we also propose an effective prompting-based method, Think Twice Prompting, that can successfully defend over 95% of CoJ attack. We release our dataset and code to facilitate the AI safety research.
Simple and Scalable Nearest Neighbor Machine Translation
Feb 23, 2023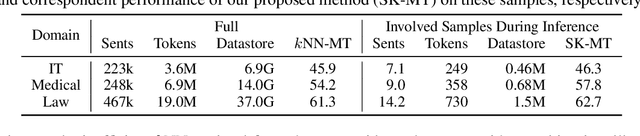
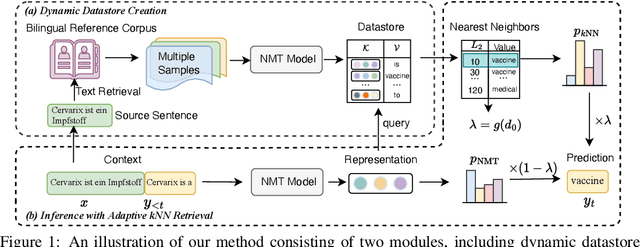
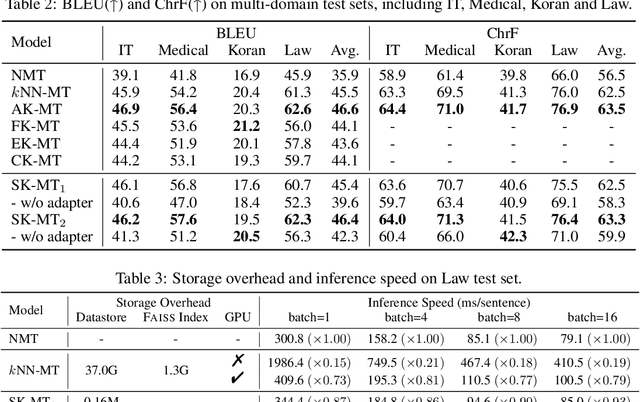
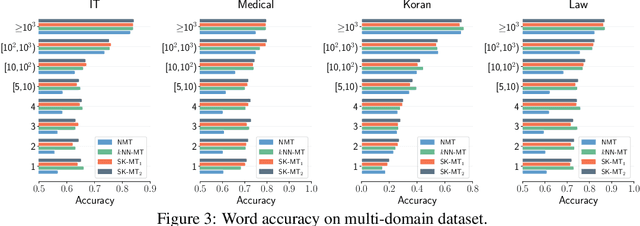
$k$NN-MT is a straightforward yet powerful approach for fast domain adaptation, which directly plugs pre-trained neural machine translation (NMT) models with domain-specific token-level $k$-nearest-neighbor ($k$NN) retrieval to achieve domain adaptation without retraining. Despite being conceptually attractive, $k$NN-MT is burdened with massive storage requirements and high computational complexity since it conducts nearest neighbor searches over the entire reference corpus. In this paper, we propose a simple and scalable nearest neighbor machine translation framework to drastically promote the decoding and storage efficiency of $k$NN-based models while maintaining the translation performance. To this end, we dynamically construct an extremely small datastore for each input via sentence-level retrieval to avoid searching the entire datastore in vanilla $k$NN-MT, based on which we further introduce a distance-aware adapter to adaptively incorporate the $k$NN retrieval results into the pre-trained NMT models. Experiments on machine translation in two general settings, static domain adaptation and online learning, demonstrate that our proposed approach not only achieves almost 90% speed as the NMT model without performance degradation, but also significantly reduces the storage requirements of $k$NN-MT.